Meta AI开源的大羊驼LLaMA模型彻底点燃了开源社区的热情,并在此基础上相继开发出了各种类ChatGPT的羊驼Alpaca, Vicuna等。
但Meta只是开源了LLaMA的权重,训练用到的数据集并没有开源出来,对于那些想从头开始训练LLaMA的从业者来说,目前还没有开源方案。
最近,由Ontocord.AI,苏黎世联邦理工学院DS3Lab,斯坦福CRFM,斯坦福Hazy Research 和蒙特利尔学习算法研究所的宣布开启「红睡衣」(RedPajama)计划,旨在生成可复现、完全开放、最先进的语言模型,即从零一直开源到ChatGPT!
下载地址:
https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T
预处理仓库:https://github.com/togethercomputer/RedPajama-Data
「红睡衣」开源计划总共包括三部分:
1. 高质量、大规模、高覆盖度的预训练数据集;
2. 在预训练数据集上训练出的基础模型;
3. 指令调优数据集和模型,比基本模型更安全、可靠。

目前红睡衣计划中的第一部分,即预训练数据集RedPajama-Data-1T已开源,包括七个子集,经过预处理后得到的token数量大致可以匹配Meta在原始LLaMA论文中报告的数量,并且数据预处理相关脚本也已开源。
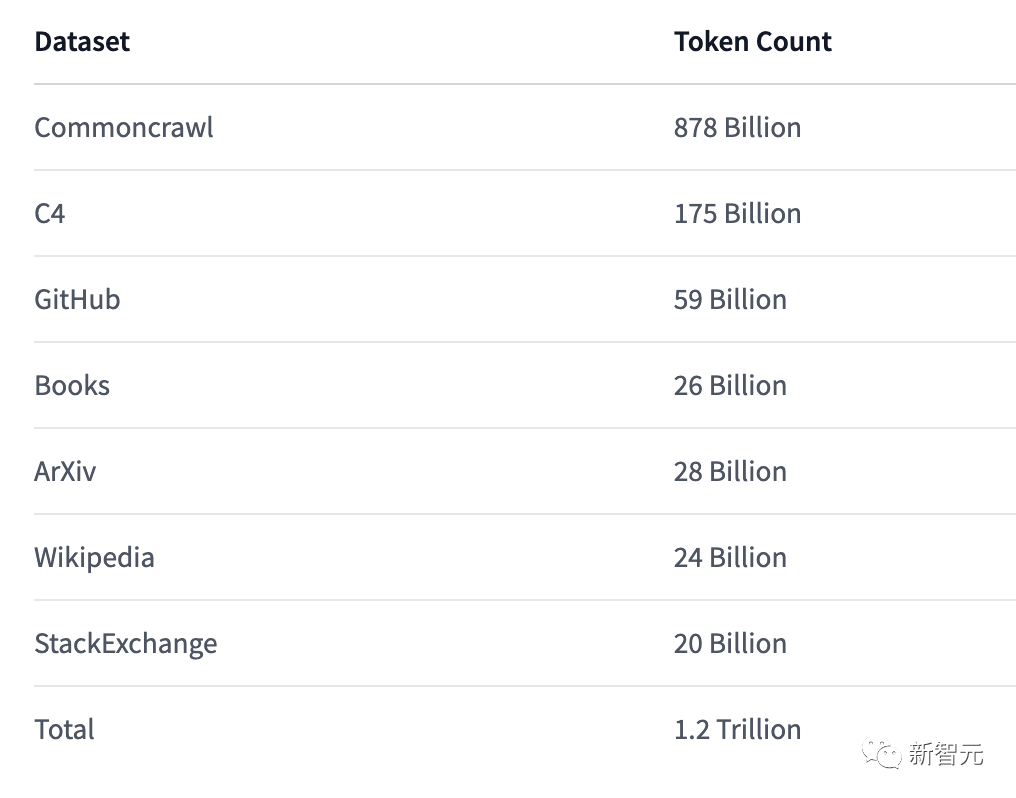
完整的RedPajama-Data-1T数据集需要的存储容量为压缩后3TB,解压后5TB,有条件、有网速的小伙伴可以开始搞起来了!
目前开发团队正在橡树岭领导计算设施(OLCF)的支持下开始训练模型,预计几周后即可开源。
通过OpenChatKit,研究人员已经收到了数十万条高质量的自然用户指令,将用于发布 RedPajama 模型的指令优化版本。
2023年2月27日,Meta推出LLaMa并发布了相关论文。

论文链接:https://arxiv.org/pdf/2302.13971.pdf
LLaMa实际上是一组基础语言模型的统称,其参数范围从70亿到650亿不等,其中LLaMA-13B(130亿参数)版本甚至在大多数基准测试中都优于1750亿参数的GPT-3;最大的LLaMA-65B和Chinchilla-70B和PaLM-540B相比也不落下风。
和之前的大模型不同的是,LLaMa完全使用「公开数据集」就达到了SOTA,并不存在其他模型中「不可告人」的秘密,无需使用专用或只存在于虚空中的数据集。
具体使用的数据集和预处理操作如下。
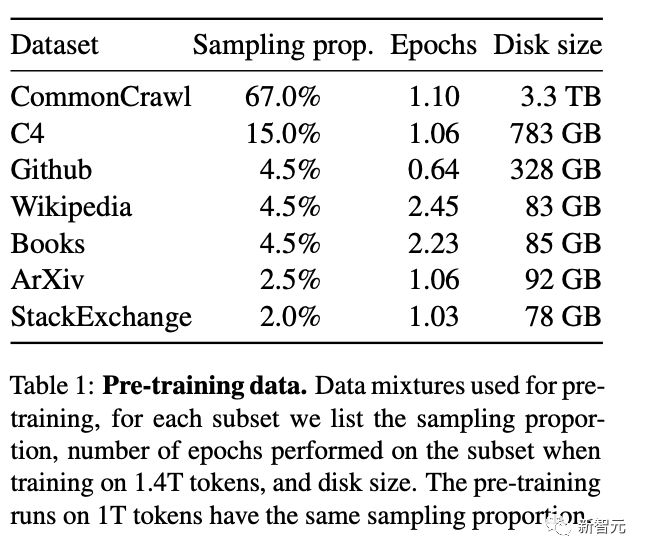
English CommonCrawl-占比67%
使用CCNet pipeline对五个CommonCrawl dumps(2017-2020年)进行预处理,删除重复的行,并用fastText线性分类器进行语言分类,去除非英语页面,并用ngram语言模型过滤低质量内容。
还训练了一个线性模型来对维基百科中用作参考文献的页面与随机采样的页面进行分类,并去除未被分类为参考文献的页面。
C4-占比15%
在探索实验中,研究人员观察到使用多样化的预处理CommonCrawl数据集可以提高性能,所以将公开的C4数据集纳入我们的数据。
C4的预处理也包含重复数据删除和语言识别步骤:与CCNet的主要区别是质量过滤,主要依靠启发式方法,如是否存在标点符号,以及网页中的单词和句子数量。
Github-占比4.5%
使用谷歌BigQuery上的GitHub公共数据集,只保留在Apache、BSD和MIT许可下发布的项目。
然后用基于行长或字母数字字符比例的启发式方法过滤了低质量的文件,并用正则表达式删除了HTML boilerplate(如
最后在文件层面上对所生成的数据集进行重复计算,并进行精确匹配。
维基百科-占比4.5%
数据集中添加了2022年6月至8月期间的维基百科dumps,涵盖20种语言,包括使用拉丁字母或西里尔字母的语言,具体为bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk;然后对数据进行预处理,以去除超链接、评论和其他格式化的html模板。
Gutenberg and Books3-占比4.5%
训练数据集中包括两个书籍相关的语料库,Gutenberg Project为公共领域的书籍;ThePile中Books3部分是一个用于训练大型语言模型的公开数据集。
预处理操作主要是删除重复内容超过90%的书籍。
ArXiv-占比2.5%
通过处理arXiv的Latex文件将科学数据添加到训练数据集中,删除了第一节之前的所有内容,以及书目;还删除了.tex文件中的注释,以及用户写的内联扩展的定义和宏,以提高不同论文的一致性。
Stack Exchange-占比2%
Stack Exchange是一个高质量问题和答案的网站,涵盖了从计算机科学到化学等不同领域。保留了28个最大网站的数据,删除了文本中的HTML标签,并按分数(从高到低)对答案进行了排序。
分词器(Tokenizer)
根据SentencePiece的实现使用字节对编码(byte-pair-encoding,BPE)算法对数据进行分词,其中连续的数字被分割成单个数字。
最终整个训练数据集在分词后获得了大约1.4T的tokens,除了维基百科和图书数据外,其他的数据在训练期间只使用一次,总共进行了约两个epochs








