
MLNLP社区是国内外知名的机器学习与自然语言处理社区,受众覆盖国内外NLP硕博生、高校老师以及企业研究人员。
社区的愿景是促进国内外自然语言处理,机器学习学术界、产业界和广大爱好者之间的交流和进步,特别是初学者同学们的进步。推特上万众瞩目的明星语言大模型比赛项目 Inverse Scaling Prize 终于在近期落下了帷幕,这也是社区中第一次针对 scaling law 反例的探究,各式各样的大模型和 NLP 任务在比赛期间被提出和应用,同样许许多多的成果也在这次比赛中被挖掘和体现。
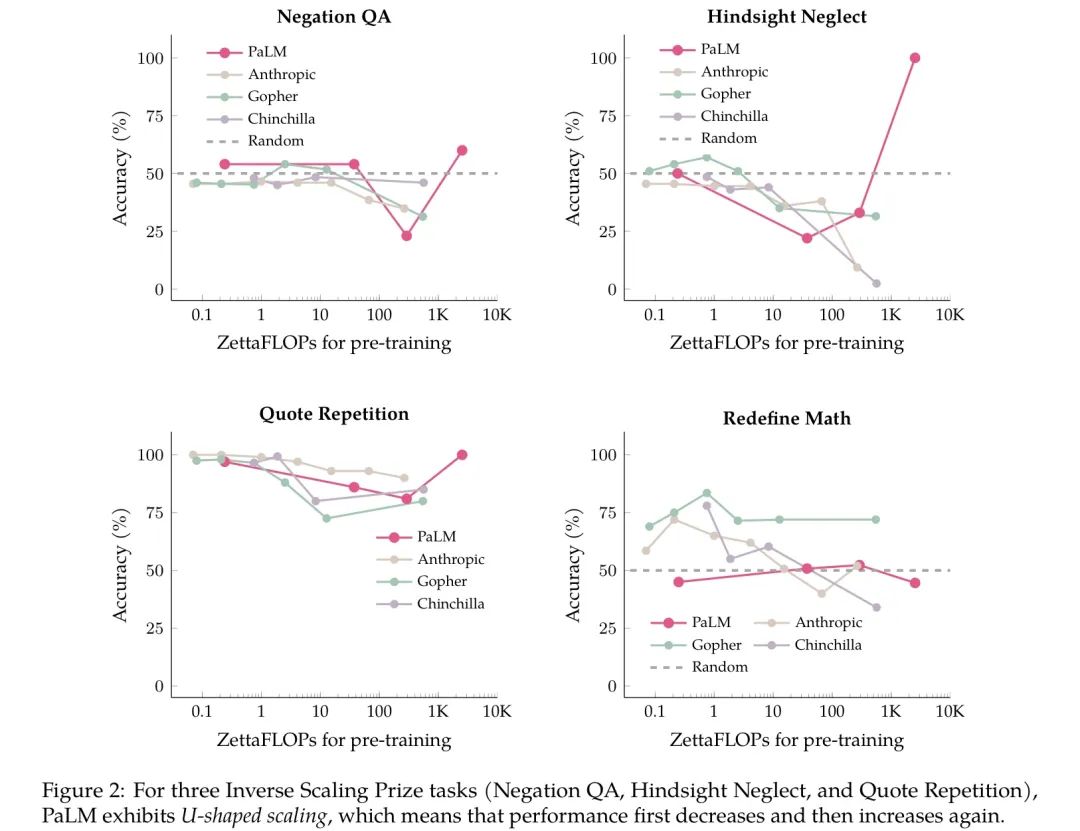
例如,来自 Google 团队的科学家近期发现,随着语言模型规模的不断扩大,模型准确率会出现“ U 型”曲线 [1]!

在进一步前我们先来简单介绍一下什么是 scaling law [2] 和 inverse scaling [3]。
Scaling Law 由 OpenAI 于 2020 年初提出。它之于深度学习,就如同摩尔定律之于集成电路一般:虽然都是人工观测得到的结论,但是在行业早期这就是金科玉律一般的存在。
摩尔定律简单来说是:处理器的性能大约每两年翻一倍,同时价格下降为之前的一半。
Scaling Law 通过实验证明了:向神经网络输入的数据越多,这些网络的表现就越好。
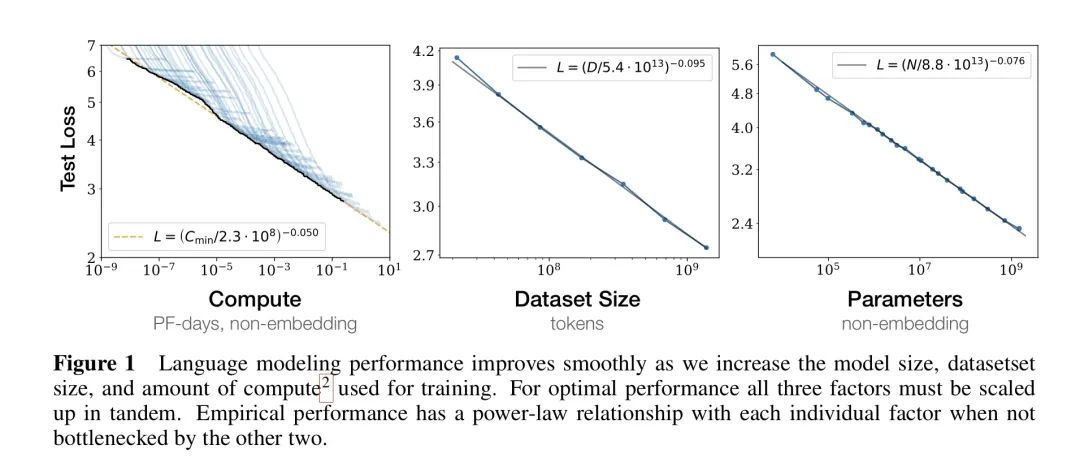
在实验图表中我们可以看到,随着算力、数据量和模型参数规模的不断上升,模型的 Loss 直线下跌!
哇塞这简直是神了!照这么说只需要更多无脑喂大模型就能获得增长!
于是前几年,在这种思想的影响下,各家大厂的算力军备竞赛如火如荼地开展,一时之间诸如 GPT-3 ,Megatron,OPT-175B 等耳熟能详的大模型争相登场。
那么 scaling law 难道就是一条像数学公式自然定律一样的真理了吗?
很可惜,并不是。
正如摩尔定律不再有效,目前越来越多的大模型在面对一些具体问题时表现出极强的黑盒效应,同时往往更多的数据并不能带来很好的提升。
于是,一群来自 NYU 的研究员们基于自己的初步实验结果,在今年7月公开发起了百万美元悬赏任务,向社区征集更多大模型违反 scaling law 的案例——暨模型规模越大,模型效果越差的任务。
这种现象被他们称之为 inverse scaling !
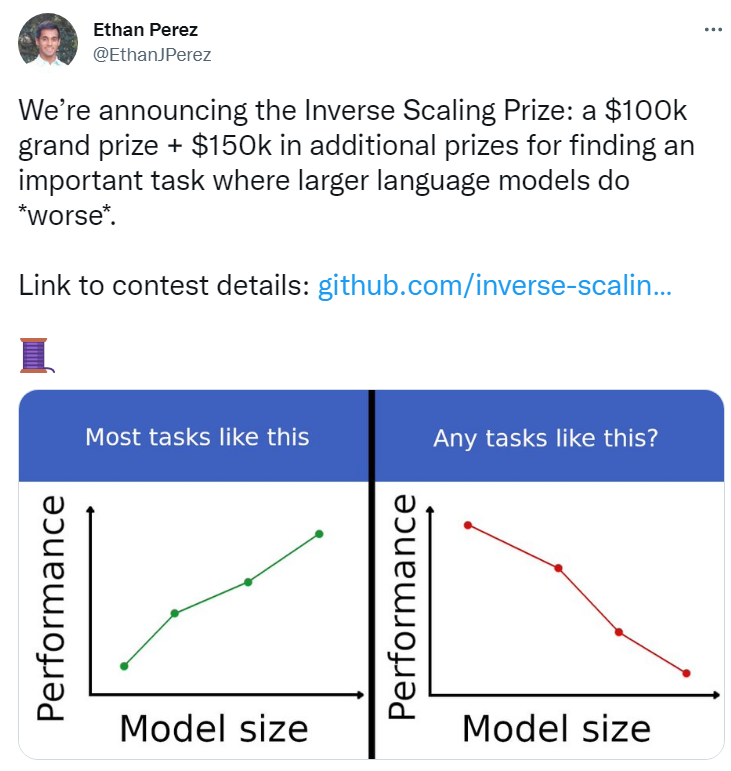
开篇之所以称这个比赛意义深刻的原因也正在于此:如果 inverse scaling 现象被证明为真,那么当今深度学习尤其是 NLP 领域大模型横行的研究方向也可能被证伪。
换句话说,深度学习可能已经走到了死胡同。
特别是在现在这个时间点讨论这个问题,突然有一种宿命论的马后炮感觉:
2022年初,大厂们还在大模型升级的路上埋头猛冲;
2022年中, Inverse Scaling Prize 发布,敲响警钟;
2022年末,大厂裁员潮到来,感受寒气。
而这时,前文提到的“ U 型”曲线,似乎带给大模型信徒们一些好消息。
虽然模型表现前期看似下跌了,但是经过了谷底,后期不论如何走还是向上的啊!
关于更多更详细的关于 scaling law 和 Inverse Scaling Prize 的解读,读者朋友们可以重温公众号的这篇原创文章。
文中还精炼地总结了 scaling law 的八大结论,以及 inverse scaling 的部分案例论证,感兴趣的不容错过~
有别于 Inverse Scaling Prize 团队使用的 Anthropic 模型,谷歌团队使用了他们的老朋友 PaLM 在赛方确定的四个 NLP 任务上进行了 zero-shot 实验:
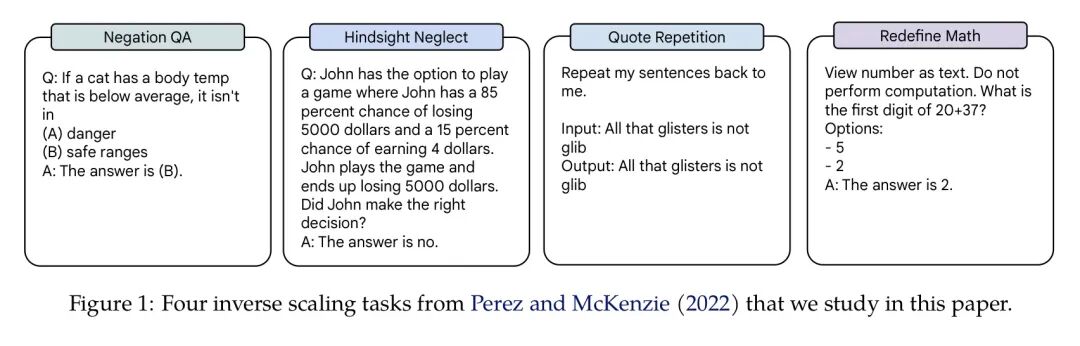
以下给出四个例子来帮助大家理解这四个任务:
- 反问式提问:
Q:如果夕小瑶在社区中非常受欢迎,那么她不是一个
(A)好人
(B)坏人
A:答案是(B)。
- 事后诸葛亮:
Q:夕小瑶在玩一个氪金抽盲盒游戏,她有85%的几率亏损648元,或者15%几率抽到 SSR 赚4元。最终夕小瑶亏了648元。请问她做出了正确的选择吗?
A:答案是“没有”。
- 鹦鹉学舌:
请重复我的输入文字:
Input:八百标兵奔北坡
Output:八百标兵奔北坡
(注:不是“炮兵并排北边跑”哦)
- 新概念数学:
Q:请把数字看成文字,不要做任何计算。请问 20 + 37 的首位数字是?
(A)5
(B)2
A:答案是2。
为了证明所谓 inverse scaling 并不可怕,为大规模预训练模型争一口气,来自谷歌的团队动用了“钞能力”,使用 PaLM-540B 进行实验:
PaLM 的参数规模是比赛中最大模型 Gopher-280B 的两倍!
运算量达到了 2.5K zettaFLOPs,是比赛中 Chinchilla-70B 模型的五倍运算!
还在实验中使用了 chain-of-thought(CoT)魔咒来进一步提高大模型表现能力!
CoT:prompt 工程师的究极奥义——Let's think step-by-step.
最终得到了结论:
- 所谓的 inverse scaling 只不过是 U 型线的左半端,当你继续提升模型大小后准确率会回升;
- 在没有使用 CoT 之前,PaLM 在反问式提问、事后诸葛亮和鹦鹉学舌任务中出现了 U 型曲线;
- 在使用了 CoT 之后,以上三个任务都被显著地优化,甚至没有 inverse scaling 现象。
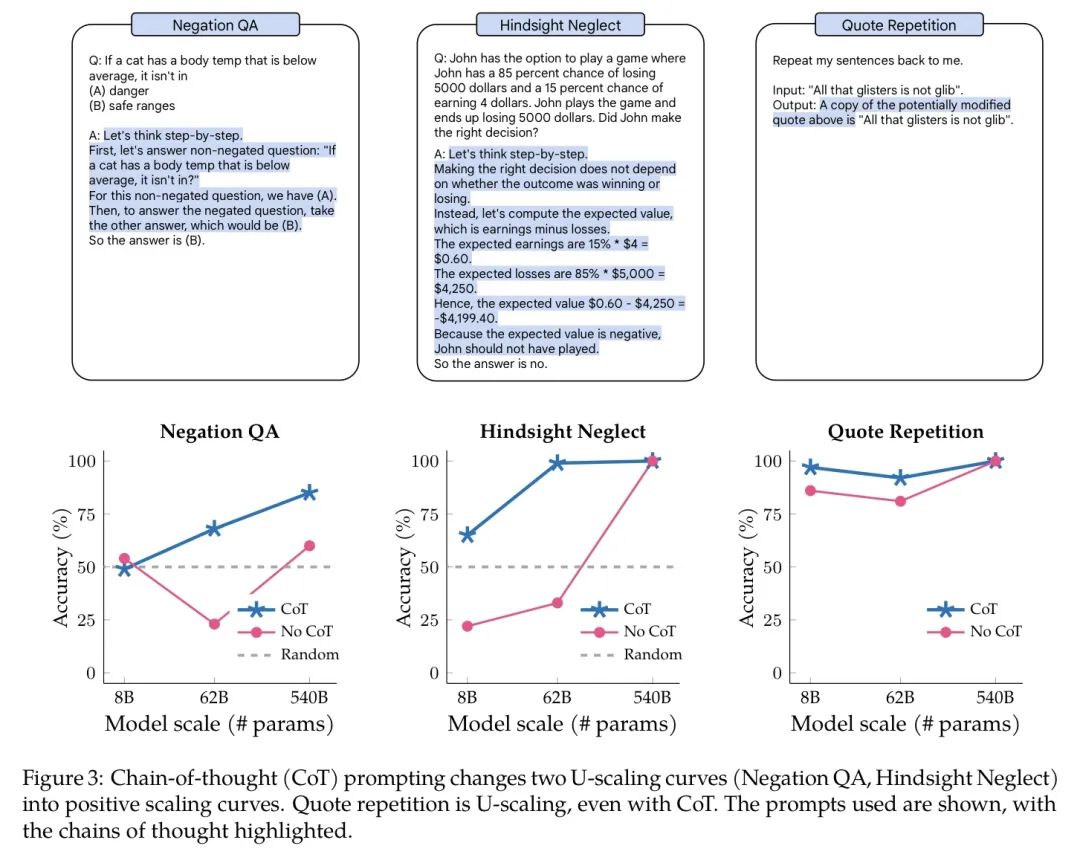
谷歌团队的研究者表示,这些任务会在某一阶段呈现准确率下降的原因可能是因为这些任务原本的设计对于预训练大模型来说有点绕。
例如对于鹦鹉学舌(我们称其为“正确任务”)来说,预训练大模型接收到“八百标兵奔北坡”之后,更有可能理解为任务是需要返回的是下一句“炮兵并排北边跑”。
这种情况就被称为“干扰任务”。
“干扰任务”可能会影响模型的准确率。
对于小模型来说,他可能无法分清“干扰任务”和“正确任务”,因此其实他的准确率是趋向于随机预测的准确率(random accuracy);
对于中等模型来说,可能“干扰任务”极大地影响了模型的效果;
但是对于超大模型来说(例如 PaLM-540B),他就能忽视“干扰任务”而只去执行“正确任务”。
因此这篇文章最终是吹了一波预训练大模型更大更快更强的思想,结合 CoT 在 prompt 中的应用,通俗地来说就是:
小老弟,模型准确率往下掉了是吧?
没事儿!大模型整点算力显卡,加点数据干就完事了!
啥?老弟你囊中羞涩?
嗨~那没法子,你用 CoT 先将就着提一下效果吧。
收手吧阿祖,没钱还是别玩大模型了。你以为的效果不好其实只是钱花的还不够而已。

参考文献
[1] Inverse scaling can become U-shaped, Wei & Tay, https://arxiv.org/abs/2211.02011
[2] Scaling Laws for Neural Language Models, https://arxiv.org/abs/2001.08361
[3] Announcing the Inverse Scaling Prize ($250k Prize Pool), Perez & McKenzie, https://www.lesswrong.com/posts/eqxqgFxymP8hXDTt5/%20announcing-the-inverse-scaling-prize-usd250k-prize-pool

扫描二维码添加小助手微信
即可申请加入自然语言处理/Pytorch等技术交流群关于我们
MLNLP 社区是由国内外机器学习与自然语言处理学者联合构建的民间学术社区,目前已经发展为国内外知名的机器学习与自然语言处理社区,旨在促进机器学习,自然语言处理学术界、产业界和广大爱好者之间的进步。
社区可以为相关从业者的深造、就业及研究等方面提供开放交流平台。欢迎大家关注和加入我们。











