本文仅供技术学习。
今天分享一单来自金主爸爸的私单,运用简单的爬虫技巧,可以有效的规避反爬机制,正所谓“你有张良计,我有过云梯”。这个案例也很好的体现了python语音的优势,规避了非常复杂的底层逻辑,所见即所得,30分钟收入200。。
1.1 爬虫的思路及分析
当我们接到一个爬虫的单子时,一定要先分析思路,程序员的工作思路往往比代码更重要,思路对了,代码不会还可以查,思路错了,就只能在无尽的报错中呵呵了~~
我接到这个私单,是爬取今年以来的菜市场物价,客户提供的网站为。可以看到,数据有19733页,每页20条,一共39万多条信息 通过初步的尝试和分析,网站具有一定的反爬机制,点击下一页后,网页并不会整体刷新,替换的只是其中的表格,查看网页源代码,表格部分的来源也是加密的。如果按照以往的方法,就需要复杂的解密,然后再找出页面之间的规律,此时,就凸显出Selenium的优势了。
通过初步的尝试和分析,网站具有一定的反爬机制,点击下一页后,网页并不会整体刷新,替换的只是其中的表格,查看网页源代码,表格部分的来源也是加密的。如果按照以往的方法,就需要复杂的解密,然后再找出页面之间的规律,此时,就凸显出Selenium的优势了。
1.2 Selenium的作用及环境配置
作用:它可以打开浏览器,然后像人一样去操作浏览器。
环境搭建:1、pip install selenium
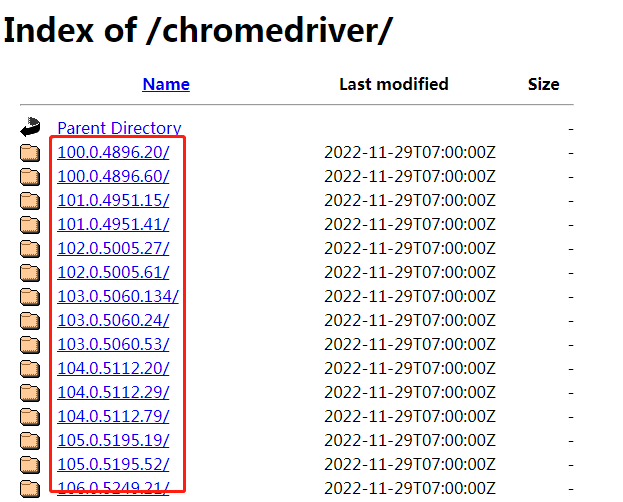
2、下载对应“XX浏览器驱动”,解压后的文件放在Python解释器(对应虚拟环境中),下面以谷歌浏览器驱动为例子。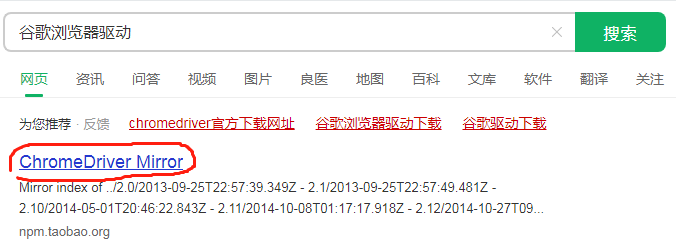
解压后的文件。
在pycharm中可以看到配置的环境在哪里。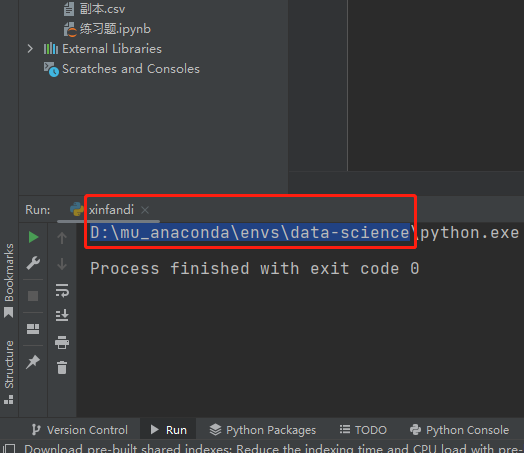
最后放置时,记得检查驱动命名后面是否有数字等符号,记得去掉。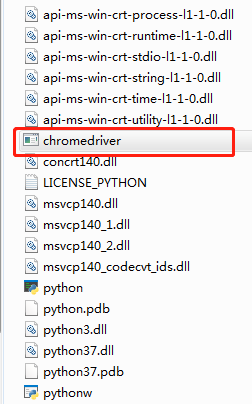
1.3 代码部分
1、首先是导入使用的模块:
import time #时间模块
from selenium.webdriver import Chrome #浏览器驱动模块
from selenium.webdriver.chrome.options import Options #无头浏览器模块
import csv #csv的读写模块
2、配置无头浏览器参数(代码基本固定,复制就可使用,配置后,在代码运行中不会再弹出浏览,而是改为后台操作)
opt = Options()
opt.add_argument("--headless")
opt.add_argument("--disbale-gpu")
3、创建一个浏览器对象
web = Chrome(options=opt) #创建一个浏览器对象
web.get("http://www.***.com.cn/priceDetail.html") #用浏览器打开一个网站
time.sleep(3) # 休息3秒,selenium的缺点就是慢,必须等待上一步完成后才能执行下一步操作,否则容易报错
4、创建一个CSV文件
ex = open("x_caijia2.csv", mode="w", encoding="utf8") #打开一个文件
csvwriter = csv.writer(ex) #设置写入的路径
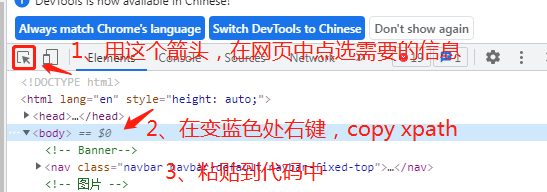
5、获取表头的xpath,并写入csv文件
xpath_ex = '//*[@id="bbs"]/div/div/div/div[4]/div[1]/div/table/thead/tr' #运用开发者工具,获取目标信息的xpath
ex_header = web.find_element_by_xpath(xpath_ex).text.split(' ') #抓取并转换为列表信息
# print(ex_header) #到这步时可以先测试一下是否能获取到信息
csvwriter.writerow(ex_header) #将表头写入csv文件
6、运用循环抓取并保存页面信息
num = 0 # 初始化一个页码计数器,用于记录翻页次数
for i in range(0,19803):
nr_ex = '//*[@id="tableBody"]' #内容的xpath
ex_diyiye = web.find_element_by_xpath(nr_ex).text.split(' ') #提取出内容
csvwriter.writerow(ex_diyiye) #写入csv文件
num = num + 1
xpath_next = f'//*[@id="layui-laypage-{num}"]/a[7]' #获取下一页的xpath
click_next = web.find_element_by_xpath(xpath_next).click() #定位下一页的xpath
time.sleep(3) # 休息3秒
#同上,作用是最后一页的内容的抓取与写入
nr_ex = '//*[@id="tableBody"]'
ex_diyiye = web.find_element_by_xpath(nr_ex).text.split(' ')
csvwriter.writerow(ex_diyiye)
#关闭文件
ex.close()
1.4 总结
简单的24行代码,即可抓取39万条有用的数据,这便是Python的优势。
以上只是selenium的简单运用,代码的写法也是面向过程,虽然比较繁琐,但是易于理解,除此之外,selenium还有实现“按键”、“拖动滑动条”、“输入”等功能,结合图片识别网站,可以实现例如自动登录、自动发送、抢购等许多功能,在这里只是抛砖引玉,谢谢!
---END---









