本文详细介绍了英伟达的每向量缩放量化方案、新的数字格式 Posits 以及如何降低 RISC-V 的数学风险。

近年来 AI 领域的发展令人震惊,但为完成这些壮举而训练神经网络的成本也异常巨大。以大规模语言模型 GPT-3 和艺术生成器 DALL-E 2 为例,它们需要在高性能 GPU 集群上训练数月时间,耗资数百万美元,消耗百万亿计的基本计算。
同时,处理单元的训练能力一直在快速增长,仅 2021 年就翻了一番。为了保持这一趋势,研究人员正在深入研究最基础的计算构建块,即计算机表示数字的方式。
在上个月举办的第 29 届 IEEE 计算机算术研讨会(IEEE Symposium on Computer Arithmetic)的一场 Keynote 演讲中,英伟达首席科学家、高级研究副总裁 Bill Dally 表示,「过去 10 年,单个芯片的训练性能提升了 1000 倍,其中很大部分要归功于数字表示。」
在朝着更高效 AI 训练前进的过程中,首先「牺牲」的是 32-bit 浮点数表示,俗称标准精度。为了全面追求速度、能效以及芯片面积和内存的更好利用,机器学习研究人员一直努力通过更少 bit 表示的数字来获得相同的训练水平。对于试图取代 32-bit 格式的竞争者来说,这个领域依然很开放,无论是在数字表示本身还是完成基础运算的方式上。
英伟达每向量缩放量化方案(VSQ)
我们知道,图像生成神器 DALL-E 在英伟达 A100 GPU 集群上接受了标准 32-bit 数字和低精度 16-bit 数字的组合训练。Hopper GPU 更是支持了更小的 8-bit 浮点数。最近,英伟达在一项研究中开发了一个原型芯片,通过使用 8-bit 和 4-bit 数字的组合更进一步推动了这一趋势。

论文地址:https://ieeexplore.ieee.org/document/9830277
尽管使用了更低精确的数字,但该芯片努力保持计算准确率,至少在训练过程中的推理部分是这样。推理是在经过充分训练的模型上执行以获得输出,但在训练期间也会重复进行。Bill Dally 表示,「我们最终以 4-bit 精度得到 8-bit 结果。」
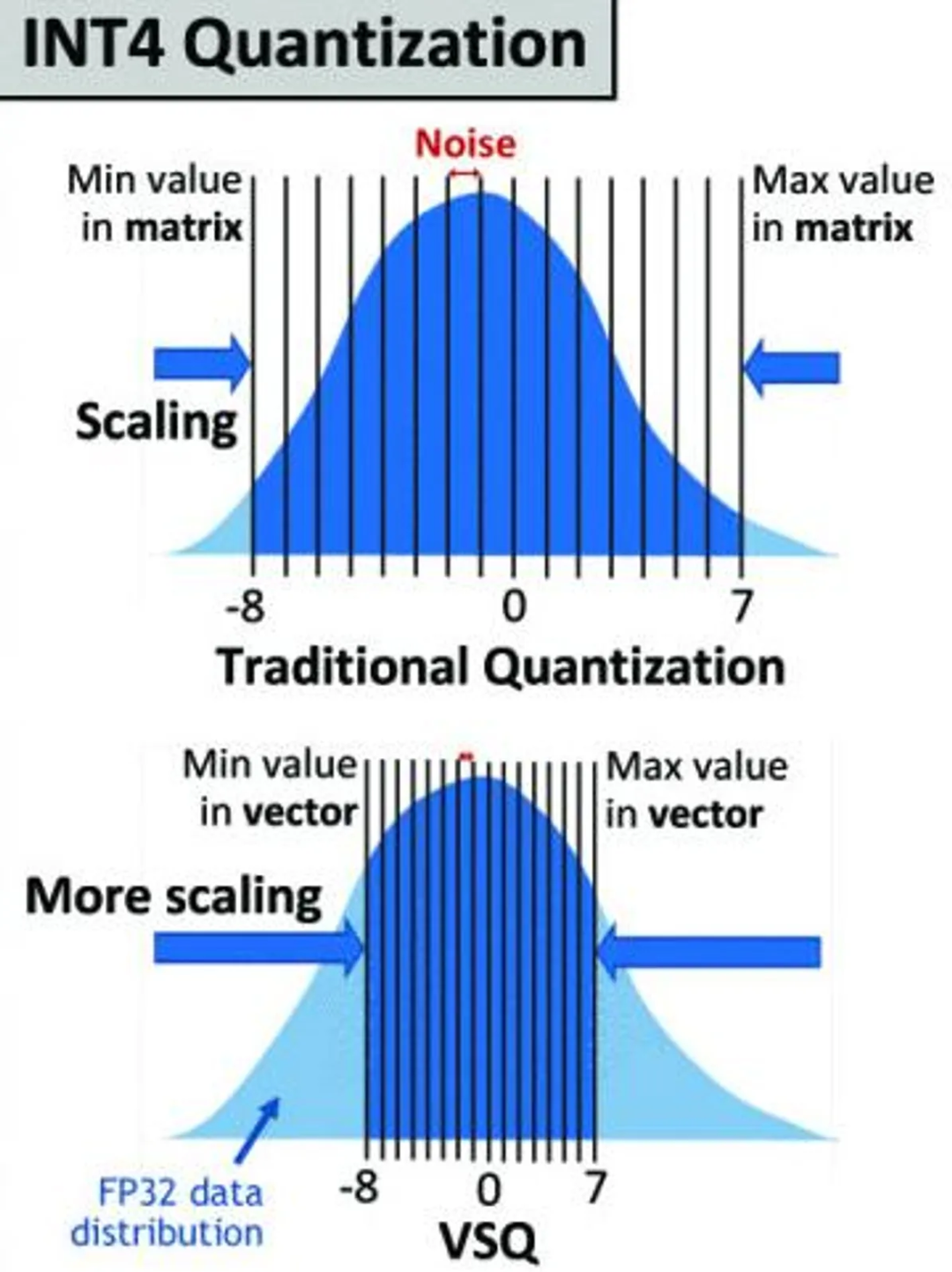
英伟达的每向量缩放方案比 INT4 等标准格式更好地表示机器学习中需要的数字。
得益于这种方案,英伟达能够在没有显著准确率损失的情况下减少数字大小。基本理念是这样的:一个 4-bit 数字只能精确表示 16 个值。因此,每个数字都会四舍五入到这 16 个值的其中一个。这种舍入导致的准确率损失被称为量化误差。
但是,你可以添加一个缩放因子在数轴上将 16 个值均匀地压缩在一起或将它们拉得更远,从而减少或增加量化误差。
所以诀窍在于压缩或扩展这 16 个值,这样它们就能与你在神经网络中实际需要表示的数字范围形成最佳匹配。这种缩放对于不同的数据集也是不同的。通过为神经网络模型中每个包含 64 个数字的集合微调这种缩放参数,英伟达的研究者能够最大限度地减少量化误差。他们还发现,计算缩放因子的开销也可以忽略不计。但随着 8-bit 表示减少至 4-bit,能效翻了一番。
实验芯片仍在开发当中,英伟达工程师也在努力研究如何在整个训练流程而不是仅在推理中利用这些原理。Dally 表示,如果成功,结合了 4-bit 计算、VSQ 和其他效率改进的芯片可以在每瓦特运算次数上达到 Hopper GPU 的 10 倍。
一种新的数字格式——Posits
早在 2017 年,美国计算机科学家 John Gustafson 和 J. Craig Venter 研究所助理研究员 Isaac Yonemoto 开发出了一种全新的数字表示方式—— posit。

论文地址:http://www.johngustafson.net/pdfs/BeatingFloatingPoint.pdf
现在,马德里康普顿斯大学的一组研究人员开发了首个在硬件中实现 posit 标准的处理器内核,并表示与使用标准浮点数的计算相比,基本计算任务的准确率最高可以提升四个量级。
论文地址:https://ieeexplore.ieee.org/document/9817027/references#references
posits 的优势在于它们沿着数轴分布来精确表示数字。在数轴的中间,大约在 1 和–1 附近,存在比浮点更多的 posit 表示。在两端,对于大的负数和正数,posit 准确率比浮点下降得更优雅。
Gustafson 表示,「posits 更适合计算中数字的自然分布。其实,浮点运算中有大量的 bit 模式,不过没有人使用过。这是一种浪费。」
Posits 在 1 和 -1 附近提升了准确率,这要得益于它们的表示中存在一个额外的组件。浮点数由三部分组成:一个符号位(0 表示正,1 表示负)、几个尾数(分数)位以表示二进制小数点之后的内容以及定义指数(2^exp)的其余位。
Posits 保留了浮点数的所有组件,但添加了一个额外的「regime」部分,即指数的指数。这个 regime 的奇妙之处在于它的 bit 长度可以变化。对于小数,regime 可能只需要 2 个 bit,为尾数提供更高精度。这允许在 1 和 - 1 附近的最佳位置实现更高的准确率。
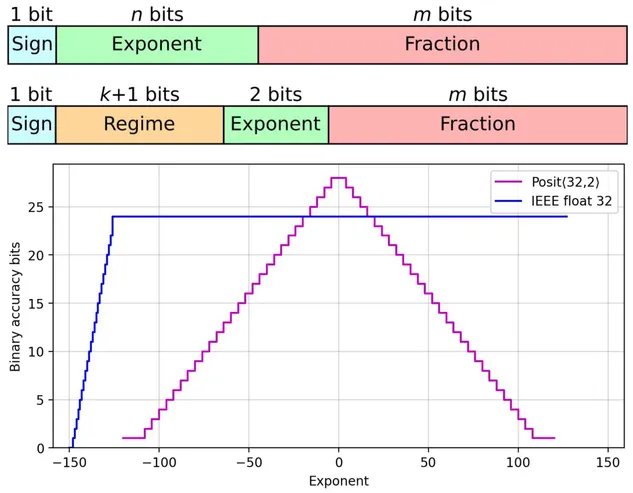
通过添加一个额外的可变长度机制,在零附近的数字将具有更好的准确率,神经网络中使用的大多数数字都在该位置。
借助在 FPGA 上合成的新硬件实现,Complutense 团队能够比较使用 32 位浮点数和 32 位 posits 完成计算的效果。他们通过将其与使用更准确但计算成本更高的 64 位浮点格式的结果进行比较来评估准确率。posits 在矩阵乘法的准确率方面惊人地提升了四个数量级。他们还发现,提高精度并没有以计算时间为代价,只是稍微增加了芯片的面积和功耗。
降低 RISC-V 的数学风险
一个来自瑞士和意大利的研究团队曾开发一种减少 bit 的方案,适用于使用开源 RISC-V 指令集架构的处理器, 并推进了新处理器的开发。该团队对 RISC-V 指令集的扩展包括一个有效的计算版本,它混合了较低和较高精度的数字表示。凭借改进的混合精度数学,他们在训练神经网络所涉及的基本计算中获得了两倍的加速。
降低精度在基本操作期间不仅会因 bit 减少导致精度损失,还会产生连锁反应。将两个低精度数字相乘可能会导致数字太小或太大而无法表示给定的 bit 长度——分别称为下溢和上溢;另外,将一个大的低精度数和一个小的低精度数相加时,会发生 swamping 现象,导致较小的数字完全丢失。
混合精度对于改善上溢、下溢和 swamping 问题具有重要作用,其中使用低精度输入执行计算并产生更高精度的输出,在舍入到较低精度之前完成一批数学运算。
点积是人工智能计算的一个基本组成部分,它通常通过一系列称为融合乘加单元 (FMA) 的组件在硬件中实现。它们一次性执行操作 d = a*b + c,最后只进行四舍五入。为了获得混合精度的好处,输入 a 和 b 是低精度(例如 8 bits),而 c 和输出 d 是高精度(例如 16 bits)。
IEEE Fellow Luca Benini 等人认为:与其一次只做一个 FMA 操作,不如同时做两个并在最后将它们加在一起。这不仅可以防止由于两个 FMA 之间的舍入而造成的损失,而且还可以更好地利用内存,因为这样就不需要有内存寄存器等待前一个 FMA 完成。
Luca Benini 领导的小组设计并模拟了并行混合精度点积单元,发现向量的点积计算时间几乎减少了一半,并且输出精度提高了。他们目前正在构建新的硬件架构,以证明模拟的预测。
更多详细内容请参阅原文链接:https://spectrum.ieee.org/number-representation

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com









