点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

一、正则化介绍
问题:为什么要正则化?
NFL(没有免费的午餐)定理:
没有一种ML算法总是比别的好
好算法和坏算法的期望值相同,甚至最优算法跟随机猜测一样
前提:所有问题等概率出现且同等重要
实际并非如此,具体情况具体分析,把当前问题解决好就行了
不要指望找到放之四海而皆准的万能算法!
方差和偏差:
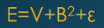
过拟合与欠拟合:
训练集和测试集
机器学习目标:
特定任务上表现良好的算法
泛化能力强-->验证集上的误差小,训练集上的误差不大(不必追求完美,否则可能会导致过拟合)即可。
如何提升泛化能力:
(1)数据
数据和特征是上限,而模型和算法只是在逼近这个上限而已
预处理:离散化、异常值、缺失值等
特征选择
特征提取:pca
构造新的数据:平移不变性
(2)模型
数据中加入噪音
正则化项:减少泛化误差(非训练误差)
集成方法
几种训练情形:
(1)不管真实数据的生成过程---欠拟合,偏差大
(2)匹配真实数据的生成过程---刚刚好
(3)不止真实数据的生成过程,还包含其他生成过程---过拟合,方差大
正则的目标:
从(3)--->(2),偏差换方差,提升泛化能力
注:
永远不知道训练出来的模型是否包含数据生成过程!
深度学习应用领域极为复杂,图像、语音、文本等,生成过程难以琢磨
事实上,最好的模型总是适当正则化的大型模型
正则化是不要的!!!
XTX不一定可逆(奇异),导致无法求逆(PCA)
解决:加正则,XTX--->XTX+αI(一定可逆),说明:α--阿尔法,I--大写的i,即单位阵。
大多数正则化能保证欠定(不可逆)问题的迭代方法收敛
注:伪逆
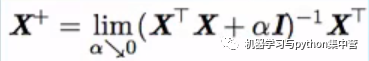
二、深度网络正则化
深度网络中的正则化策略有哪些?——传统ML方法的扩展
方法:
增加硬约束(参数范数惩罚):限制参数,如L1,L2
增加软约束(约束范数惩罚):惩罚目标函数
集成方法
其他
约束和惩罚的目的
植入先验知识
偏好简单模型
三、参数范数惩罚
从线性模型说起:
形式:y=Wx+b
W:两变量间的相互作用——重点关注
b:单变量——容易欠拟合,次要
仿射变换=线性变换+平移变换
参数范数惩罚:
通常只惩罚权重W,不管b——b是单变量,且容易过拟合
θ=(W;b)≈(W)
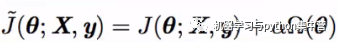
α是惩罚力度,Ω是正则项。
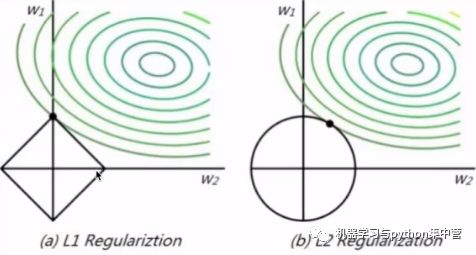
最常见,L2参数范数惩罚:
权重衰减(weight decay)
岭回归,Tikhonov正则
形式:
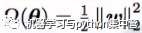
效果:
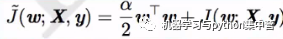
正则项Ω挤占原始目标J的空间,逼迫J
权重接近于原点(或任意点)
详细推导过程见P142-P143
L2正则能让算法“感知”到较高方差的输入x
线性缩放每个wi
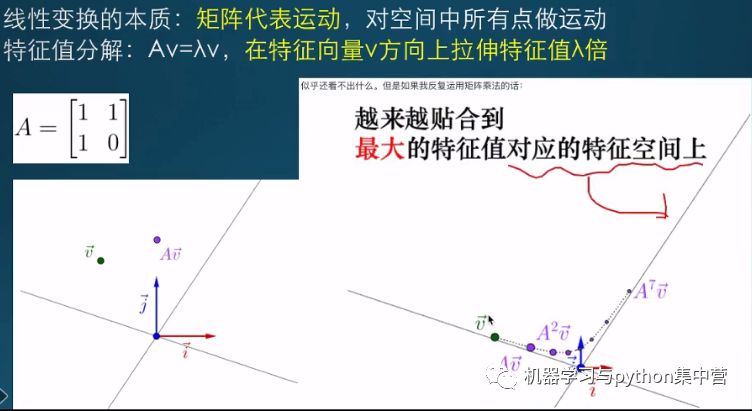
L1参数范数惩罚:LASSO
形式:

效果:
L1与L2大不一样:线性缩放wi-->增加wi同号的常数
某些wi=0,产生稀疏解,常用于特征选择
除了L1,稀疏解的其他方法?
Student-t先验导出的惩罚
KL散度惩罚
注:不同于L1惩罚参数,惩罚激活单元
约束范数惩罚:
本质:约束问题--> 无约束问题
形式:
参数范数惩罚:
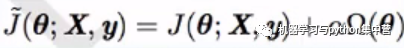
约束范数惩罚:
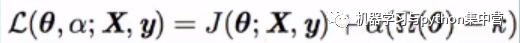
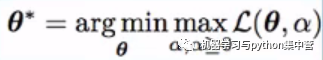

五、数据增强
提升泛化能力的最好办法:
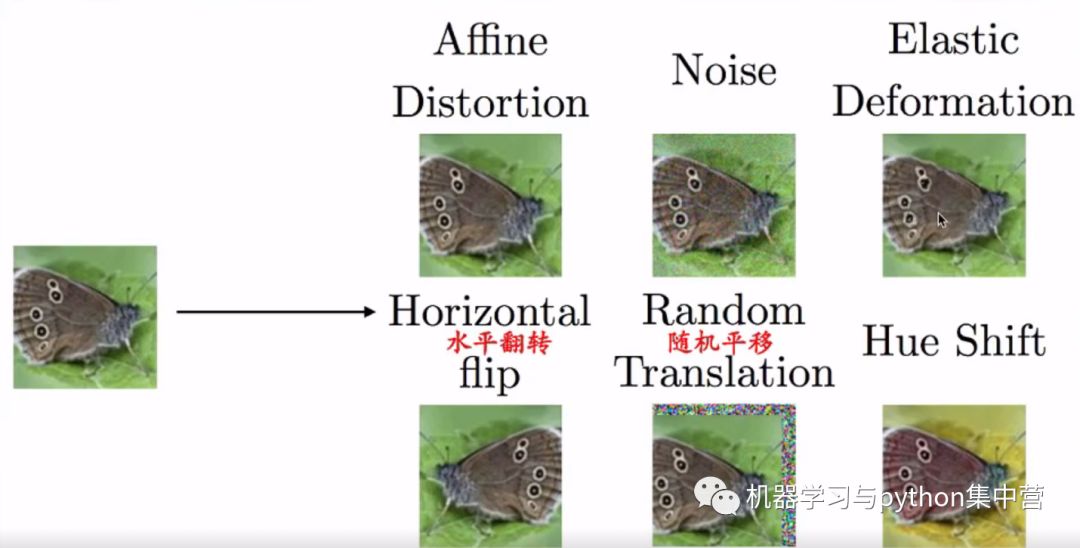
数据增强:创造假数据
方法:
(1)数据造假:平移、旋转、缩放——不能改变类别
图像,语音
(2)注入噪声
输入层≈权重参数惩罚
隐含层:去噪编码器、dropout
权重:RNN
输出层:标签平滑(反例)
softmax永远无法真正预测0或1,需要做平滑,防止走极端
噪声鲁棒性:
注入噪声远比简单收缩参数强大,特别是加入隐含层
六、早停止
问题
随着时间推移,训练集误差逐渐减少,而验证集误差再次上升
能不能在转折点处提前终止呢?
早停止
当验证集误差在指定步数内没有改进,就停止
有效,简单,高效的超参选择算法
训练步数是唯一跑一次就能尝试很多值的超参
第二轮训练策略(验证集)
(1)再次初始化模型,使用所有数据再次训练
使用第一轮步数
(2)保持第一轮参数,使用全部数据继续训练
避免重新训练高成本,但表现没那么好,不保证终止
早停止为何有正则化效果?
表象:验证集误差曲线呈U型
本质:将参数空间限制在初始参数θ0的小邻域内(εt)
εt等效于权重衰减系数的倒数
相当于L2正则,但更具优势
自动确定正则化的正确量

七、参数绑定和参数共享
参数范数惩罚:
对偏离0(或固定区域)的参数进行惩罚,使用参数彼此接近
一种方式,还有吗?
参数共享:
强迫某些参数相等
优势:只有参数子集需要存储,节省内存。如CNN
八、集成方法
集成方法:
集合几个模型降低泛化误差的技术
模型平均:强大可靠
kaggle比赛中前三甲基本都是集成方法
Bagging:
有放回抽样,覆盖2/3
多个网络的集成
偏差换方差
Boosting:
单个网络的集成
方差换偏差
Dropout:
集成大量深层网络的bagging方法
多个弱模型组成一个强模型
施加到隐含层的掩掩码噪声
一般5-10个网络,太多会很难处理
示例:
2个输入,1个输出,2个隐含层
一共24=64种情形
问题:大部分没有输入,输入到输出的路径
网络越宽,这种问题概率越来越小
注:
不同于bagging,模型独立
dropout所有模型共享参数
推断:对所有成员累计投票做预测
效果:
Dropout比其他标准正则化方法更有效
权重衰减、过滤器范数约束、稀疏激活
可以跟其他形式正则一起使用
优点:
计算量小
不限制模型和训练过程
注:
随机性对dropout方法不必要,也不充分
九、对抗训练
人类不易察觉对抗样本与原始样本的差异,但网络可以
小扰动导致数据点流行变化

再次附上:
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~













