【导读】开源LLaMA神话再次复现!首个开源650亿参数大模型高性能预训练方案,训练加速38%,低成本打造量身大模型。
「百模大战」正风起云涌,AIGC相关企业融资和并购金额也屡创新高,全球科技企业争相入局。
然而,AI大模型风光无限的背后是成本极其高昂,单次预训练成本或高达上千万元。基于LLaMA等现有开源大模型的微调,也难以满足企业打造核心竞争力和多样化商业使用等需求。
因此,如何低成本量身打造预训练基础大模型,已成为AI大模型浪潮的关键瓶颈。
Colossal-AI作为全球最大、最活跃的大模型开发工具与社区,以当前被最广泛使用的LLaMA为例,提供开箱即用的650亿参数预训练方案,可提升训练速度38%,为大模型企业节省大量成本。

开源地址:https://github.com/hpcaitech/ColossalAI
Meta开源的7B~65B LLaMA大模型进一步激发了打造类ChatGPT的热情,并由此衍生出Alpaca、Vicuna、ColossalChat等微调项目。
但LLaMA只开源了模型权重且限制商业使用,微调能够提升和注入的知识与能力也相对有限。对于真正投身大模型浪潮的企业来说,仍必须预训练自己的核心大模型。
为此,开源社区也做了诸多努力:
RedPajama:开源可商用类LLaMA数据集,无训练代码和模型
OpenLLaMA:开源可商用类LLaMA 7B, 13B模型,使用EasyLM基于JAX和TPU训练
Falcon:开源可商用类LLaMA 7B, 40B模型,无训练代码
但对于最主流的PyTorch + GPU生态,仍缺乏高效、可靠、易用的类LLaMA基础大模型预训练方案。
针对上述空白与需求,Colossal-AI首个开源了650亿参数LLaMA低成本预训练方案。
相比业界其他主流选择,该方案可提升预训练速度38%,仅需32张A100/A800即可使用,并且不限制商业使用。
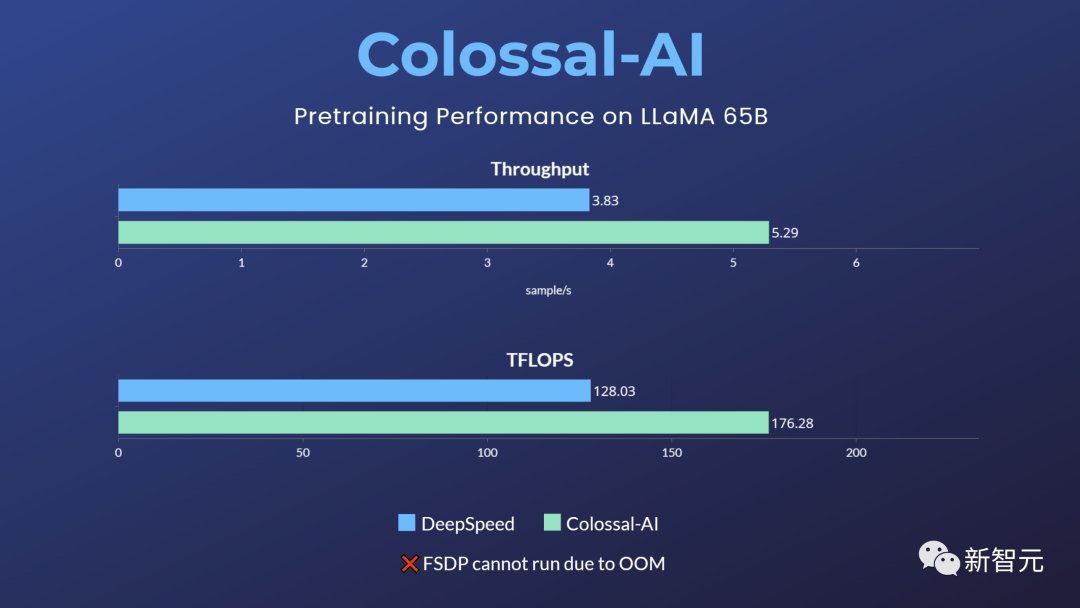
而像原生PyTorch、FSDP等,则因显存溢出无法运行该任务。Hugging Face accelerate、DeepSpeed、Megatron-LM也未对LLaMA预训练进行官方支持。
1. 安装Colossal-AI
git clone -b example/llama https://github.com/hpcaitech/ColossalAI.gitcd ColossalAI# install and enable CUDA kernel fusionCUDA_EXT=1 pip install .
2. 安装其他依赖
cd examples/language/llama# install other dependenciespip install -r requirements.txt# use flash attentionpip install xformers
3. 数据集
默认数据集togethercomputer/RedPajama-Data-1T-Sample将在首次运行时自动下载,也可通过-d或--dataset指定自定义数据集。
4. 运行命令
已提供7B和65B的测速脚本,仅需根据实际硬件环境设置所用多节点的host name即可运行性能测试。
cd benchmark_65B/gemini_autobash batch12_seq2048_flash_attn.sh
对于实际的预训练任务,使用与速度测试一致,启动相应命令即可,如使用4节点*8卡训练65B的模型。
colossalai run --nproc_per_node 8 --hostfile YOUR_HOST_FILE --master_addr YOUR_MASTER_ADDR pretrain.py -c '65b' --plugin "gemini" -l 2048 -g -b 8 -a
例如,使用Colossal-AI gemini_auto并行策略,可便捷实现多机多卡并行训练,降低显存消耗的同时保持高速训练。还可根据硬件环境或实际需求,选择流水并行+张量并行+ZeRO1等复杂并行策略组合。
其中,通过Colossal-AI的Booster Plugins,用户可以便捷自定义并行训练,如选择Low Level ZeRO,Gemini,DDP等并行策略。
Gradient checkpointing通过在反向传播时重新计算模型的activation来减少内存使用。通过引入Flash attention机制加速计算并节省显存。
用户可以通过命令行参数便捷控制数十个类似的自定义参数,在保持高性能的同时为自定义开发保持了灵活性。
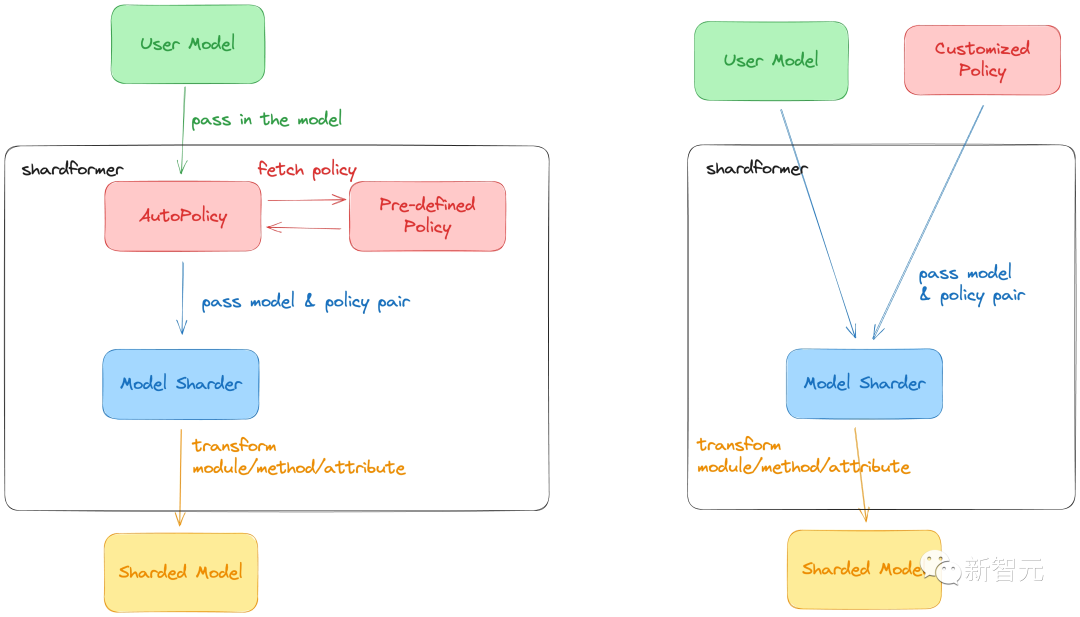
ColossalAI最新的ShardFormer极大降低了使用多维并行训练LLM的上手成本。
现已支持包括LLaMA的多种等主流模型,且原生支持Huggingface/transformers模型库。
无需改造模型,即可支持多维并行(流水、张量、ZeRO、DDP等)的各种配置组合,能够在各种硬件配置上都发挥卓越的性能。
Colossal-AI为该方案提供了核心系统优化与加速能力支持,它由加州伯克利大学杰出教授James Demmel和新加坡国立大学校长青年教授尤洋领导开发。
Colossal-AI基于PyTorch,可通过高效多维并行、异构内存等,降低AI大模型训练/微调/推理的开发与应用成本,降低GPU需求等。
Colossal-AI上述解决方案已在某世界500强落地应用,在千卡集群性能优异,仅需数周即可完成千亿参数私有大模型预训练。上海AI Lab与商汤等新近发布的InternLM预训练代码也参考了Colossal-AI。
自开源以来,Colossal-AI已经多次在GitHub热榜位列世界第一,获得GitHub Star超3万颗,并成功入选SC、AAAI、PPoPP、CVPR、ISC等国际AI与HPC顶级会议的官方教程,已有上百家企业参与共建Colossal-AI生态。
其背后的潞晨科技,近期获得数亿元A轮融资,已在成立18个月内已迅速连续完成三轮融资。
https://github.com/hpcaitech/ColossalAI
https://www.hpc-ai.tech/blog/large-model-pretraining










