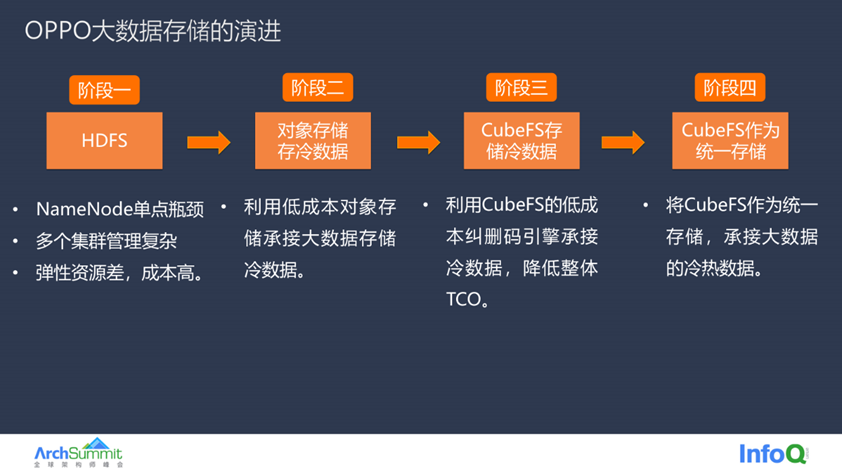
大数据的存储过程也可以分为四个阶段,
大数据最开始使用 HDFS 存储也面临了一些挑战。
首先是 HDFS 集群数目多,如下图所示,只是大数据业务的一部分 HDFS 集群,除了集群数量多之外,多个集群的存储空间资源紧张,需要集群间不断腾挪机器来满足日益增长的存储需求。并且 HDFS 集群采用的是存算混合机型,这种机型单位存储成本高、能耗大,所以这一阶段面临的主要是存储成本过高、集群管理复杂的问题。
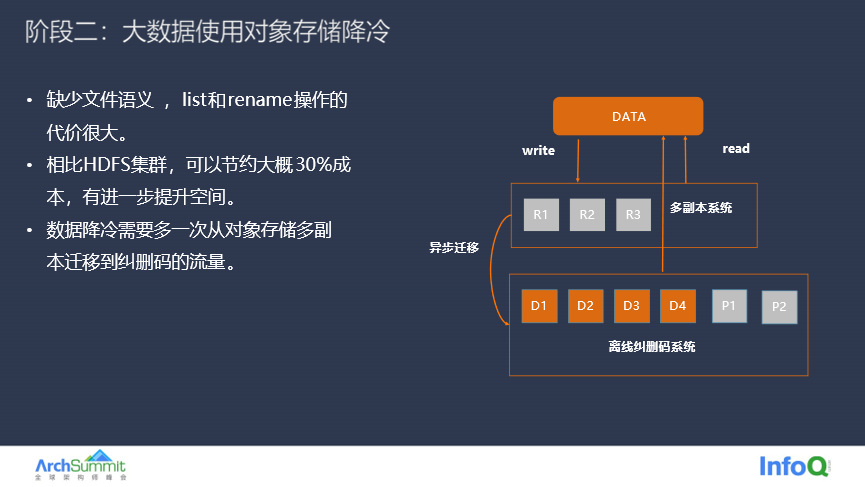
第二阶段主要采用对象存储保存大数据的冷数据,这个阶段会将大数据的冷数据迁移到对象存储中,依靠对象存储的低成本优势来解决大数据业务面临的成本问题。但是对象存储承担大数据的冷数据有个天然的问题,就是不支持文件语义,业务的 list 和 rename 操作时候代价非常高昂,rename 操作需要先对数据做 copy 然后再删除旧的数据,整个过程代价极高。
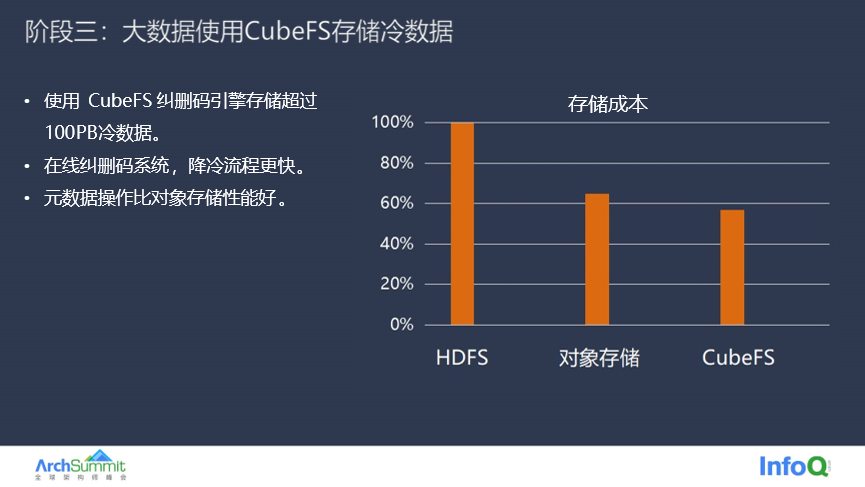
第三阶段是基于 CubeFS 的来存储大数据冷数据,CubeFS 不仅能够提供低成本的存储,本身也支持文件语义。目前已经使用 CubeFS 存储超过 100PB 的大数据冷数据,整体存储成本比使用 HDFS 节约 40% 以上,即使比使用对象存储的成本也有所下降,并且整个降冷过程更快、更节约资源。

最后一个阶段是使用 CubeFS 作为统一存储,冷数据采用 CubeFS 低成本、高可靠的纠删码引擎,热数据采用 CubeFS 三副本引擎。CubeFS 统一存储可以支持更大 IO 并发需求,例如 Flink 的 check point 集群,需要定期将任务持久化到存储,会产生很多频繁大 IO 请求,小规模的 HDFS 集群需要靠扩容解决,导致集群整体存储利用率不高,存储成本增加,而使用 CubeFS 统一存储,可以提升整体存储利用率并且能够满足大 IO 的要求。
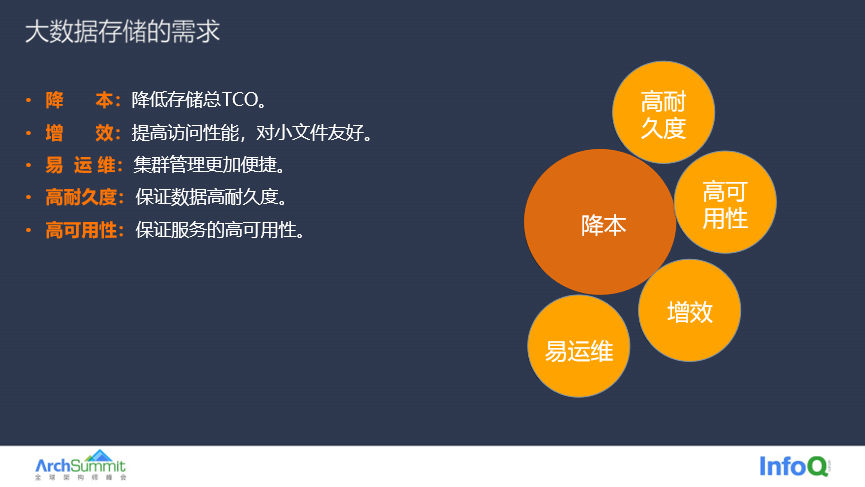
大数据业务经历了这个四个阶段的存储演进,简单来说,大数据存储目前的需求就是以下几点。最核心的需求就是降本增效,这个也是目前很多公司的关键目标,在降本增效的同时需要保证系统的可用性、数据的可靠性以及运维的便捷性。
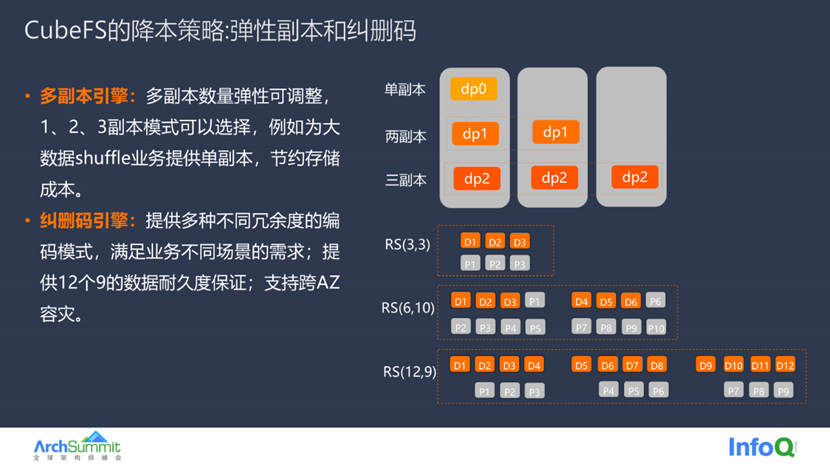
关于 CubeFS 如何助力大数据降本,第一个策略是从数据冗余度出发, CubeFS 本身提供了弹性可变的副本机制,用户可以根据业务特性选择特定数量的副本数目。举个例子,大数据的 Shuffle 业务产生的是临时数据,这个业务场景很适合采用单副本存储来节约存储成本。
除了弹性副本之外还可以采用低成本的纠删码,不同冗余度的编码支持可配,用户可以根据对数据耐久度的需求来选择合适的编码,例如可以选择支持 AZ 级别容灾的编码,在降低数据冗余度的同时兼顾数据可靠性。

除了软件层面的降本之外,CubeFS 技术团队还在硬件层面做了降本优化,这里主要是选择一些高密的存储服务器,高密存储服务器单位存储量的成本和功耗都更低,整体的存储成本也更低。
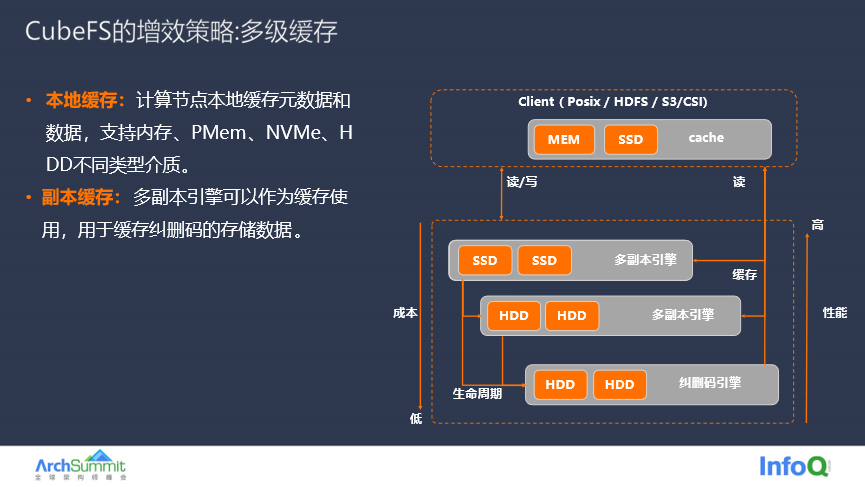
除了节约存储成本之外,CubeFS 技术团队也特别关注大数据存储的性能,通过多级缓存技术可以在 Client 节点上同机部署 BlockCache 组件,在内存缓存元数据,利用本地磁盘来缓存数据,元数据和数据就近访问可以提升数据的读性能,当然由于本地磁盘容量有限,需要配置一定的缓存淘汰策略。
本地缓存之外还有全局缓存,如果业务对缓存容量需求更大,可以使用多副本 DataNode 作为缓存,例如利用 DataNode 作为全局缓存,相比本地缓存,全局缓存容量很大,并且副本数目可以调整。
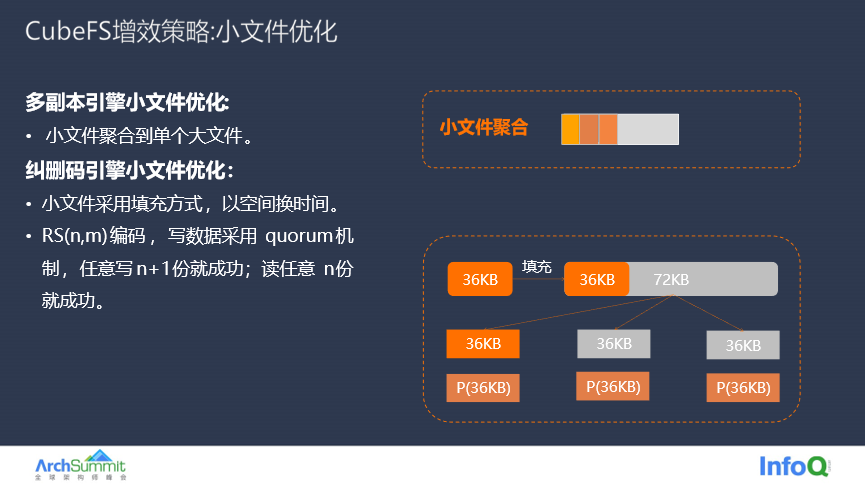
除了利用多级缓存做优化之外,CubeFS 对小文件也有特定的优化,在前面机器学习的场景有提到过,机器学习主要通过缓存元数据的 inode 和 dentry 来优化读性能。其实多副本引擎的小文件会聚合到一个大文件中,小文件聚合会减少 DataNode 管理的文件数量。纠删码引擎写入小文件会采用填充的方式,这样小文件读取时候只访问第一块数据,可以避免跨 AZ 的读流量。顺便提一点,纠删码的读写采用 quorum 机制,RS(n,m) 的编码任意写 n+1 份(这里 +1 还是加几可以配置)就成功,读任意 n 份就返回成功,这样可以有效避免长尾的时延问题。
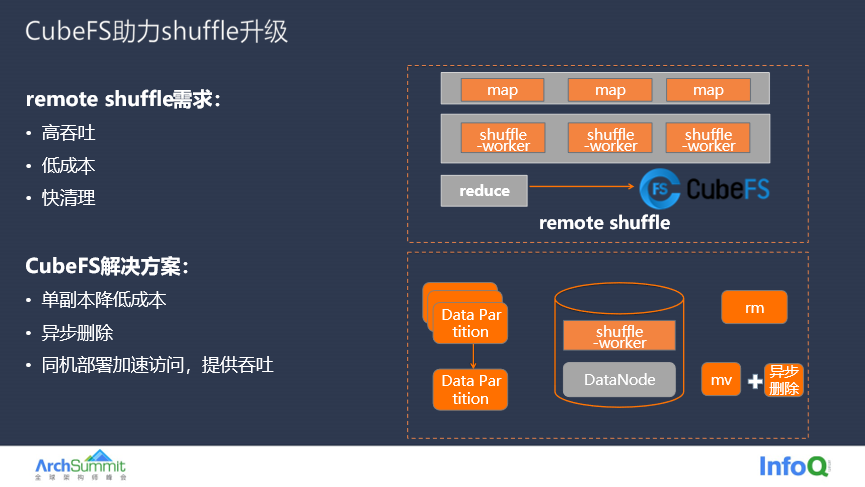
下面是一个大数据热数据在 CubeFS 的应用实例分享,传统大数据的 shuffle 任务中 map 和 shuffle-work 是同机部署,这样 shuffle-work 读写数据会抢占 CPU 资源,另外由于单机存储的空间有限,可能因为任务分配资源不均衡等问题导致任务失败。remote shuffle 是 OPPO 大数据团队开源的一个项目,将 shuffle-worker 与 map 解绑,在云上部署 shuffle-worker,使用分布式存储 CubeFS 存储 shuffle 过程中产生的临时文件。Shuffle 过程产生的是临时数据,即使数据丢失可以重新生成任务,对数据可靠性要求不高,更加关注成本;临时数据需要快速清理;另外 shuffle 对数据读写的吞吐量和性能要求较高,在多任务并行场景对读写带宽需求较大,测试过程中会发现经常能把网卡、磁盘打满导致机器负载整体能够达到 80% 以上。
针对这些存储特点,CubeFS 提供以下的解决方案:
提供单副本存储,虽然会存在坏盘会导致数据丢失,但是就像上面所说, Shuffle 场景下产生的是临时数据,数据丢失后任务可以重做,代价就是任务时延增加,相比于正常情况下性能提升和成本降低,这是一个合理的权衡。
利用 CubeFS 的就近读写的能力,可以将 Shuffle-worker 与 CubeFS 的数据节点同机部署,这样 Shuffle-worker 在读写数据的时候,就不需要经过网络,也不受网卡带宽的限制,直接从本机的 DataNode 上读取数据,从而提高 Shuffle-worker 的数据读写性能。
提供异步删除的功能,将待清理的目录先 rename 到一个临时待删除的目录下,然后 CubeFS 后台定时扫描,异常清理待删除目录。一次 rename 操作在 CubeFS 只需要跟后端交互两次,相比于之前串行的删除目录下所有文件,延时由 N 个 ms 降低到了稳定的 2ms 左右。使用 CubeFS 存储将 Shuffle 的时延减低 20%,成本降低 20%。
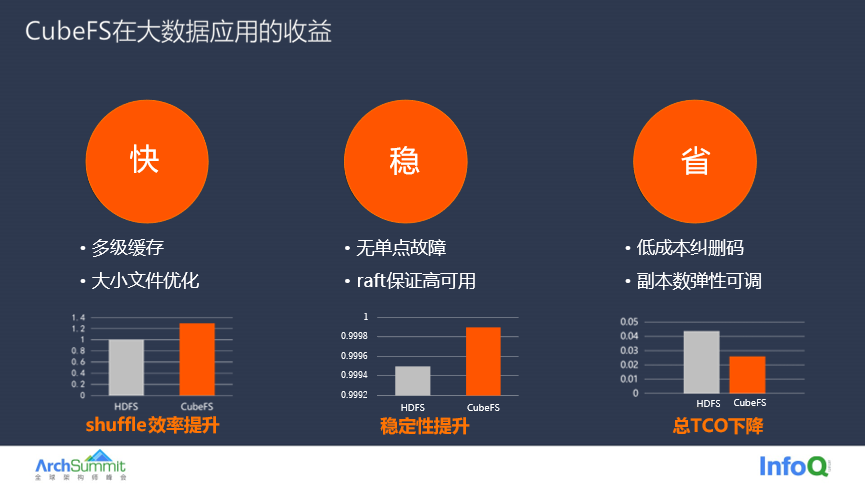
总结来说,CubeFS 帮助大数据服务实现了快、稳、省的目标。有效提升数据的访问性能、提高存储服务的稳定性并大量地节约存储成本,降低总 TCO。










