论文是学术研究的精华和未来发展的明灯。小白决心每天为大家带来经典或者最新论文的解读和分享,旨在帮助各位读者快速了解论文内容。个人能力有限,理解难免出现偏差,建议对文章内容感兴趣的读者,一定要下载原文,了解具体内容。

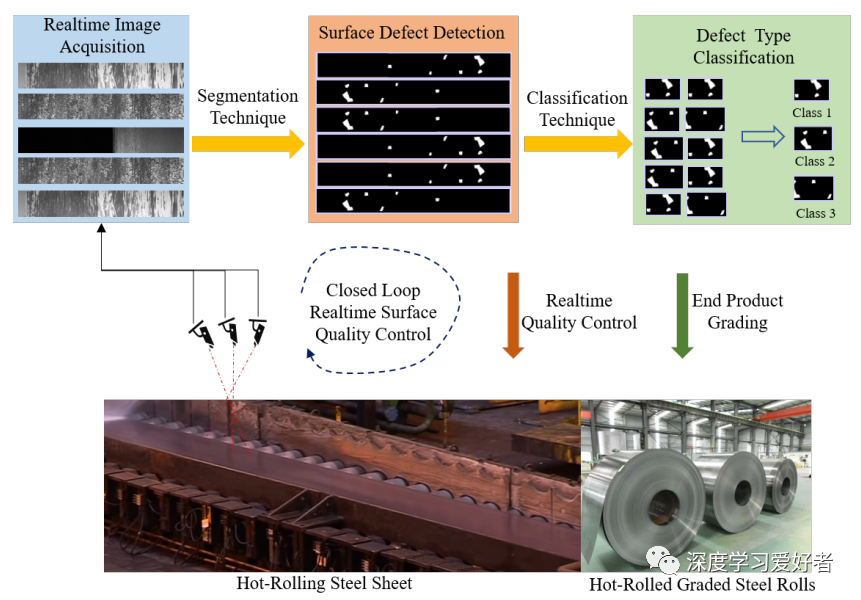
钢表面缺陷的目视检测是钢板制造过程中必不可少的环节。近年来研究了几种基于机器学习的自动视觉检测(AVI)方法。然而,由于训练时间和AVI方法的不准确性,大多数钢铁制造行业仍然使用人工目视检查。自动钢缺陷检测方法在成本更低和更快的质量控制和反馈方面是有用的。但是,为分割和分类准备带注释的训练数据可能是一个昂贵的过程。在这项工作中,我们建议使用基于迁移学习的U-Net (tu - net)框架来检测钢表面缺陷。我们以U-Net架构为基础,探讨了两种编码器:ResNet和DenseNet。我们使用随机初始化和使用ImageNet数据集训练的预训练网络的性能进行了比较。实验使用Severstal数据进行。结果表明,迁移学习的缺陷分类性能比随机初始化的缺陷分类性能好5%(绝对)。我们发现迁移学习在缺陷分割中的表现比随机初始化好26%(相对)。迁移学习的增益随着训练数据的减少而增加,且迁移学习的收敛速度优于随机初始化。
在本研究中,我们系统地研究了迁移学习在钢材缺陷分类与定位(SDCL)中的有效性。迁移学习或领域适应的目的是重用在一个领域学习到的特征,以提高在另一个领域的学习。在带注释的数据有限的情况下,这是一种流行的方法。迁移学习在各种任务中都有很好的应用,如对象检测、语义分割等。已经表明,从一个任意领域到另一个领域的迁移学习可能是没有用的。当两个领域相似时,迁移学习最有效。因此,研究迁移学习在SDCL案例中的有效性就显得尤为重要。我们考虑了一个用于钢缺陷分割的u网基线架构。U-Net已经展示了在各种图像分割任务的艺术表现状态。它使用了带有跳过连接的编码器-解码器架构。编码器学习不同尺度的图像特征,解码器使用这些特征预测分割掩码。
在这项工作中,我们探索了两种预先训练的编码器网络ResNet和DenseNet网络。这两种网络在不同的计算机视觉任务中都表现得很好。网络是在ImageNet数据集上预先训练的。我们使用一个线性分类器使用瓶颈表示的U-Net分类缺陷。我们使用Severstal数据集对网络的编码器和解码器进行微调。在Severstal数据上的实验表明,与随机初始化相比,预先训练网络的分割和分类性能都更好。研究发现,如果使用50%的数据进行训练,使用预训练网络的性能提高甚至更高。我们还证明了迁移学习的收敛速度比随机初始化快。
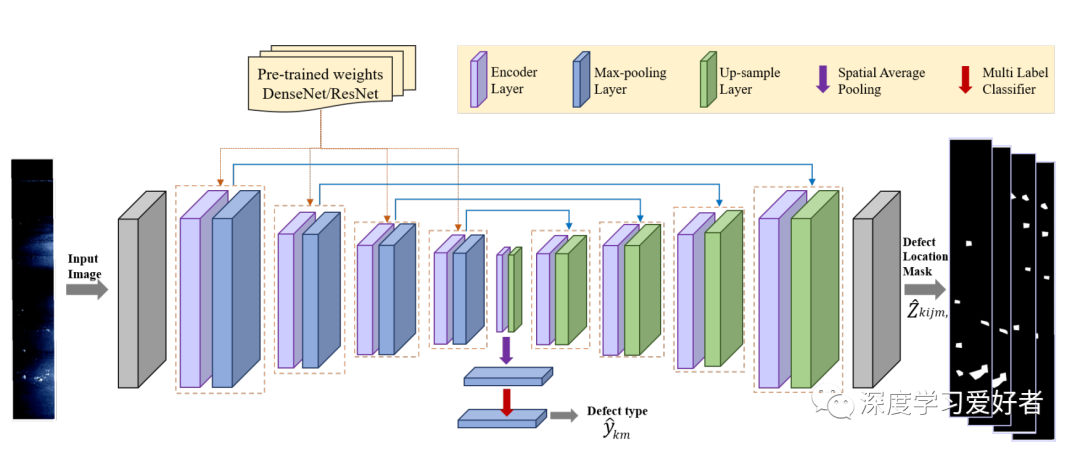
提出的用于节点钢缺陷分类和分割的结构迁移学习方法。蓝色的线表示跳跃连接,橙色虚线表示初始化。
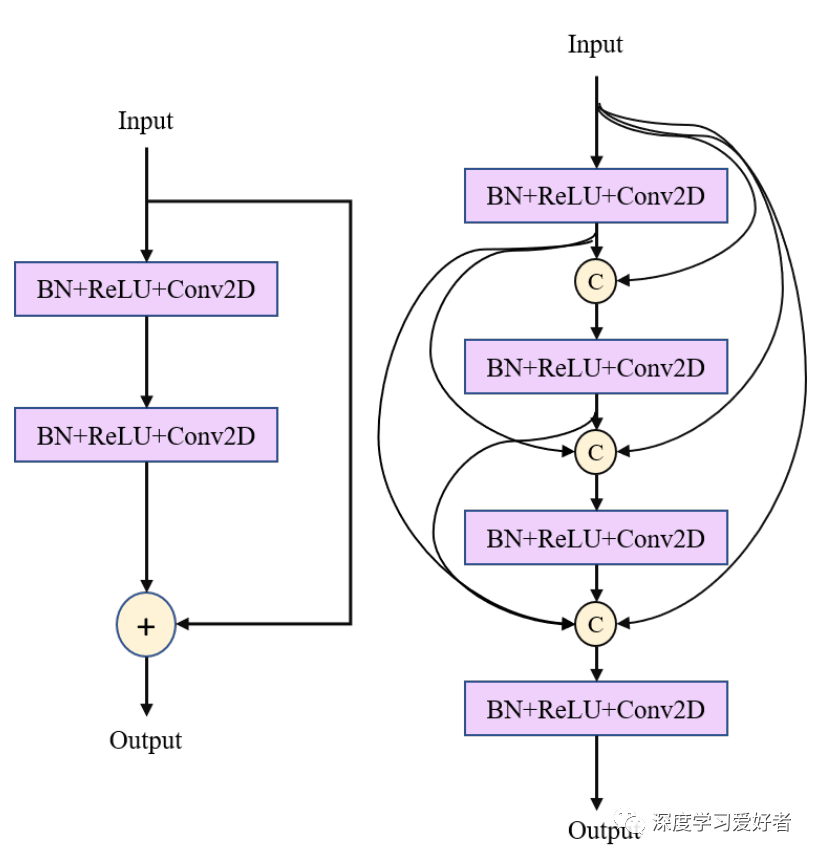
编码器层的结构为Resnet(左)和Densenet(右)。输入的连接由(c)表示,+表示添加操作。BN+ReLU+Conv2D表示批处理归一化、ReLU激活和核尺寸为3x3的卷积。

图分割掩模预测。(a行)输入图像(b行)ground truth masks (c行)ResNet(Random)预测的掩码(d行)ResNet(ImageNet)预测的掩码。预测的相应骰子显示在图像的标题中。
在本研究中,我们建议使用迁移学习框架来进行钢材缺陷的分类和分割。我们使用U-Net架构作为基础架构,并探讨两种编码器:ResNet和Dense Net。我们比较了使用随机初始化的网络和使用ImageNet数据集训练的预训练网络的性能。我们发现,迁移学习的性能在缺陷分割和分类方面都优于ImageNet。我们还发现,随着培训数据的减少,绩效差距增加。我们还发现,迁移学习的收敛速度比随机初始化的收敛速度要快。我们发现,在罕见缺陷类型和复杂形状缺陷中,迁移学习性能较差。作为未来工作的一部分,我们将致力于迁移学习,使用合成数据处理更复杂的形状,以及使用生成模型进行罕见的缺陷类型泛化。我们希望探索半监督/弱监督学习方法来减少标注训练数据的需求。
论文链接:https://arxiv.org/pdf/2101.06915.pdf
声明:部分内容来源于网络,仅供读者学术交流之目的。文章版权归原作者所有。如有不妥,请联系删除。
-
- 机器学习交流qq群955171419,加入微信群请扫码










