点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者:纳米酱 链接:https://zhuanlan.zhihu.com/p/22067439 来源:知乎
博士一把年纪,理论物理已经没心读下去了,不知廉耻来知乎卖萌,还是深度学习卖萌,才转行半年多就敢出来卖,好羞耻呀~喵~
目前本萌关注深度学习方面的机理和优化,转行时间不长,水平一般,一直知乎隐性埋名当安静的萌喵,相对各位科班白美,富帅作目标检测,视频分析,NLP等好玩的,有钱拿的,KPI导向型的。本萌目前的研究仍然缺乏工程属性(没钱刷ImageNet),而且毫无竞争力可言(HR说,博士发不出ML文章给本科生待遇。。。),苦逼只能给个知乎文章水一水情怀。
好了开始正经的讨论,话说优化这个坑,本萌并不打算钻研各类大规模机器学习优化问题,或者数值优化算法,本萌只关心非常深的网络的优化问题。针对此类问题,本萌打心里觉得,网络结构+数据才是王道,至于各种数值优化算法,本来就不是针对深度,宽度学习也可,用用只是锦上添花。下面开始本萌的叨絮:
机理,目前一个旋绕在机器学习学术界的心头大恨便是:为何深度学习work。话说一些大佬目前仍对深度学习嗤之以鼻,主要嫌弃其过分黑箱,trick过多,我由此想起施温格总是鄙视费曼发明的费曼图,称其为trick,私下却偷偷用费曼图算东西。。。。然而,深度学习碾压性的成就是有目共睹的。
说到碾压,我们不得不提特征。早期特征完全是local的,说白了就是找一个函数,”渲染“训练数据某个点的紧邻,从而获得“模糊化”的映射,然后灌入分类器当中。而到了神经网络,可以说是同认知科学的联系最紧密的模型,没有之一。有认为到了深度学习,特征都是分布式的,每个特征反映到神经网络上的feature map都会有重叠,与此相比,认知方面的grandmother cell换到深度学习上,有人验证了是少数几个神经元司管一些特征,实际上并不重叠。好玩的是,这些方法都高度依赖如何提取网络学到的东西,就是说啥是特征?话说真实情况下,grandmother cell是需要前面几层的distributed表示来作为辅助呀,才有后面特征的稀疏响应呀。本萌觉得,深度学习同认知方面的绑定基本都是情怀满满的研究,老实说,实在不想跟进。
另外关于每层的映射,大家熟悉的映射是CNN这类共享权重的映射,共享权重能有效压低宽度,把力量集中到深度上。当然也可以换成其他映射,比如散射变换等,这些映射本身都充分考虑了平移旋转的对称性质。如果说,深度学习就是俄罗斯套娃,每层的娃娃应该是啥,目前仍然没人知道。
优化,本萌会将GD类型优化放到后面说,这里只说一些宏观一点的。
我们知道second order optimization在神经网络训练中表现不错,一来因为神经网络是鞍点数目主导的模型。理论上,影响训练效率完全取决于鞍点的不稳定性和数目。其次,包含大量局部优的下,磨平二次导数(除掉它)并有效聚合路径的发散,就是说如何将每次优化理解成一个产生模型的过程,不同优化路径就是不同模型。如果每次训练都大致跑相同的优化“通道”,其model variance的减少有助于压制过拟,提高泛化。然而,现实上近似二次导数也即hessian矩阵是件相当头疼的事情。况且,对于超深的网络,光靠这些优化也没法解决所谓的degradation问题。这些问题,直到高速网络,残差网络这类打捷径的结构出现才转机。
另外是关于贝叶斯网络的优化,我们知道unsupervised里面会有一些generative model,就是说,我没有数据标签,没法搞discriminative类型的,但是我能拟合数据分布。要拟合分布,就要搞出一个分布,比如各种贝叶斯方法。由于归一化要求,我们选的分布中的隐变量需要求和掉,导致训练参数会包含到归一化因子当中。现实求这个归一化因子是相当困难的,需要作各种近似,比如高斯近似就能求出归一因子。然而更加复杂的比如玻尔兹曼机器,就需要采样去计算求和了。有趣的是,目前这个状况有了很大转机,便是对抗学习技术。对抗学习实际上是用一个discriminative的网络训练一个generative网络,generative就是不断给discriminative的网络提供数据的,discriminative的输出就是告诉你数据来自从训练样本,还是generative产生的,假设discriminative已经无法判别来自那里,我们便认为generative产生的样本同训练样本重合,整个过程不同作任何 marginal distribution的计算。好比一个不知道价钱的主持人(generative model)让一个经验丰富的猜价者(discriminative model)猜某个商品价格,开始的时候,主持人只能是瞎说对方猜高或者猜低,假设猜价者是强势型的(受主持人干扰影响小),不断猜下去,猜价者都无法判别主持人是否是诓他的时候,这时,主持人已经能够通过猜价者的一系列反应推断出物品的价格合理范围。然而,这个方法的风险在于,现实上主持人可能气场过强,严重干扰猜价者的判断力,导致不会收敛。
超深网络,然后问题就来了,为何要搞那么深。我们知道极深网络一层套一层那么多recursion,GPU这种处理器其实并不是非常适合。传统理解是模型的容度问题,俗话说深不可测,没人说宽不可测。可是回到数学上,要模型容度高,随便几层超宽网络也能做到这一点。其实,容度并不重要,关键是优化上的问题,有人给了一个证据,他们计算了鞍点还有局部优的数目(通称critical point)随网络规模的变化,人们发现critical point的数目正比于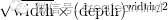
,增加宽度带来的局部优是指数暴涨的,相比之下,增加深度带来的局部优增长却缓慢多了。我们知道局部优过多会有过拟合的风险,加深换取容度比加宽换取容度,理论上更加经济,过拟风险更低。同时,按照这个理论,极深网络的性能瓶颈很可能不在于过拟合上。这样,欢天喜地的,深度学习就是要深。(这不废话呀~喵喵喵!)
degradation问题。degradation是指非常深的网络性能反而比浅一点的网络差,而且越深越差,这并不符合我们加深的初衷。残差网络的出现,有效改变了这一现状。大家直观上都认为残差,或者其同时期的论文highway network,都打条捷径导引梯度流回到更加前面的一层,这样底层更能有效地学习,这样网络就不怎样深了。然而,依靠这种思想完全可以设计出一种带有捷径,但是效果巨差的网络,比如每个残差block当中,两个CNN层做一个基于feature-map的element-wise summation 然后才加到identity mapping上。本萌猜测打捷径的想法可能有点过分表面。另外,残差或者高速有个问题就是diminishing feature,梯度回流过程可能跳过block内部的weight layer,这样有些block其实没有接受什么训练,导致不同的block有可能啥也不学,或者学了差不多一样的东西。而残差改进版本stochastic depth网络可以部分回避这种问题,通过随机强制关闭部分block的weight layers,迫使其它block对训练数据做出新的调整,可以理解成dropout技术用到layer上(好像stochastic depth network作者在知乎蛰伏着,本萌要是说错了,可以来请我喝茶)。
残差网络之后,可以说各种带捷径的网络雨后春笋般出现。比较有趣的设计如deeply fused network,fractal network,resnet in resnet/wide residual networks ,resnet of resnet 。第一个基本是多个不同深度的网络的直接并起来。第二个相当有趣,其不再是利用残差---也就是不加上identity mapping这个输入了,其设计的网络原则有1-N的任意深度(难怪叫分形),训练需要挑一个从数据到loss layer的图路径去优化。第三个有两个,都走了加宽残差block的道路,感觉何凯明整个文章只讨论要减少参数作瓶颈宽度的研究,完全留的一手加宽会怎样的后路给其他人呀,才明白学术上的ex(tra)-cited(亦可赛艇)就是这样来的。关于最后一个网络,一条捷径不够,block和block之间又搭了捷径。。。
杂七杂八的难点,下面一一列举,其实有些困难并非人们口述那样可怕。
梯度衰减,通常各大门户都说是梯度衰减,梯度消失好严重呀~发现不少人理解梯度衰减,是觉得优化跑不动(loss不再下降)。本萌想说,梯度衰减只是跑得慢,跑不动另有原因。为何呢?其实各位做下实验,底层梯度的强度是在1e-6到1e-9量级,加深后更低。搞工程的人说这个梯度小,有点忽略了维度扩展。我们考虑一个半径1e-9的2000维球,包围的体积绝对碾压半径为1的10维球,就是说哪怕这么小的梯度,高维后一步也能覆盖超大的空间,更不要提我们还是batch训练,一个回合更新几万次。而且数据量N剧增的情况下,标准化后,半径为1的D维球中数据点之间的平均距离为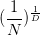
,这一步已经够weight layer的bias来回访问紧邻数据点多次。梯度强度这东西,前期搞得大大的用来翻山越岭可以理解,后期还搞减少学习率搞退火,这时候还理解梯度衰减为跑不动,语意上岂不是矛盾吗?其实,本萌想说,梯度衰减是下面提到的祸根。
顶层过拟,实际上这才是真正严重的呀~。我们知道深度网络依靠前面几层提取特征,然后映射给后面的分类器。一个不慎,底层瞎学到的噪声都传到了顶层,分类器一旦过拟到这些噪声上。回传的梯度流或者太小(奥义。真梯度衰减),或者根本不是正路,根本没法进一步更新底层的特征,导致所谓下梁不正上梁歪,上梁歪了下梁弯,下梁弯了就。。。当然很多方法回避之,一种有效的方法便是作deeply supervised network(DSN),思想很粗暴,把网络分成几块,每块都额外接分类器,这样能让梯度加速回流底层,充分学习重要特征。不过也可以看到,DSN在不同块上的loss是加的形式,而且回流的梯度会和其他地方的梯度流汇合成一条道,假设两个梯度流方向不一致,加形式的梯度流就会有trade off。
Covariance shift和whitening,whitening对于优化的影响工作很多。早期认为在一个几何上近球形分布的数据下,LR类型的损失函数优化更加轻松,whitening在数据伸展axis的标准化,近似将分布拉成球。而沿着数据流的axis进行的whitening,就是batch-normalization了。不仅BN,还有PReLU都用来部分治疗covariance shift这个问题,然而PReLU至多算个trick,继续讨论意义不大。对于BN,本萌觉得背后更深层次的还没被说出来。话说有人将BN放到基于fisher information的optimization框架下看待,认为BN不外乎近似将fisher信息度规非对角元去的更少。我们知道欧式度规是没有非对角元的,换句话说,直线便是连接两点的最短几何体,对应于平坦空间。而去掉或者弱化非对角元这种基于流形空间平坦化的技巧,对于学习优化的提速是非常明显的。
各种优化的进展,比如传统的GD优化,你走多少步,就有多好,其误差的bound是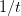 t是步数。到了SGD,是醉汉行走,你走了2步,可能回折一步,有效步数为1步,按照扩散理论估计出来的有效行走距离 L
t是步数。到了SGD,是醉汉行走,你走了2步,可能回折一步,有效步数为1步,按照扩散理论估计出来的有效行走距离 L
和行走次数 t 是  , 所以达到相同精度需要更多步数,bound大致是
, 所以达到相同精度需要更多步数,bound大致是 (实际下界还会依赖函数convex的属性)。目前也能够控制SGD的bound到
(实际下界还会依赖函数convex的属性)。目前也能够控制SGD的bound到
收敛。然而,不管怎样说,GD类型的优化是landscape依赖的,不是数据分布依赖的。什么叫landscape依赖的,打个比方说,你在山上,要到海边,然而你畏惧地形,选了一条拐来拐去的路。换到度规上来说,丧失数据流形的导向,前景充满未知的优化只能选择局部和贪心类型的,没法沿着全局测地线狂奔。而数据分布依赖的优化是靠fisher information,fisher information规定了一种保分布优化,目标一直在,从山上到海边不再是按照局部梯度方向,而是按照类似测地线的方式行走
各种激活函数的选择,目前来看,具有开关形的激活函数能有效的导引梯度回流。比如maxout,还有APL这种多线段插值型的激活函数。前者只让多个输入的最大输出,后者会加入训练参数,选择合适的scale输出。一般来说,激活函数尽量不能太多非线性,并且需要通过零点保证输出期望不会漂移,而且激活函数导数为常数甚佳。不过考虑maxout能模拟任意形状的激活函数,自然二次函数也能模拟。而且在APL插值激活函数里面也看得出来,训练好的网络,凸形状的激活函数似乎是占有非常高比例的,二次函数就是凸的。于是,本萌曾经试过一种参数化,且两端被强行饱和掉的二次函数型激活函数(其实本萌这个激活函数原先是从物理上的重整化理论导出的,参数其实是就是跑动耦合常数,由于太过不接地气,被一个业界大牛骂的狗血淋头,一直没敢水)。不考虑特征变成啥,只看分类性能,该激活函数能在优化效率和性能上碾压了目前本萌知道的所有激活(prelu,elu等)。还有不少激活函数考虑了饱和问题,自动添加一些噪声将梯度轰出饱和区等就不一而足了。
======================================================================
好了,扯了那么多泛泛的东西,下面给出本萌的一些观点,本萌打算从网络的一些拓扑指标来衡量一个网络的性能,妥妥地走网络分类路线。既然是分类,那么就要搞特征啦。目前,本萌给的网络特征是如下几个:
...................
更多请阅读原文查看原文章
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),
请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~













