导读:随着机器学习和云原生的迅速发展应用,更好更方便的利用机器学习方法成为算法工程师和非算法工程师的开发者的紧迫需求,我们希望有这样一个平台,它具备数据处理,开发模型,模型部署,管理数据等围绕着数据和模型的能力,机器学习平台应运而生。市场上有非常多种机器学习平台,有不同的侧重和特点,而阿里机器学习平台 PAI,融合了阿里本身成熟的组件生态,以及基于云原生开发的特点,使得具有无服务器(Serverless),弹性计算(Elastic),容器化(Container)等优势。今天我们一起聊一聊 PAI 平台。
今天的介绍会围绕下面三部分内容展开:
分享嘉宾|谭锋 阿里云 资深技术专家
编辑整理|于晓涛 nyjk
出品社区|DataFun
01
PAI 平台产品设计
PAI 平台具有丰富的功能,我们从机器学习平台本身应具备的功能开始讲起。
1. 机器学习平台应具备的功能

作为一个机器学习平台,必须要具备四个主要的功能:
数据处理。包含但不限于预处理,特征处理,数据加强等方法。
模型开发。如何选择算法,传统机器学习或是深度学习等等。
模型训练。代码如何编写,如何调度资源进行模型训练。
2. 数据处理
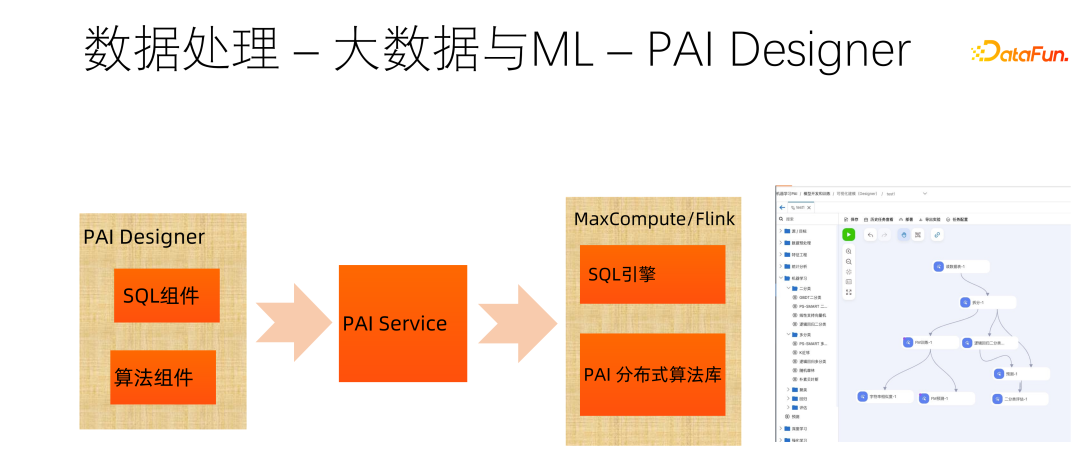
当前数据规模越来越大,无论存储角度还是计算角度,数据处理基本上是离不开大数据的。PAI 在数据处理方面提供了两类数据处理能力,一类是传统的 SQL 能力,另一类是利用分布式算法库,利用 Flink 等框架进行大规模数据的处理。同时,既有的算法库还可以像上图右侧那样进行拖拉拽可视化编排组合,更加方便的进行数据处理。
3. 模型开发

① 模型开发主要分为两类:
传统机器学习算法。比如耳熟能详的 GBDT、SVM、逻辑回归等。以及流行度非常高的 XGBOOST。此类算法有个特点,基本上无需用户编写算法逻辑,可以直接由框架或平台提供。PAI 中也可使用拖拉拽方式进行可视化开发。
深度学习算法。
深度学习算法带来了两个问题:第一个是他的数据增加了许多非结构化数据,比如图片、文本和语音,这就必须引入其他形式的存储——对象存储,比如 AWS 的 S3。第二个问题是异构计算,即异构加速,Google 使用的是 TPU,普通公司一般多用 GPU 等情况。还有各种各样的深度学习框架的环境适配问题。
② DSW(Data Science Workshop)交互式建模工具

算法研发过程中,无论是硬件的选型搭建还是软件环境搭建,都需要花费相当多时间,DSW 借助云原生技术,提供一个永远在线的云端开发环境,就像一台虚拟机一样,可以随时随地打开或关闭。DSW 并且集成了 Jupyterlab,Vscode 和 Terminal 三种编程入口。
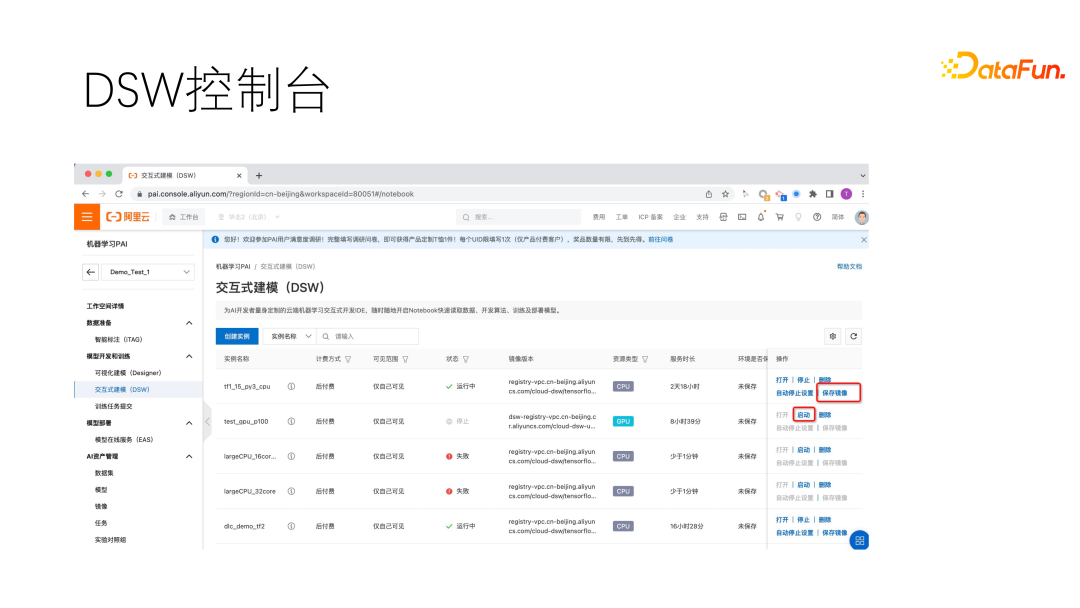
DSW 还配置了 10 多种适用于不同 AI 场景的典型软件环境配置,包括 Tensorflow 和 PyTorch 等主流训练框架的不同版本组合,供用户选择。作为高度开放的开发环境,DSW 开放 Sudo 权限给用户、支持任意第三方库安装。
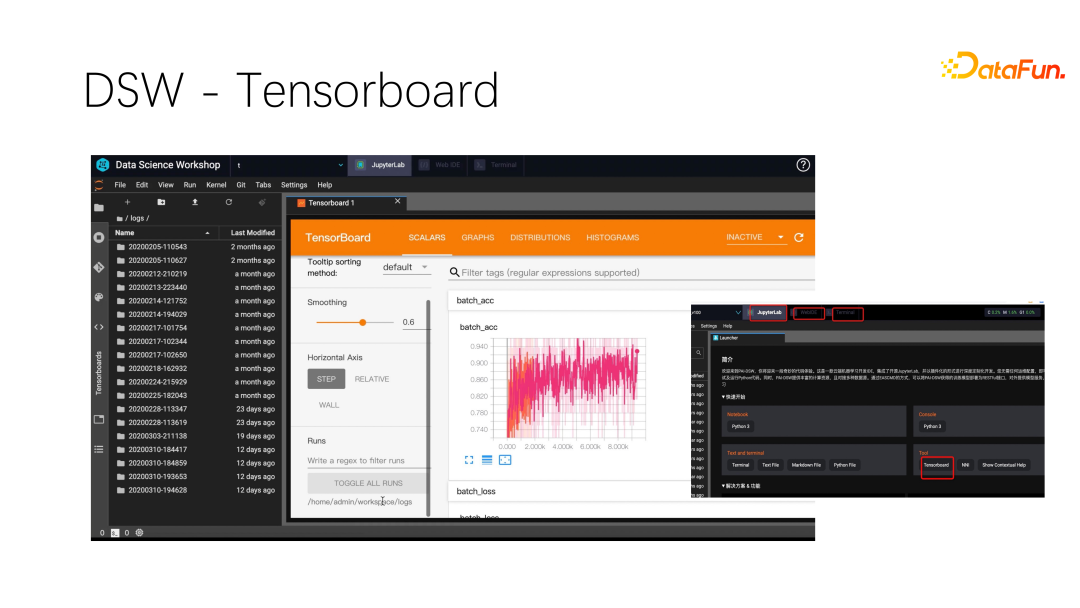
DSW 还有个非常有用的功能:Tensorboard。在 DSW 环境中做训练,可以通过 Tensorboard 来查看训练效果。同时还有文件上传下载功能,这样只需在 DSW 一个平台上就能做模型开发过程中所有要做的事情。

前述功能可以理解为帮用户拉起了一个 Jupyter,除了这些,DSW 还具有一些特殊的功能。第一个是容器技术,用户可以在环境中安装各种各样的 Python 包或者系统软件等等,这个定制化的环境是可以保存起来,方便用户后续继续使用,无需用一次配置一次。第二个是保存的镜像可以在工作空间里分享给别的同事使用,还可以直接推到离线平台里作为训练环境使用。这样就解决了环境迁移问题。

算法开发过程中的数据也是非常重要的,主要有两部分,一是源代码,二是训练样本。NAS 方式直接挂载为本地的文件系统,可以进行随机存储,也方便做持久化和团队共享,更适合源代码场景,结合前述中环境保存复制,可以非常方便地进行迁移。OSS 方式不支持指定位置的随机读写,且是非结构化的存储,建议存储训练样本。

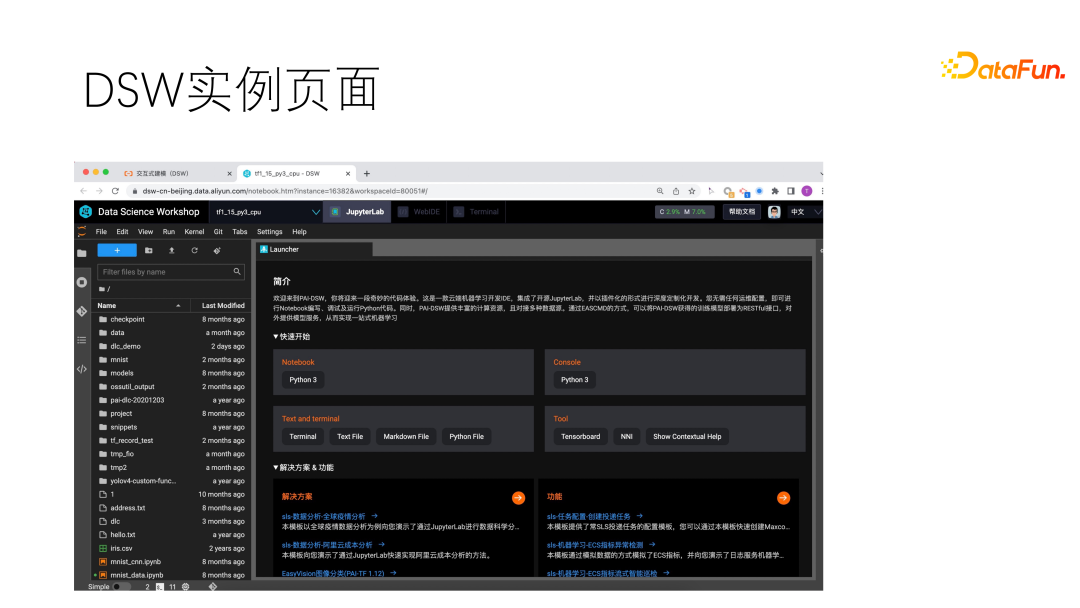
最后总结一下 DSW 中的“实例”,实例有两部分组成,实例管理控制台和每个实例自己的 Web 页面。每个实例都运行在独立的 K8S 容器中,所有服务和环境以及网络都是独立的,实例永远在线,除非被停止。且实例创建时,需要指定所需资源、镜像、存储等。
4. 模型训练
在机器学习流水线中,光有 DSW 平台是不够的。在算法开发过程中,代码是会经常变化的,变了就需要看到效果,有时候还需要断点调试一下。这种场景下,并不需要分布式或者多大的训练集群,更需要的是在小数据集上看到收敛的情况,即 DSW 是非常合乎需求的,随开随停,计费灵活。
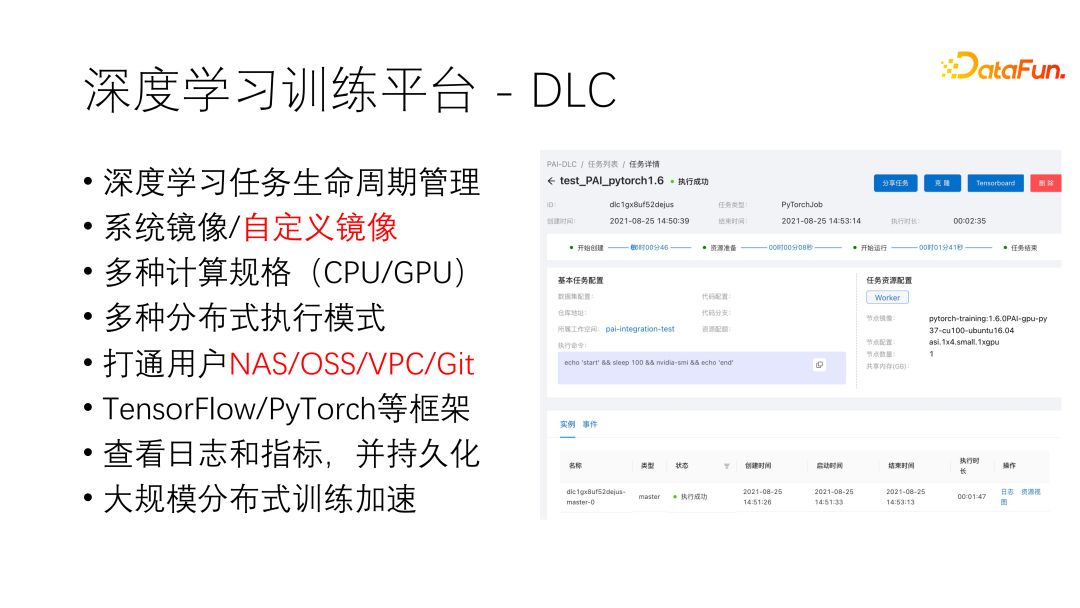
但是,验证完毕后,实际模型训练过程中,并不会随时启动,更多的情况是来一批数据,跑一次训练,训练跑完任务就结束了,甚至一周才来一次新的数据,这样情况使用 DSW 就得不偿失了。在 PAI 中,我们开发了一个专门用于训练的平台 DLC(Deep Learning Containers)。
用户可以在 DLC 平台中指定脚本训练、所需的镜像、计算资源、计算框架等等。同时,在 DLC 中,用户的存储也是会被打通,包括 NAS,OSS 等方式。除了单机训练代码要改为分布式训练,用户的训练代码都无需改动。同时任务运行过程中的日志和各项指标(如 GPU 算力、磁盘 IO 等)也可以进行持久化保存。
5. 模型服务

EAS 是一个自助式的弹性算法服务。模型准备好之后,通过界面按钮点击或者 SDK 即可一键部署。具备低延时、高吞吐的特点。吞吐高意味着成本可以降低,低延时可以使得应用响应非常快。支持 Tensorflow,Pytorch 等多种模型格式。同时,作为在线服务,分组发布和蓝绿发布以及根据流量动态扩缩容这些必备功能均已实现。
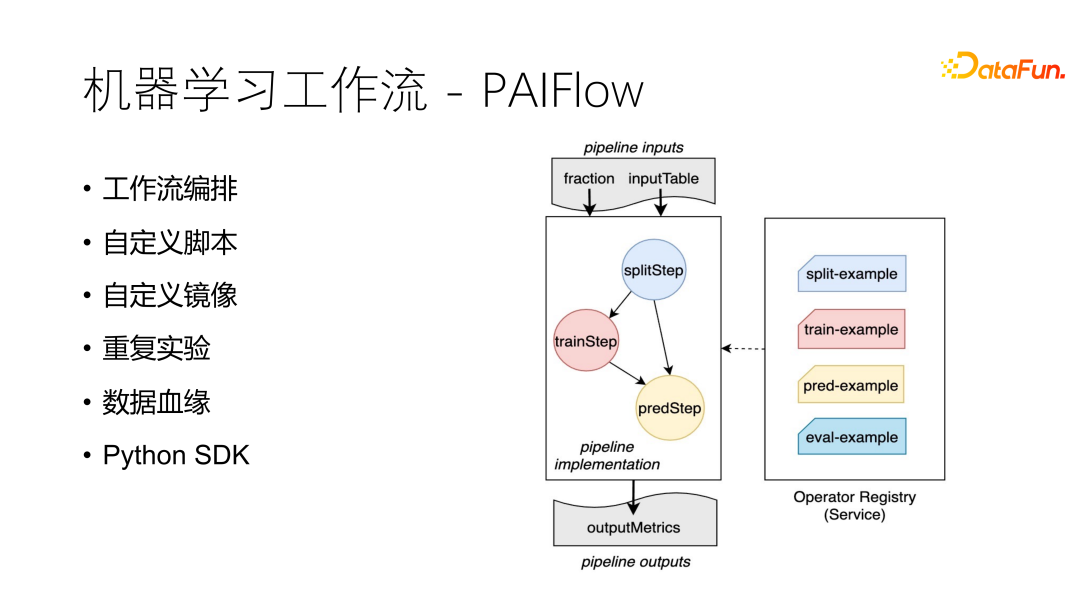
最后是机器学习工作流。实际开发中,极有可能做多个实验调试各个参数,或者复用别人的组件。这就需要一个简单的 Pipline 方式来编排任务——PAIFlow,可以通过界面拖拉拽进行编排,或者使用 Python 的 SDK 进行编排。
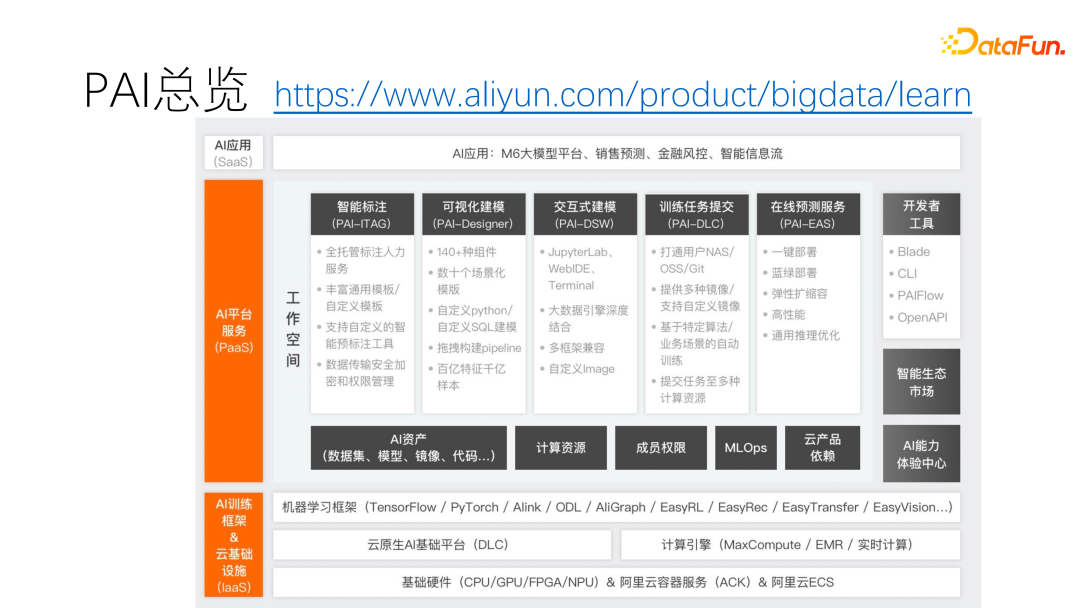
以上就是从产品角度对功能的介绍。上图展示了 PAI 整体包含的内容。作为一个 PaaS 平台,其具有很强的灵活性和抽象性,每个模块都可以单独部署、单独使用。值得一提的是,藏在平台背后的性能加速的能力,其并非以产品或 API 暴露出来的,比如模型加速、分布式加速等等都是嵌入在平台中的。
1. 存储

作为机器学习平台,存储的选择要分清楚要存哪些数据。比如样本数据,就分为结构化和非结构化两种形式存储;用户的开发代码;以及维护各种任务时的日志与指标进行记录,这就需要时序数据库,还有计量计费信息。这些都可以依托阿里云现有的产品,比如 RDS 这种托管的 MySQL 服务,阿里的 SLS 日志服务,以及 MaxCompute 和 Flink 等产品。
2. 计算资源

计算资源也同存储一样,大数据资源的话可以直接使用阿里云的产品。K8S集群可以直接选用阿里的 ACK 产品使用。这样就可以把资源管理起来了。
3. 服务

如何将所有的能力用服务的方法暴露出来,这也是非常重要的问题。谈服务即是谈 Open API,有了 OpenAPI 后,才能够把所有的能力被自动化起来,才可以开发出命令行,才能被第三方平台使用程序的方法进行对接。Open API 中需要加上鉴权、流控等细节。发布为 Open API 还有的好处是所有的能力可以通过不同的 API 暴露出来,那么服务背后的技术栈或是版本就无关紧要了,并且可以独立部署,互不影响。
4. 云原生

无服务器,这是云计算最大的特点,即用户不用去管运维,可以节约运维的成本。还要保证 Open API 的高可用,除了自身服务高可用,还要保证底层的技术组件包括数据库、日志等都要高可用。多租户而言,根据企业的要求不同,权限隔离都可以以云原生的方式进行处理。
弹性计算也是云原生特点之一,对于用户而言,云资源是无限的,当然是在阿里云现有库存的基础上的无限,于是可以根据需求进行动态的扩缩容,灵活可用性强。
容器化本质是借助镜像,通过任务容器化,可以做到实例互不干扰,同时运行用户自定义镜像,无论是开发环境还是训练环境。
通过打点的方式进行计量计费,计量计费可以更好的提高资源的利用率,控制成本。
5. 总体架构
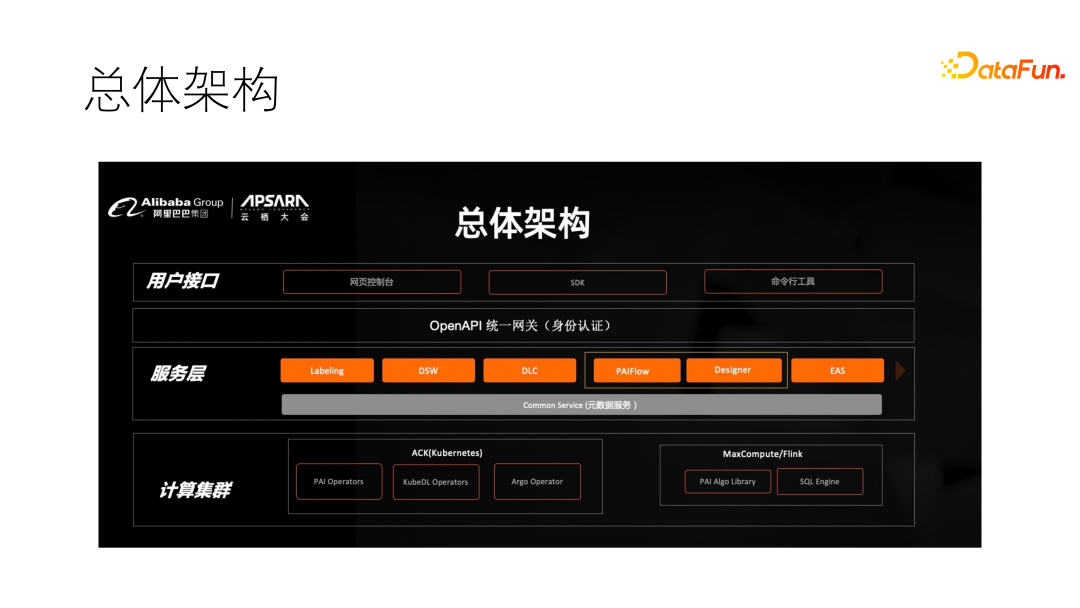
最后总结下总体架构,用户接口包含三类:网页控制台,SDK,命令行工具。它们统一依赖于 Open API 的网关。接下来是各种各样的 Service,每个模块都是一个相对独立的服务。这些服务除了和数据库交互外,还会和底层的计算集群打交道,比如 ACK 集群(K8S 集群),大数据集群 Flink 等。
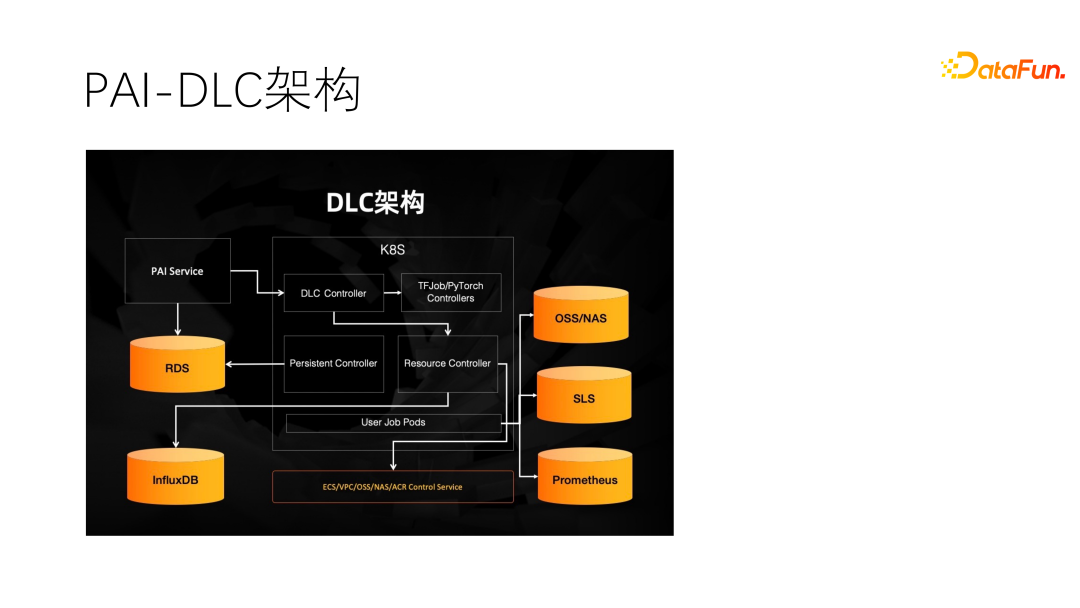
另外重点讲一下 DLC 的架构。用户提交一个任务上来,首先会持久化写道数据库(阿里云 RDS)中,直接放到 K8S 不可行的,K8S 一重启,任务全都没了,所以需要先进性持久化。DLC 上开发了丰富的 Operator 或者 Controller,用于准备运算环境,资源准备好之后,TFJob 会被调度起来,进行运行,同时会有要给持久层,将任务里的状态持久化到TDS,并且收集数据、日志和指标放到 SLS 和 Prometheus 中。同时,用户的存储也是打通的,可以直接访问。
最后还有一个 User Job,进行计量服务,按分钟进行打卡,Pod 启动后每过一分钟打一个点,最后统计点数,即可得到 Pod 运行的时间。
03
1. 案例一:传统机器学习+大数据+定时任务

2. 案例二:深度学习场景

今天的分享就到这里,谢谢大家。

谭锋
阿里云 资深技术专家
曾任职微软中国,是微软搜索引擎必应团队的资深架构师。目前负责阿里云机器学习PAI平台研发和架构设计。擅长云原生与AI的结合,率领团队完成PAI平台的全面云原生化,并拥有多年的AI落地以及企业智能化经验。
专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章800+,百万+阅读,15万+精准粉丝。










