转载公众号 | 专知

将人工智能(AI)融入药物发现领域已经成为一个日益增长的跨学科科学研究领域。然而,传统的人工智能模型在处理复杂的生物医学结构(如2D或3D蛋白质和分子结构)和为输出提供解释方面存在严重限制,这阻碍了它们的实际应用。近年来,图机器学习(Graph
Machine Learning,
GML)因其对图结构生物医学数据建模并研究其属性和功能关系的出色能力而获得了相当大的关注。尽管进行了广泛的努力,GML方法仍然存在一些缺陷,例如处理监督稀疏性的能力有限,在学习和推理过程中提供可解释性,以及在利用相关领域知识方面的有效性。作为回应,最近的研究提出将外部生物医学知识整合到GML流程中,以在有限的训练实例下实现更精确和可解释的药物发现。然而,这一新兴的研究方向还没有一个系统的定义。本综述对长期存在的药物发现原理进行了全面的概述,提供了图结构数据和知识数据库的基础概念和前沿技术,并正式总结了用于药物发现的知识增强图机器学习(KaGML)。对相关KaGML工作的彻底回顾,按照精心设计的搜索方法收集,按照新定义的分类法分为四类。为促进这一迅速兴起的领域的研究,还分享了收集的实用资源,这些资源对智能药物发现有价值,并对未来进步的潜在途径进行了深入讨论。
https://www.zhuanzhi.ai/paper/38c4c345af294e069416f7cb6ae2f6d1
1. 引言
药物的发现和开发是几十年来最突出和最具挑战性的研究任务之一[1,2,3]。一种药物在上市和分发给患者之前,必须经过大量的研究验证。从最初的早期药物发现到临床前开发,再到临床试验和最终的监管批准,通常需要10-15年的时间,成本约20亿美元[4,5,6]。药物开发过程通常从早期药物发现过程中与特定疾病相关的目标蛋白或核酸的识别开始。接下来是识别小分子或生物药物(如抗体或蛋白质),它们将与靶点相互作用并调节其活性,以达到治疗或预防疾病的目的。在小分子的情况下,进行高通量筛选实验以识别有希望的化合物,这一过程被称为“命中识别”。从这些化合物中,通过体外和体内试验选择一些化合物,并进行化学优化,以提高稳定性、亲和力或溶解度等性能,从而产生“先导”化合物。经过几轮结构优化后,先导分子成为候选药物,并可以继续在动物身上进行临床前研究,然后在人类身上进行临床研究。理想的药物应该是无毒的,对患者的副作用尽可能少,同时与靶点具有可溶性和有效的相互作用。这个过程的每一步都有很高的失败率和巨大的成本。
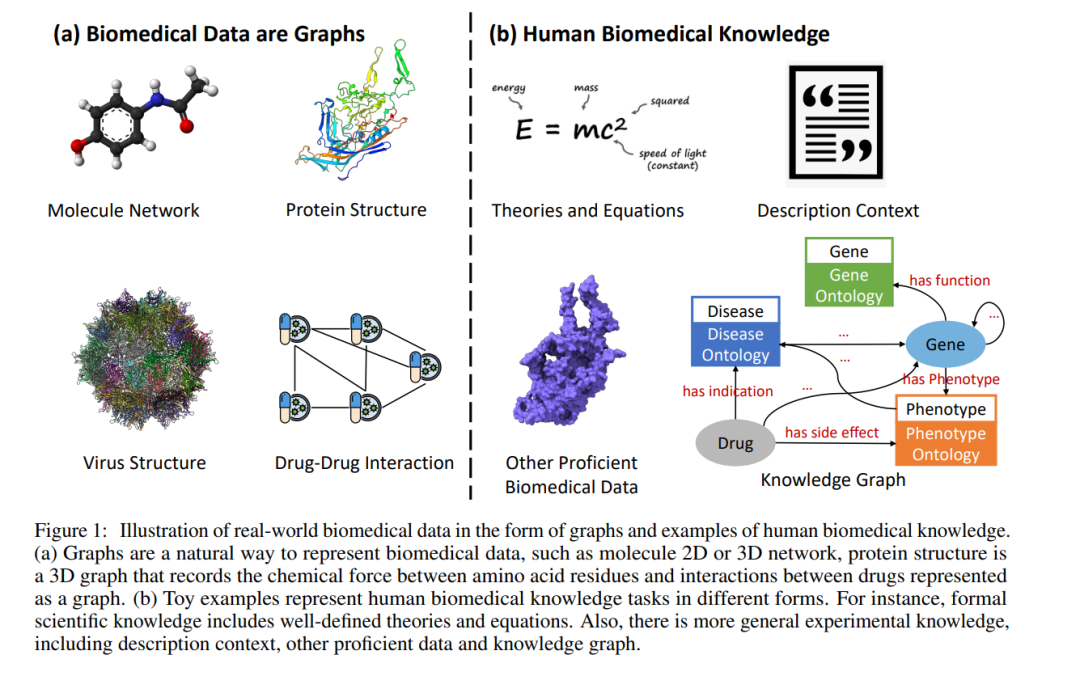
为了减少财政负担和提高成功率,研究人员一直致力于通过利用卓越的人工智能(AI)技术来加速药物发现[7,8,9,10,11]。现在的技术进步允许在基因组学、蛋白质组学和成像等领域创建大量数据,这些数据可用于告知药物发现过程[9,12]。人工智能可以分析这些数据,并识别在其他情况下可能不引人注意的模式和关系,从而识别新目标并优化现有目标[13,8]。基于人工智能的药物发现也被用于通过预测候选药物成功的可能性来简化药物开发过程,减少将新药推向市场所需的时间和成本[10,14]。此外,人工智能被用于预测潜在的副作用和毒性,以便在临床试验之前识别潜在的安全问题[15,11]。随着这些进步,人工智能有可能改变药物发现过程[7],使药物开发更快、更有效,并更快地为患者带来新疗法。生物医学数据是高度互联的[16,17],可以很容易地表示为图(或网络),在药物发现和开发过程的不同阶段具有各种应用。例如,如图1-(a)所示,生物医学数据可以层次地表示为图形。从分子水平开始,原子可以表示为节点,化学键表示为(2D或3D)分子图的边[18,19]。在大分子水平上,氨基酸残基(节点)之间的相互作用(边)以(2D或3D)蛋白质图的形式组织[20,21]。在化合物水平上,药物-药物相互作用(DDI)网络中的边可以指示通过长期临床筛查测量的药物(节点)之间的化学相互作用(边)[22,23]。
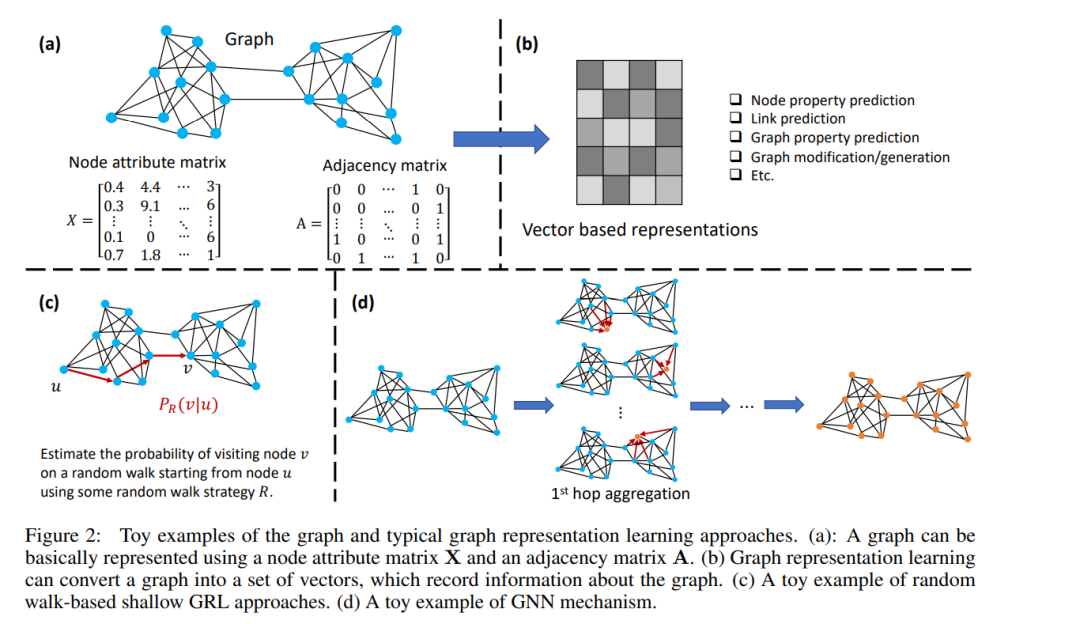
然而,传统的AI工具很难处理复杂的图结构数据。机器学习模型使用的特征提取器通常是不可迁移的,需要为每个特定的数据集和任务手动设计。尽管深度学习模型[24,25,26]具有从原始数据中学习的能力,但它们处理复杂图结构的能力仍然有限。为此,人们提出了一类新的人工智能方法——图机器学习(GML)来研究图结构数据。GML的基本思想是学习节点(如DDI网络中的药物)、边(如药物-药物或药物-疾病之间的关系或相互作用)或(子)图(如分子图)[27]的有效特征表示。这些对应的节点、边缘和(子)图级下游任务可以基于这些学习到的表示来实现。根据表示学习机制的不同,GML方法可以大致分为"浅层"和"深层"两类。特别是,一种称为图神经网络(GNNs)的深度GML方法[28,29,30,31,32],这是专门为图结构数据设计的深度神经网络架构,正在吸引越来越多的兴趣。gnn通过传播邻近节点的信息来迭代更新图节点的特征。这些方法已经成功应用于一系列任务和领域,包括药物发现[16,33,34]。
然而,尽管目前GML在药物发现方面进展迅速,但它们存在一些严重缺陷,包括高度的数据依赖性(即强大的性能依赖于高质量的训练数据集)[35,36]和较差的泛化性(即模型对从未在训练数据中观察到的实例的性能不确定)[37,38]。这些不足主要源于模型的数据驱动性质和不能有效利用领域知识。此外,对于帮助人们理解和解释基础模型并提供更多可信性的方法的需求也有所增加。为了缓解某些机器学习模型缺乏可解释性和可信性的问题,并增强人类的推理和决策能力,人们开始关注可解释人工智能(XAI)[39]和可信任人工智能(TAI)[40]方法,它们为模型的内在机制和输出提供人类可理解的解释。为解决这些限制,研究人员最近关注了一种新的人工智能范式,称为知识增强图机器学习(简称KaGML),用于更好的药物发现。其核心思想是将外部的人类生物医学知识集成到GML流程的不同组件中,以实现更准确的药物发现,以及用户友好的解释,这保证了专家的知识不会被取代。生物医学知识可能以各种形式存在,如图1-(b)所示,包括正式的科学知识(例如,在一个领域中已经确立的、支配目标变量的属性或行为的定律或理论),非正式的实验知识(例如,从长期观察中提取的众所周知的事实或规则,也可以通过人类的推理推断)。本综述的贡献如下:
我们是第一个提出KaGML概念并全面总结现有工作的人。KaGML与现有其他范式之间的讨论强调了KaGML的新颖性及其在实际医疗应用中的潜力。
根据不同的方案提出了一种新的KaGML方法分类,将知识纳入GML流程。让读者更容易识别不同模型的核心设计,找到感兴趣的类别(第5节)。我们创建了一个公共文件夹来分享收集到的资源,并将继续为之贡献力量。
我们仔细讨论了KaGML方法已经(或极有可能)用于解决实际药物发现问题的实用工具和知识库(第6部分)。我们提供了一种可能方案的示意图,以将不同的小分子药物知识库组织到一个知识图谱中。不仅涵盖计算机科学场景下解决科学问题的方法,更重要的是,涵盖现实世界中的生物医学应用。因此,我们的调查不仅引起了人工智能研究人员的兴趣,也引起了不同领域的生物学家的兴趣。第7节讨论了来自两个学科的研究人员可以利用的有希望的未来工作。
面向药物发现的知识增强图机器学习
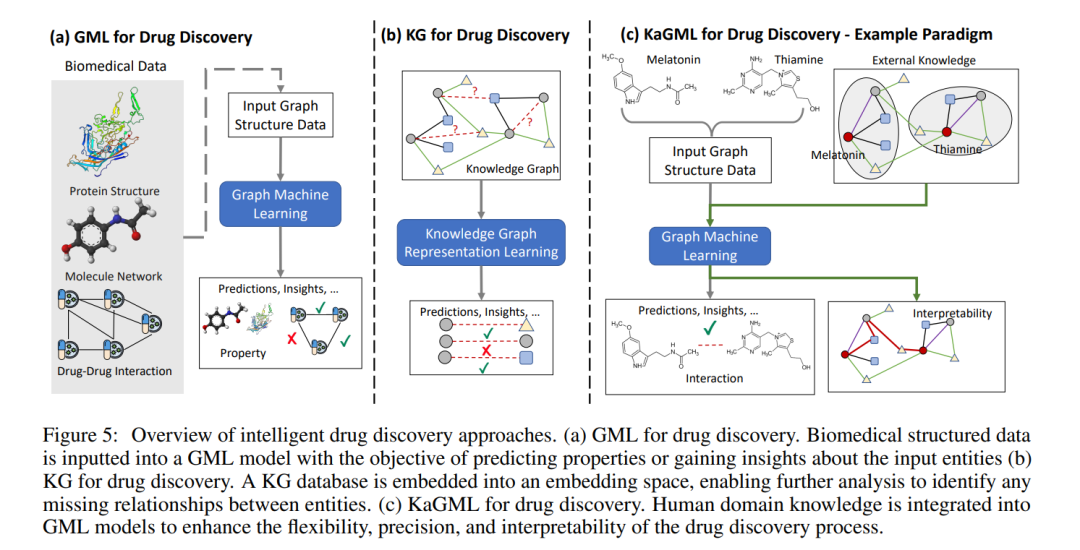
图5展示了本研究的重点,各种智能药物发现方法。对左图(药物发现的GML,框1)和中间图(药物发现的KG,框2)的相关技术进行了简要讨论,并在4.2-
4.3节介绍了它们在药物发现中的重要应用。然而,某些重大的局限性,如依赖显式的图结构和丰富的训练信号、受限的理论表达能力和缺乏可解释性,阻碍了它们在现实中的应用[16,116]。今天,外部生物医学知识被广泛地与GML方法结合起来,以更有效地进行药物发现和开发。本文将这种新机制命名为知识增强图机器学习(简称KaGML),到目前为止,它在以下方面表现出了有希望的结果:(i)实现更精确的药物发现(第5.1-5.3节);(ii)灵活使用非结构化训练数据(第5.1-5.2节);(iii)有效处理有限的训练数据(第5.2-5.3节);(iv)自动生成有意义的解释(第5.4节)。
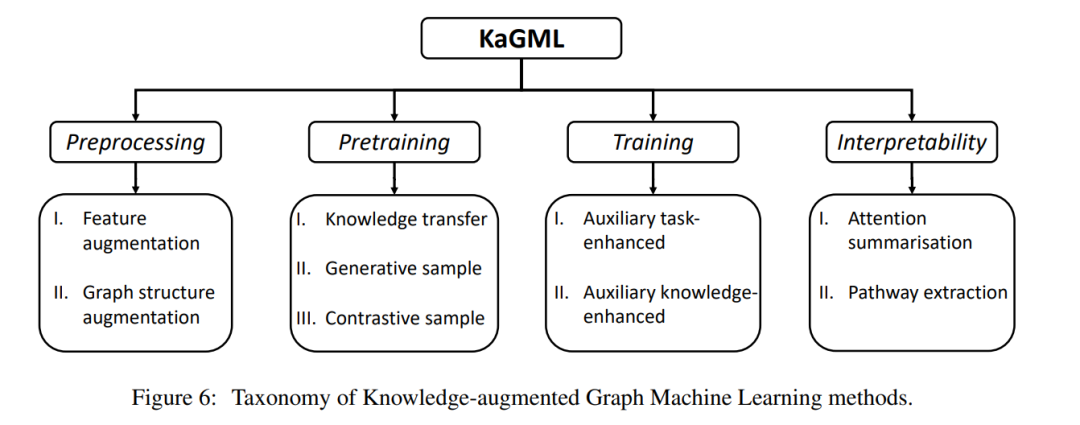
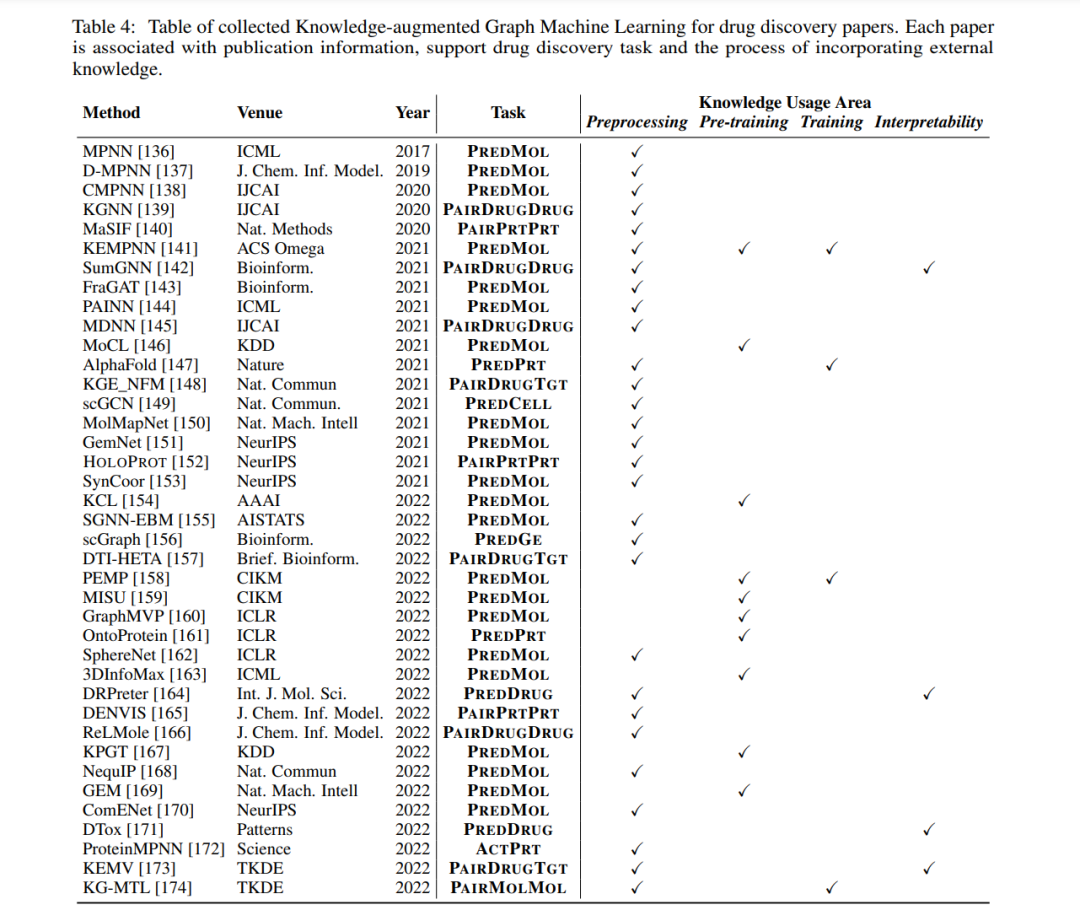
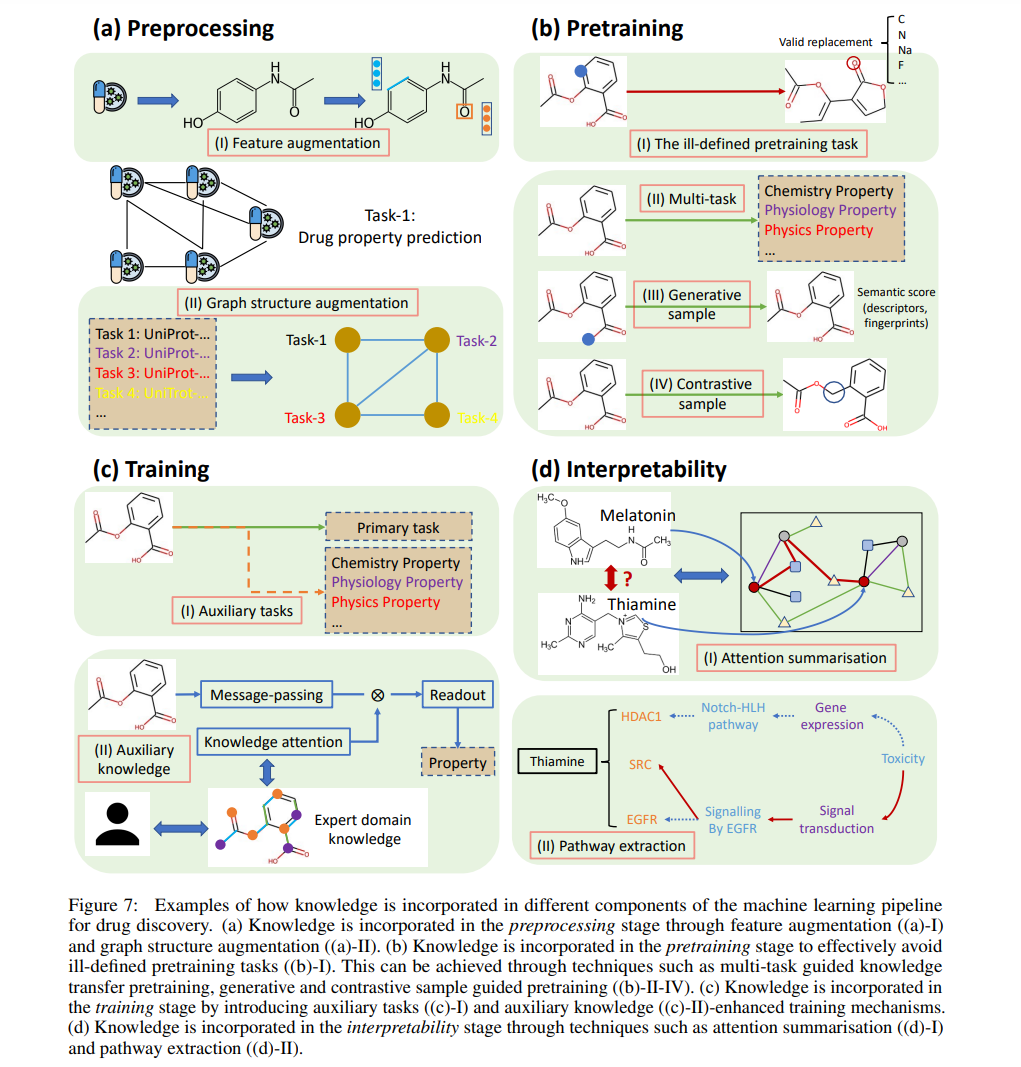
下一节将全面介绍KaGML的基础知识。此外,根据图6所示的分类法,我们将KaGML模型分为四类,包括预处理、预训练、训练和可解释性。(ii)知识增强的预训练策略有助于GML方法的实现;(iii)外部知识可以加快GML的训练过程;(iv)知识库已成为可靠的资源,为GML模型提供有意义的可解释性。每一类的工作将被详细讨论。为了便于对文献的理解,表4对KaGML中用于药物发现的文献进行了汇总,列出了它们的发表信息,以及利用外部知识进行药物发现的方法。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。










