【新智元导读】模型不open?没关系,亚马逊云科技帮你open。官宣Bedrock平台,定制芯片打下训练推理成本,生成式AI竞赛,越来越精彩了。
如火如荼的AI竞赛,亚马逊云科技也下场了。
有些不同的是,除了自己构建的AI模型,他们还招募第三方在亚马逊云科技上托管模型。
凭借这个叫Amazon Bedrock的平台,亚马逊云科技正式进军生成式AI赛道。
在极优性能的云基础设施上,大规模运行生成式AI应用,毫无疑问,亚马逊云科技在掀起一场颠覆性变革。
过去的十多年里,人工智能领域大部分研究集中在训练神经网络来完成一项特定的任务。
比如在CV中,图像分类、分割、或者识别图中是否是一只猫;在NLP中,语义检索、翻译等等。

直到ChatGPT的横空出世,甚至可以说最早从Stable Diffusion开始,生成式AI的能力逐渐打破人们原有的认知。
在大模型加持下的AI工具,不仅能创造新颖的内容,还能够生成图片、视频、音乐,以往它从未见过的东西。
研究者发现,当参数量足够多,或者达到一定规模时,大模型就会出现一种不可预测现象,也就是「涌现」能力。
随着机器学习进步,特别是基于Transformer的神经网络架构,使得开发数十亿参数规模的FMs成为可能。
正是GPT-3、DELL-E、GPT-4等超大模型兴起,让语言模型的训练范式发生了重大变化。
模型训练过程不再过度依赖显性标注,能够根据句子中已有单词,预测一下词,实现了智能体的认知能力进步。
其实,这些大模型就是李飞飞等人在2021年提出的「基础模型」(Foundation Models)。
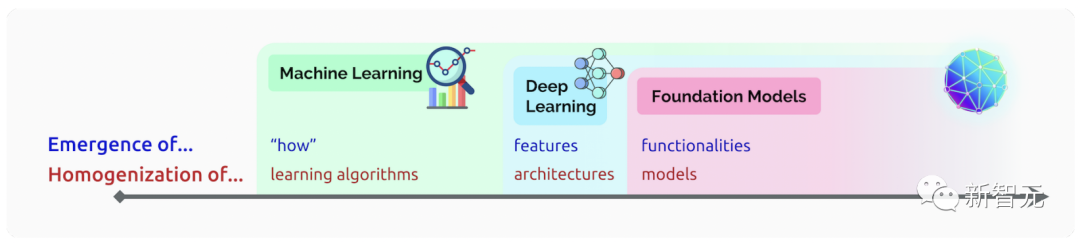
因为在大量的数据上进行了预训练,基础模型已具有了高度适应性,能够完成一系列下游任务。
基础模型的优势就在于,可以被用于微调的特定领域,或者创建一个业务模型的起点。在理解数行为方面,FM当然是最好的。
微调模型,就需要在特定数据集(有标注)进一步训练而来的模型。
而这种数据集是解决特定任务所需的,因为大模型只能做到「很懂」,但不能做到「很专」。
微调后的模型结合了2点优势:一是对数据结构的理解,再一个是通过标注数据的形式了解业务问题的背景。
这样一来,微调后的模型同样能够实现,在特定领域生成类人的文本或图像。
就比如,彭博推出了金融领域专用的500亿参数大模型BloombergGPT。

由此可见,基础模型是生成式AI的关键,是AIGC的基石。
当下,整个业界呼声最高的便是,哪里有大模型可用。
我们都知道,训练一个超大规模的语言模型,同样离不开三驾马车:算法、算力、数据。
而且还需要的是超强算法、超大算力和数据。

就拿训练ChatGPT来说,微软曾揭秘了为OpenAI斥资数十亿美元,用了3万多个英伟达A100打造超算。
为了摆脱这一困境,报道称微软早在2019年开始,就投入300人团队自研芯片Athena。
数据方面,虽然现在仅依靠少样本数据来训练模型,但数据可用性也是一大难题。
最近,纽约时报称,Reddit便开始计划向使用平台数据训练模型的公司收费,其中就包括微软、谷歌、OpenAI等公司。

而要训练出真正优秀的大语言模型,不仅需要耗费资本,还需要足够多的时间。2022年,GPT-4模型训练完成后,还用了6个月的时间,进行了微调和测试。
这也恰恰解释了为什么大多数公司都想用大型语言模型,但又不想投入太多成本。只想借用基础模型泛化能力,用自己特定领域的数据,去微调模型。
对此,亚马逊云科技做了大量的用户调研后,发现客户的主要需求是——
1. 需要一个简单的方法来查找和访问高性能基础大模型,既要提供出色的结果,也要符合自己的目标。
2. 需要模型能够无缝地集成到应用程序中,而不必管理庞大的基础设施集群或产生大量成本。
3. 希望能够轻松获得基础大模型,并使用自己的数据(少量或大量数据)构建差异化应用。
由于客户希望用于定制的数据是非常宝贵的IP,因此他们需要在此过程中保持完全的保护、安全和隐私,并且他们希望控制其数据的共享和使用方式。
为了解决这些问题,亚马逊云科技认为,应该让生成式AI技术变得普惠起来。
也就是说,AIGC并不独属于少数初创公司和资金雄厚的大厂,而是要让更多公司从中受益。
于是,一个名为Bedrock的基础大模型云服务,便应运而生了。
而Bedrock也是亚马逊云科技在生成式AI市场上最大的一次尝试,根据Grand View Research的估计,到2030年,该市场的价值可能接近1100亿美元。
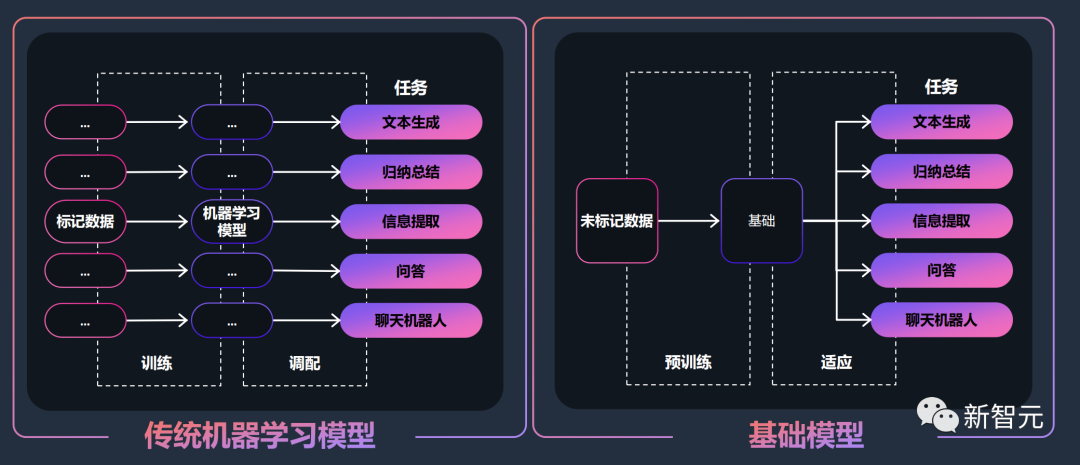
值得一提的是,Bedrock最重要的特色,就是让开发者能够轻松定制模型,并构建属于自己的生成式AI应用程序。
在训练时,Bedrock会为开发者创建一个基础模型的副本,并对此私有副本进行训练。其中,所有的数据都经过加密的,并且不会离开虚拟专用云(VPC)。此外,这些数据也不会被用来训练底层大模型。
此外,开发者还可以通过在Amazon S3中提供一些标注示例来为特定任务微调模型,无需大量个人数据就能产生比较满意的结果。
更重要的是,Bedrock可以与平台上其他的工具和功能配合使用,这意味着开发者无需管理任何额外的基础设施。

自研「泰坦」+第三方SOTA模型
具体来说,Bedrock主要包含两部分,一个是亚马逊云科技自己的模型Titan,另一个是来自初创公司AI21 Labs、Anthropic,以及Stability AI的基础模型。
基础模型具体包括:
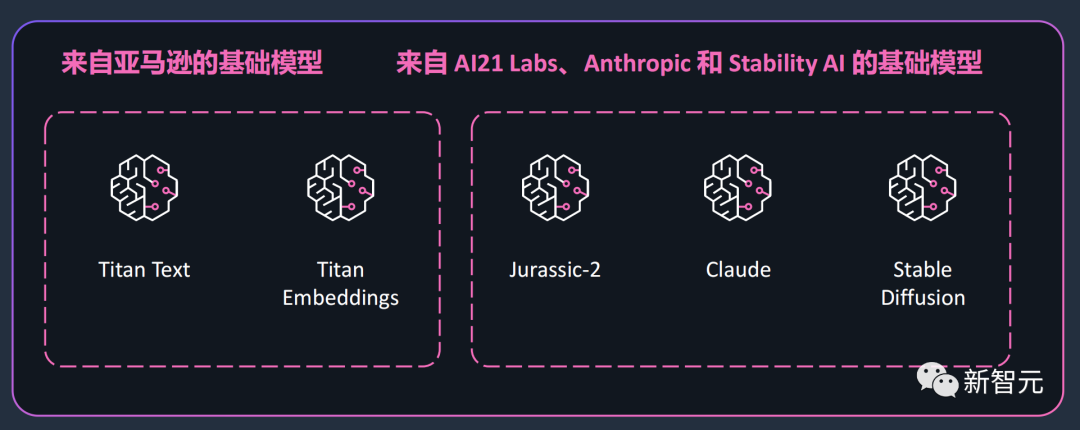
Titan基础模型的构建是基于亚马逊云科技在机器学习领域20多年的经验。Titan包含了两个大语言模型,一个是用于生成文本的Titan text,一个是让网络搜索个性化的Titan Embeddings。Titan text针对的是总结、文本生成、分类、开放式问答和信息提取等任务。文本嵌入Titan Embeddings模型,能够将文本输入(字词、短语、大篇幅文章)翻译成包含语义的数字表达(embeddings嵌入编码)。用户可以通过自己的数据定制Titan模型。并且,亚马逊云科技非常保护用户数据隐私,不会将用户数据拿来再训练Titan模型。而且,不同于其他大模型时常会出现的「幻觉」,Titan在训练时非常关注精度,就是为了保证产生的响应一定是高质量的。除了亚马逊云科技的Titan模型,开发者们还可以利用其他的基础模型。其中包括AI21 Labs开发的Jurassic-2多语种大语言模型系列,能够根据自然语言指令生成文本内容,目前支持西班牙语、法语、德语、葡萄牙语、意大利语和荷兰语。还有Anthropic开发的大语言模型Claude,能够执行多轮对话和文本处理任务。第三个基础模型便是Stability AI的文本图像生成模型Stable Diffusion。通过这些模型,开发者只用20个样本,就能一键定制自己的模型。举个例子,一位营销经理想为手提包新品开发广告创意,他只需向Bedrock提供标注过的最佳广告,以及新品描述,Bedrock就能自动生成媒体推文、展示广告和产品网页。同样的,所有数据都进行了加密,任何客户数据都不会被用于训练底层模型。目前,Coda AI、Deloitte、埃森哲、Infosys等合作伙伴已经用上了Bedrock。AIGC爆发,云服务供应商需求猛增
随着相关技术的演进,各行各业对于AIGC内容的需求也在不断增加,从营销到客服,再到新闻和娱乐等等。这对于那些提供基础设施服务的供应商来说,是一个非常好的机会。根据Gartner的预测,到2025年,AIGC数据将占到所有数据的10%,而目前这一比例还不到 1%。为了在这个领域占据一席之地,微软和谷歌相继推出了基于自家模型的云服务——前者高调宣布将ChatGPT整合进Azure OpenAI Service,而后者也在Google Cloud上推出了企业级生成式AI工具。相比之下,亚马逊云科技在Bedrock中搭载的模型则更加丰富,不仅有自研的泰坦,还有来自其他初创公司的开源模型。而且,据称还会有更多的模型加入其中。凭借其灵活性和定制选项、以及对隐私的承诺,Bedrock更能迎合不同行业的独特需求。
现在模型虽然有了,但为了能让更多人用上,其训练和推理的成本还需要进一步降低。其中,包括Inferentia2和Trainium,可以让客户在进行机器学习工作时,将成本降到很低。与其它EC2实例相比,由Trainium支持的Trn1计算实例可以节省高达50%的训练成本。并且经过优化,可以在与高达800Gbps的第二代EFA(弹性结构适配器)网络相连的多个服务器上分发训练任务。800 Gbps是一个很大的带宽,但亚马逊云科技还宣布新的网络优化Trn1n实例的普遍可用性。它提供1600 Gbps的网络带宽,旨在为大型网络密集型模型提供比Trn1高20%的性能。除了训练需要大量算力,当基础模型进行大规模部署时,每小时进行数百万次推理请求也需要大量成本。亚马逊云科技曾在2018年发布了首款推理专用芯片Inferentia,已经运行数万亿次推理,并节省数亿美元成本。与上一代相比,Inf2实例不仅吞吐量提高了4倍,延迟降低了10倍,还可实现加速器之间的超高速连接以支持大规模分布式推理。前段时间发布的最新文本生成视频模型Gen-2的公司Runway,有望利用Inf2将部分模型的吞吐量提升至原来的2倍。
20多年来,人工智能和机器学习一直是亚马逊云科技关注的焦点。可以说,在机器学习领域的发明创新已经深深刻在亚马逊云科技的DNA里。当前,用户在亚马逊云科技上使用的许多功能都是由其机器学习驱动的,比如电子商务推荐引擎、优化机器人拣选路线、无人机Prime Air。还有语音助手Alexa,由30多个不同的机器学习系统驱动,每周回应客户数十亿次管理智能家居、购物、获取信息和娱乐的请求。截至目前,已经有10万客户在使用亚马逊云科技机器学习的能力进行创新。亚马逊云科技在人工智能和机器学习堆栈的三个层级都拥有至深至广的产品组合。通过不断投入、持续创新,亚马逊云科技为机器学习提供高性能、可伸缩的基础设施,和极具性价比的机器学习训练和推理;另外,Amazon SageMaker为所有开发人员构建、训练和部署模型提供最大的便利;亚马逊云科技还推出大量的服务,用户可以通过简单的API调用就可添加AI功能到应用程序中,如图像识别、预测和智能搜索。同样,在生成式AI技术上,亚马逊云科技也要迈出重要的一步,让这项技术也要赋能千行百业。
亚马逊云科技所做的就是,将基础模型的能力让许多客户能够访问、为机器学习推理和训练提供基础设施、让所有开发人员提高编码效率。此前,亚马逊云科技曾与Hugging Face和Stability AI等公司合作,但从未透露发布本土大语言模型的计划。但亚马逊云科技数据库、机器学习和分析副总裁Swami Sivasubramanian表示,公司长期以来一直致力于大语言模型,而LLM早就被用来帮助购物者在亚马逊云科技的零售网站上搜索产品,以及支持Alexa语音助手等应用。亚马逊云科技在生成式AI上的几项创新只是一个开始。这是一场技术革命的早期阶段,并将持续几十年。在这个最新的节点上,亚马逊云科技将通过自身创新降低AI的门槛,进而赋能千行百业。据可靠消息:5月25日将举办亚马逊云科技大模型及生成式AI发布深度解读大会,敬请期待。戳下方链接或点击文末「阅读原文」,可进行大会报名。https://www.awsevents.cn/innovate/ai2023/registerSignUp.aspx?s=8440&smid=17578









