如若问谁最有希望在中国实现智慧涌现,十多年前科大讯飞成立时的那个回答依旧铿锵有力:要么率先燎原,要么率先熄灭。

历时 5 个月、100 多天,5 月 6 日下午 2 点,科大讯飞「星火」认知大模型如约而至。
发布会独具匠心,亮点一分为二:「1」 + 「N」。
上半场围绕「1」,聚焦「星火」通用能力展示。无论是挖坑设雷还是烧脑为难,「星火」应对自如,会场不时响起掌声和笑声。
下半场由「1」生「N」,旗下首批获「星火」加持的产品矩阵登台亮相。从教育、办公、车载到虚拟人,一次次人机交互体验盛宴,让人很难按捺点击购买的冲动。
与之前其他公司大模型发布活动不同,本次发布是一场产品级发布会——购买相应硬件产品,用户即可升级系统,立刻体验大模型带来的神奇能力。
AI 大模型将带来终端数量和产业规模 10 倍以上的提升,科大讯飞董事长刘庆峰在会上表示,未来,「星火」认知大模型「1+N」的技术红利将通过「平台+赛道」的商业逻辑逐步兑现。
 科大讯飞董事长在发布会上。
科大讯飞董事长在发布会上。
一、「1」:七大维度体验「星火」的通用能力
发布会开宗明义,为了科学 PK ChatGPT 能力,科大讯飞通过认知智能全国重点实验室牵头设计了通用认知大模型评测体系,并与中科院人工智能产学研创新联盟和长三角人工智能产业链联盟共同探讨形成了覆盖 7 大类 481 个细分任务类型。
其中,7 个能力具体包括语言理解、知识问答、逻辑推理,数学能力、代码能力以及多模态能力。
先说结果:目前「星火」通用能力业内明显领先。中文方面,当前讯飞星火认知大模型已经在文本生成、知识问答、数学能力三大能力上已超 ChatGPT,10 月底将整体赶超 ChatGPT。
10 月 24 日开发者大会上,「星火」要「对标 ChatGPT,在中文上超过,在英文上要达到跟它相当的水平。」刘庆峰在发布会上表示。

接下来,我们看看这些能力的现场展示,包括机器之心内测体验。
1、长文本生成能力。 「星火」现场演示了撰写大会欢迎词、翻译机英文品宣文案等能力。不过,让人倍感温度的案例是给孩子讲故事。
「在今天的讯飞星火认知大模型的发布会上,孙悟空和奥特曼也偷偷潜入了现场,他们都抢着想做星火大模型的发言人,还为此吵了一架。」 科大讯飞副总裁、研究院院长刘聪起了一个头,「星火」立刻娓娓道来一段故事。

每问一次,它讲述的故事都不一样。你不仅可以语音输入开头和故事要求,还能选择喜欢的合成声音甚至配合虚拟人形象,将这个故事说给孩子听。
会场之外,机器之心也没闲着。我们以《麦田守望者》为题,要求「星火」创作一首现代诗歌和古代的绝句,你看,还不错。

 绝句最后一句对仗还是存在瑕疵。
绝句最后一句对仗还是存在瑕疵。
机器之心又让「星火」写一篇《荒野的呼唤》读后感,完全合格。
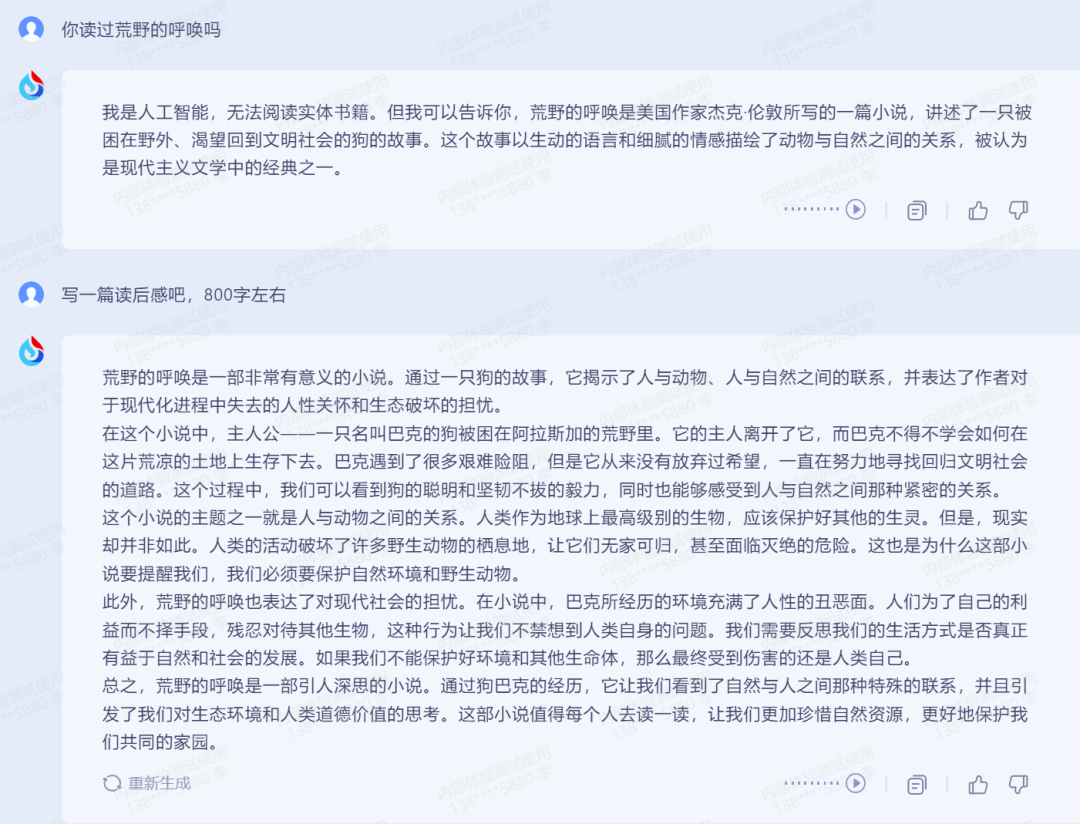
现在化身婚礼策划,给窦骁和何超莲做一次婚礼策划吧!不知道窦骁有没有从大模型获取婚礼策划灵感呢?


为了体验「星火」生成摘要的能力,机器之心故意输入一篇很长的专访,结果发现,摘要基本覆盖了核心内容。
过程中,我们故意打了一个 typo(生「存」摘要),但并没影响模型对输入任务的理解。

 这是界面对《翦商》作者李硕的专访。
这是界面对《翦商》作者李硕的专访。
 「星火」生成的摘要。
「星火」生成的摘要。
2、多层次跨语种语言理解能力,这也是大模型调用频率最高的能力之一。既包括诸如英文、中文表达上的语法修改,也有更高层次的语言理解,特别是理解博大精深的中文。
比如,小明拿到奖杯默默站了一分钟;小明被老师批评,默默站了一分钟。这两个「默默」是否表达了不同心情?
「星火」完全知道:一个是指高兴,一个是形容失落。
刘庆峰表示,科大讯飞现在的语言能理解能力相比 ChatGPT 还略有差距,但已超越国内同类产品。
3、「星火」的思维链推理能力如何?发布会上,刘庆峰继续给「星火」挖坑:孔子在 2008 年奥运会上说了些什么?结果人家不上当。
机器之心继续考验:

数理能力一定程度代表了一个大模型的聪明程度。刘聪现场也抛出了复杂的计算题:
「花坛里有三种花,一共 88 朵,其中月季花的数量是菊花的4倍,牡丹花的数量是菊花的 5 倍少 2 朵,那么请问花坛里一共有多少朵牡丹花?」
大模型很快准确给出了答案,并给出了解题步骤。刘庆峰表示,讯飞星火大模型不仅在国内系统中遥遥领先,也超过了 ChatGPT。
会场外,机器之心找来一道真实的小学数学题,多轮对话追问,「星火」也能应对。



4、在多功能语言代码能力上,科大讯飞展示了「大模型+数字员工」,基于自然语言生成业务流程和 RPA,帮助企业员工完成大量重复性工作。
现场以公司招聘事项为例,输入指令后,系统即可自动按照事先设计的 RPA 脚本,操作计算机中的相应软件,实现业务流程的自动化操作并输出结果,还能进行数据分析,大幅减轻一线工作人员的压力。
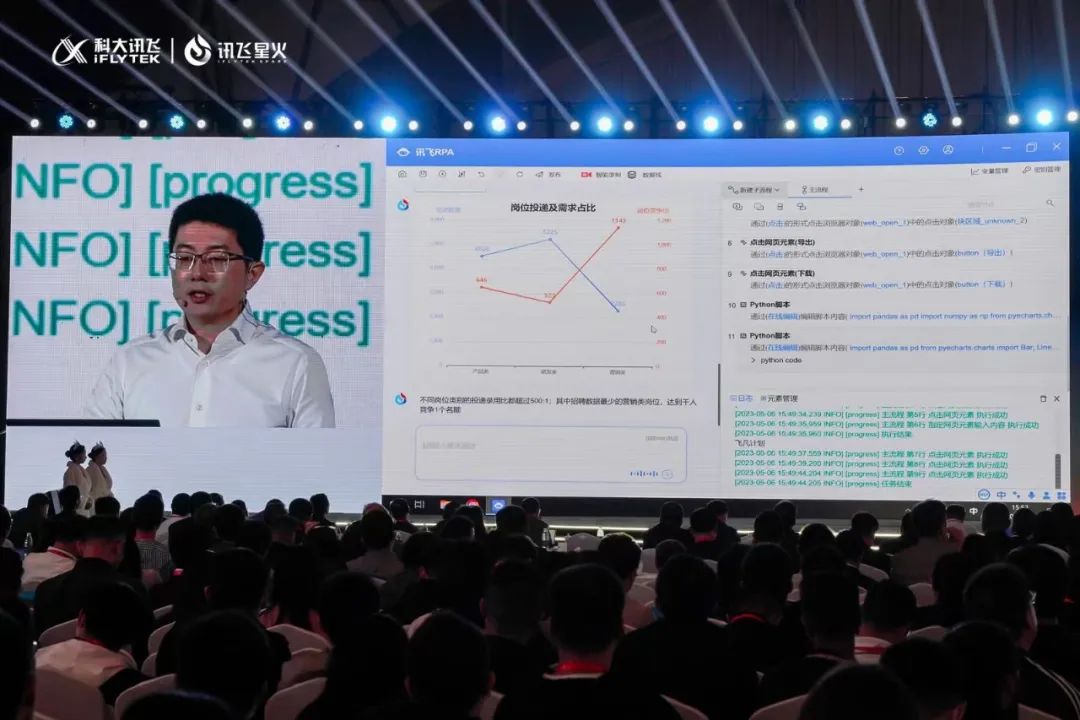
刘庆峰表示,工业领域也是一个非常重要落地场景,降低没有软件背景普通工程师和工人的编程门槛,我们可以期待 8 月的能力突破。
5、多模态输入和表达能力不断丰富。比如,输入一份图文并茂的英文菜单,「星火」不仅立刻给出了中文版菜单,还能应要求介绍没有吃过的菜品基本情况,用户甚至可以指定虚拟人以指定的合成声音,给自己介绍这些菜单内容。
除了上述展示,机器之心在测试大模型多轮对话能力时,发现方言能力是一个有趣的亮点,我们也测试过微软 Bing AI ,后者暂时没办法做到。

另外,大模型呈现出的初步「智慧涌现」还体现在即时新知识学习应用于进化能力,但机器之心发现「星火」还需要加强。
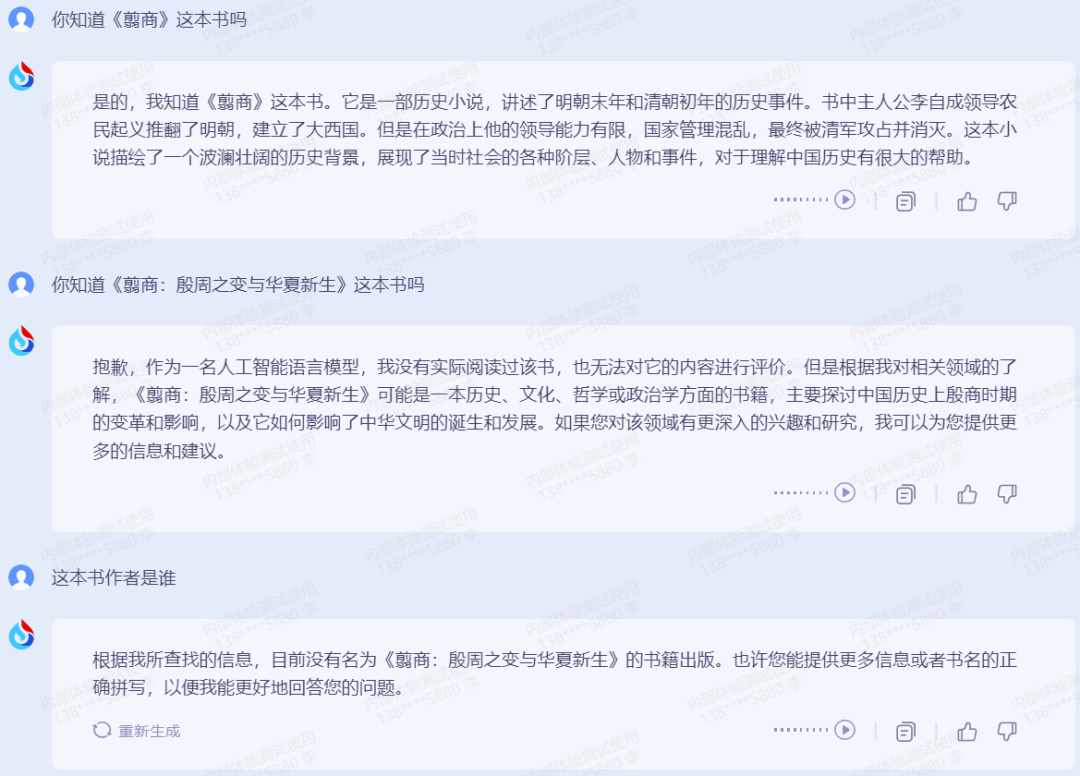
比如,笔者正在读《翦商:殷周之变与华夏新生》一书,该书豆瓣评分很高,可能因为语料库中没有出现这本书或没有得到准确定义,「星火」并不知道这本书。
告诉「星火」书的全名、作者和出版社、出版年月,再试探它对该书的了解情况,结果仍不如意。
二、由「1」生「N」:大模型落地应用的领先者
图片社交软件 Instagram 积攒过亿用户数用了2.5年,TikTok 用了9个月,而 ChatGPT 只用了两个月。爆火主要是因为其撬动了最具规模效应的 C 端——提供了一个便捷易用的交互界面,让普通人都能用得起来。
对于 C 端产品,大模型的重要价值在于大幅提升了后端理解能力,当与前端的听、说能力融为一体后,将极大提升每一个智能终端的人机交互体验,后者变得更便捷、自然和有深度。
科大讯飞已拥有智能录音笔、翻译笔、智能办公本、AI 学习机等诸多 C 端产品,将大模型能力下放到这些产品矩阵中以达到一种规模效应,再自然不过。
客户真实使用的反馈非常重要,基于真实场景的数据最能验证模型的性能。既然模型需要长时间持续跟随客户的反馈不断调优,C 端能够更快卷起这个闭环。
正如科大讯飞表示,目前还没有一家国产大模型面向公众大规模开放,让所有人都可以体验。讯飞推出的这些功能都是产品级,购买相应硬件的用户即可立刻获得体验。
下半场,首先登场的教育领域,是最具想象力和应用前景的垂直领域之一。以 AI 学习机为例。
「双减」之下,对标教培行业,AI 教育硬件市场风光无限,AI 学习机等产品也被寄予未来百亿营收规模的厚望,目前科大讯飞已形成高、中、低端学习机系列的完整布局。
不过,现阶段消费者很难明确体验、感知到智能服务及其效果,在业内人士看来,未来市场增长的关键点之一在于能否实现智能服务体验上的跃升,AI 大模型的出现可以实现这一点。
「星火」大模型的基础能力,对教育领域的专业模型的语言表达、包括上下文在内的复杂语义理解、逻辑推理等方面会带来巨大提升。无论是通识科普、语文写作还是数学刷题,「星火」都能轻松帮上忙。
发布会上,搭载认知大模型的科大讯飞 AI 学习机 T20 系列可实现中英文作文类人批改。相比于传统学习机只能针对字词标点纠错、识别句式修辞错误这些基础批改,讯飞 AI 学习机实现了围绕写作要求、分析全篇结构和文采的深度高阶批改。像老师一样层层批改点评,让作文批改更高效。
它还可以实现写作思路启发,利用 AI 润色技术生成片段优化参考和写作建议提升,让孩子在启发中精准提升。
 搭载了大模型后,第一轮批改了错别字;第二轮批改了语句;第三轮,覆盖了内容;最后还给了一个分数80。同时,系统还生成了总体评价和写作建议。这不仅需要自然语言理解能力,还需要需要文本生产能力。
搭载了大模型后,第一轮批改了错别字;第二轮批改了语句;第三轮,覆盖了内容;最后还给了一个分数80。同时,系统还生成了总体评价和写作建议。这不仅需要自然语言理解能力,还需要需要文本生产能力。
 英文批改也可以。
英文批改也可以。
另外,作为科大讯飞业务营收的第三大支柱——讯飞开放平台和消费者业务(主要围绕「AI+」办公场景),过去也有不错增长。未来,基于大模型提升智能办公本、录音笔、讯飞听见 APP 等产品性能体验,将进一步拉开与竞品的差距。
以目前服务客户数超 3700 万的讯飞听见 APP 为例,这款应用主要负责将语音这样的非结构化数据迅速转换为可保存、检索的文本数据,提升生产效率。
我们匆匆记录重要会议和活动信息,机器可以将录音变成文本,仍然表达不够规范、不够美(还包括一些语音识别错误),需要后期人工润色。
有了「星火」,讯飞听见 APP 能力进一步延伸到人工环节——自动校对、润色过于口语化的机器翻译,还能按需生产摘要或办公文档——覆盖从转写到出稿的全过程,显著提升工作效率。
现场演示中,选择APP「会写」,导入一段音频,直接选择新闻稿件,17秒即可生成新闻稿。系统还可以根据用户关注的侧重点、格式、语言要求,生成不同的内容版本。你甚至可以具体了解,哪些地方因为什么原因而被系统规整掉了。
当然,用户还可以一键形成会议纪要,包括内容总结和重点关注。
 左边是录音稿件的转写,右边是成文的新闻稿。
左边是录音稿件的转写,右边是成文的新闻稿。
 一键形成会议纪要,包括内容总结和重点关注
一键形成会议纪要,包括内容总结和重点关注
 现场语篇规整能力展示。
现场语篇规整能力展示。
会场外,机器之心输入了一段科大讯飞某位管理层在一次会议活动上的发言,非常口语化的表达,然后让「星火」大模型润色,规整能力效果不错。
当我们从生态角度来看产业落地,想要尽快「星火」大模型技术在不同行业的落地和迭代,那么,仅靠一家公司肯定不行,必须发动群众,这也是「星火」燎原的重要途径。
目前,讯飞 AI 开放平台开发者数量已达 380.5 万。2022 年技术授权及开发者服务收入保持稳定增长,毛利同比增长 20%。科大讯飞在发布会上表示,开发团队可以通过 API 调用等方式获得「星火」大模型的各项能力。
如此一来,除了可以以一定付费方式与平台实现价值分享,还能为大模型提供大量文本语料和用户反馈数据,促进模型更快的迭代。

不难看出,无论是学习机、讯飞听见APP 等生产力工具用户,还是数百万开发者,当他们与设备、开放平台不断交互时,期间产生大量的数据又能反哺到模型,实现数据与模型相结合,进一步提高模型理解能力,不断更新迭代。
随着大量积累专业领域语料和实际场景应用,它们反过来又会反哺、促进大模型的通用智慧涌现。已经取得成效的专业模型再通过知识衔接在大模型中得到统一训练,形成通用领域的智慧涌现和逻辑推理能力的整体提升,两者相辅相成。
这恐怕也是科大讯飞为什么有信心在中文领域的通用认知大模型实现智慧涌现,同时在教育、办公、医疗等领域做到业界领先的底气所在。
 接下来,讯飞星火大模型还会有三轮的迭代。
接下来,讯飞星火大模型还会有三轮的迭代。
三、核心技术、数据与长期主义
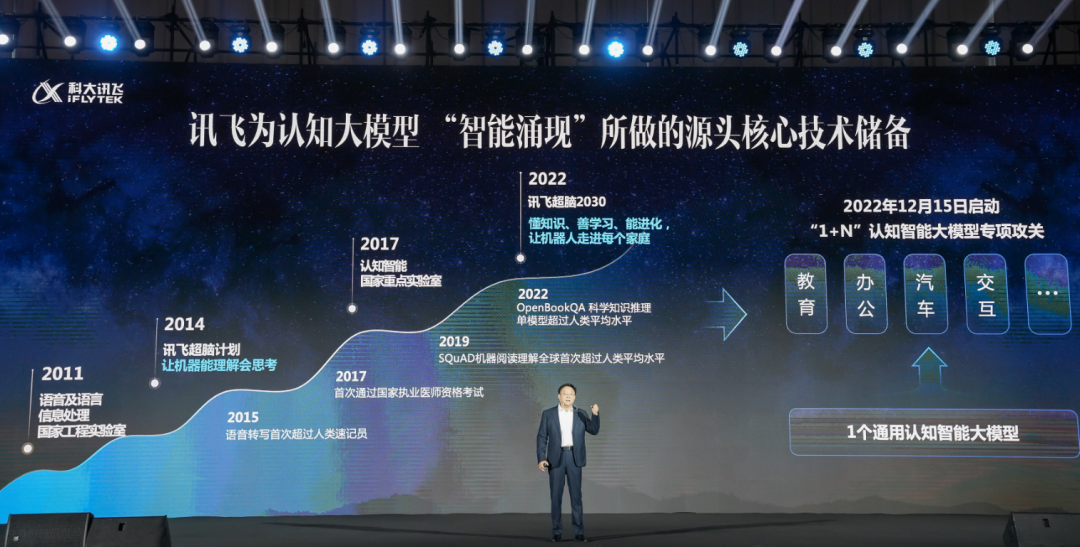
2022 年 12 月,科大讯飞开始「星火」认知智能大模型的专项攻关,能在五个月里实现认知大模型的快速突破,和公司长期扎实积累密不可分。
语音技术是为了让机器能听会说,光能听会说还不够,还要能懂人类说的语言,这就需要做自然语言处理,从感知智能深入认知智能。因此,早在 2014 年,科大讯飞就发布讯飞超脑,当时宣布的目标就是让机器从「能听会说」到能理解、会思考。
2017 年,公司获批承建认知智能国家重点实验室。当年,机器在全球首次通过了国家执业医师资格考试,超过了 96.3% 参加考试的医生。
「在人工智能核心技术的投入上,公司的态度一直是对于应该投入的重点方向饱和投入、绝不手软。」4 月,科大讯飞在 2022 年度业绩说明会答投资者问中提到,科大讯飞在 Transformer 深度神经网络算法方面已经拥有丰富经验,也广泛应用于科大讯飞的语音识别、图文识别、机器翻译等任务并达到国际领先水平。
其中,核心技术方面一直保持国际领先水平。在人工智能技术从感知智能迈向认知智能的攻坚阶段,常识推理是重要一环。仅 2022 年,科大讯飞就在认知智能技术领域累计获得 13 项世界冠军。
例如,在 OpenBookQA 夺冠后,科大讯飞对夺冠系统、知识与大模型融合统一的理解框架 X-Reasoner 升级改造后,推出 X-Reasoner++ 又在 2022 年夺得 QASC 榜首,实现全球首次超越人类平均水平。
2022 年,他们还开源了 6 个大类、超过 40 个通用领域的系列中文预训练语言模型,相关模型库月均调用量超 1000 万,在 Github 平台获得星标数位列同类中文预训练语言模型第一并远超第二名。
除了核心算法方面的积累,科大讯飞在多年认知智能系统研发推广中积累了超过50TB 的行业语料和每天超 10 亿人次用户交互的活跃应用。
第三方数据看似获取门槛较低,但想规模化获取海量的高质量数据并非易事,需要长时间规范化积累,在数据合规性上也必须有一定保障,这也是为什么科大讯飞在大模型领域的创新值得关注。
而对于垂直领域的大模型来说,最重要的还是垂直领域数据,除了可获取的专业知识库外,垂直领域数据主要来源于客户真实的业务场景,持续高效获得高质量的垂直领域第一方数据也是科大讯飞独有的数据能力壁垒。
事实上,业务内容决定他们拥有更多的是教育、医疗等垂直领域数据(比如文本数据和用户反馈数据)。而深度的行业应用为数据质量提供保证,这些高质量行业数据也是认知大模型实现多轮对话、逻辑推理不可或缺的「燃料」。
在教育领域,科大讯飞相关教育产品已在全国 32 个省级行政区得到应用,覆盖五万余所学校、1.3 亿师生,拥有海量语音、成绩单、题库等数据。
例如,科大讯飞已连续多年为中高考、普通话、英语四六级提供技术支持;目前全国普通话考试、部分省市中高考口语评测都用的是讯飞的机器评测技术;成人高考上也开始使用讯飞的全学科机器阅卷。
由于科大讯飞已经构建了面向 G/B/C 三类客户的业务体系,在不少分析人士看来,如果公司能够借助 G、B 端,实现课内外数据的脱敏打通,比如学生自己买学习机之后,还能同步自己课堂上的学习数据,个性化学习能力将更为凸显,将大幅拉开与竞品的距离。
在医疗领域,科大讯飞在业内是全国唯一通过国家执业医师资格考试的人工智能系统,超过了 96.3% 的医学考生,已累计为基层医生提供了超过 5.8 亿次、日均超过七十多万人次的人工智能辅诊。
同样,作为首批国家新一代人工智能开放创新平台,日使用量超过 50 亿人次,多年来也为大模型提供了海量文本语料和用户反馈数据。
在认知大模型相关的算力上,科大讯飞在总部自建有业界一流的数据中心,目前已建成四城七中心深度学习计算平台,为大模型训练平台建设奠定了很好的硬件基石。
他们围绕自主可控人工智能算力平台展开建设,目前公司的训练、推理在国产平台上的方案已跑通成型。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com











