适用范围
《生成式人工智能服务管理暂行办法》(一下简称“办法”)第二条称“利用生成式人工智能技术向中华人民共和国境内公众提供生成文本、图片、音频、视频等内容的服务,适用本办法”;
第二十二条称“生成式人工智能服务提供者,是指利用生成式人工智能技术提供生成式人工智能服务(包括通过提供可编程接口等方式提供生成式人工智能服务)的组织、个人”;
第二十条称“针对对来源于中华人民共和国境外向境内提供生成式人工智能服务不符合法律、行政法规和本办法规定的,国家网信部门应当通知有关机构采取技术措施和其他必要措施予以处置”。
所以,适用范围中可以确定为利用人工智能技术(包括通过提供可编程接口等方式)向中华人民共和国境内公众提供生成式人工智能服。这里面有以下三个问题需要进一步明确:
1、如何理解“面向中华人民共和国境内公众提供服务”
参考2017年全国信息安全标准化技术委员会发布的《信息安全技术数据出境安全评估指南》征求意见稿中的“3.2境内运营的注1”,其中说明“未在中华人民共和国境内注册的网络运营者,但在中华人民共和国境内开展业务,或向中华人民共和境内提供产品或服务的,属于境内运营。判断网络运营者是否在中华人民共和国境内开展业务,或向中华人民共和境内提供产品或服务的参考因素包括但不限于:使用中文;以人民币作为结算货币;向中国境内配送物流等”。
同时,结合互联网服务的特征,除了上述考虑因素外,还可以是否可用中国大陆手机号码进行账号注册及登录;是否可以允许IP地址在中国大陆的账号进行访问和操作等维度,与类似ChatGPT等不向中国大陆开放的服务相区别。
2、如何理解“向公众提供”
目前国内许多产品都属于内测版本,只向部分用户开放,那这些测试版产品是否适用本法规范呢?
办法第二条第三款规定“行业组织、企业、教育和科研机构、公共文化机构、有关专业机构等研发、应用生成式人工智能技术,未向境内公众提供生成式人工智能服务的,不适用本办法的规定”,也即“自用软件”不属于本办法适用范围内,而测试版并不属于“自用”的范围,且向公众提供也并未要求向所有公众均开放,因此笔者认为测试版产品依然属于办法规制范围,只不过因为产品的开放程度和影响程度有限,履行办法规定的要求的复杂程度相对于正式产品要低一些。
事实上,许多测试版产品虽然只是定向发放内测名额,但只要是不属于内部使用的服务(实践中参考来判断是否),都需要及时落实有关要求,例如下图为国内某测试版大模型的算法备案信息,该测试版同样暂时仅对少数定向群体开放。
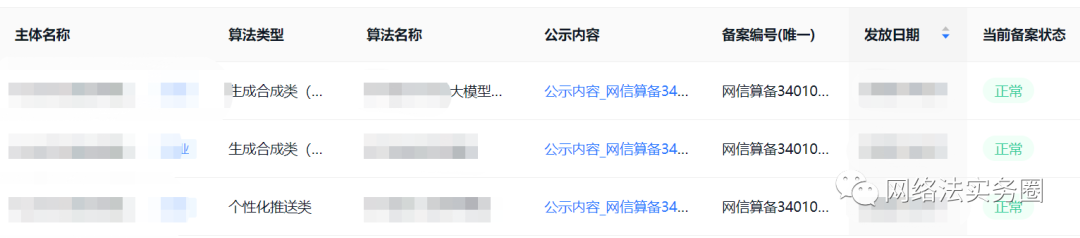
因此相关企业和个人在部署产品过程中需要及时关注不同阶段的要求,建议在产品测试阶段对相关规定进行落实,以便保障后续正式版产品的合规性。
3、来源于中华人民共和国境外向境内提供生成式人工智能服务
对于第二十条所称“对来源于中华人民共和国境外向境内提供生成式人工智能服务”应当如何理解,是否包括国内开发者使用了国外开源软件或是购买了国外的服务来作为底层技术的服务?
关于这一点,目前并未有足够充分的依据来说明,只能等待监管部门对这一问题的最终认定。在国家互联网信息办公室官网发布的文章《专家解读|制度与技术同频共振:生成式人工智能治理的中国方案》[1]中,对外经贸大学的许可老师认为“《办法》统筹了“境内”和“境外”,对境外企业提供生成式人工智能服务的需求作出回应,要求在遵守本法的前提下合规经营,对外商投资生成式人工智能服务做出衔接规定,体现出包容开放的政策导向”。
从专家解读中可以感受到“来源于境外向境内提供的服务”和“境外企业提供生成式人工智能服务”相对应,从这一解释出发,来源于中华人民共和国境外向境内提供生成式人工智能服务不包括国内开发者使用国外开源软件或是购买了国外的服务来作为底层技术的服务。但是最终的认定仍需监管部门在实践中给予明确。
如何理解不得利用算法、数据、平台等优势,实施垄断和不正当竞争行为
办法第四条是针对内容提出的要求,其中第(三)项要求服务提供者和使用者应当尊重知识产权、商业道德,保守商业秘密,不得利用算法、数据、平台等优势,实施垄断和不正当竞争行为。
生成式人工智能服务可能涉及的不正当竞争的具体场景,较为典型的是“二选一”,需要相关企业和个人注意避免。早在针对《互联网信息服务算法推荐管理规定》第十五条“利用算法实施垄断和不正当竞争行为”的讨论中,已有学者关注到了现实中可能存在的问题。吴沈括教授曾表示,“二选一”的隐蔽形式还体现在平台利用算法对信息推荐进行有倾向性的集中展示,即对某种竞争对手的集中负面展示,而对平台自身与自己生态圈内合作伙伴的集中赞颂展示,通过内容的曝光度给予优待[2]。
因此,在AIGC时代,任何具有信息反馈和展示功能的产品都有可能涉及上述“二选一”的情形,相关服务提供者需要避免出现类似的行为。大模型产品开发中的数据标记规则、关联信息等都有可能影响到最后输出的结果,这一点需要在实践中予以重视。
什么样的数据来源是合法合规的?
办法第七条要求生成式人工智能服务提供者(以下称提供者)应当依法开展预训练、优化训练等训练数据处理活动,落实《中华人民共和国网络安全法》、《中华人民共和国数据安全法》、《中华人民共和国个人信息保护法》等法律法规的要求。其中,办法第七条第(一)项的要求为使用具有合法来源的数据和基础模型。因此,服务提供者需要了解数据合规红线:
开放的公共数据。任何人均有权获取并无条件使用的数据,例如政府依法开放的公共数据,来源合法性可以保证;
通过数据爬取等方式获取公开数据。需要进一步审查被爬取网站是否具备Robots协议,爬虫软件是否遵守被爬取网站的Robots协议内容。例如,百度在线网络技术(北京)有限公司等与北京奇虎科技有限公司不正当竞争案(2013)一中民初字第2668号民事判决认定:奇虎公司在推出其360搜索引擎伊始没有遵守百度公司网站的robots协议的行为明显不当[3]。
利用技术手段突破网站设置的防护措施(例如访问需要身份验证、加密等)爬取的数据。因可能存在未经许可进入计算机系统的行为,从而可能落入《中华人民共和国刑法》第二百八十五条所规定的非法侵入计算机信息系统罪,或第二百八十六条所规定的破坏计算机信息系统罪中的侵入和破坏行为。
爬取数据中包含个人信息的。根据《中华人民共和国个人信息保护法》,收集个人信息应取得个人授权同意,或者基于订立合同必须、履行法定职责和义务等正当事由,否则会涉嫌违法收集个人信息。
当爬取存在竞争关系的主体的数据时,可能涉嫌构成不正当竞争。例如,北京百度网讯科技有限公司与上海汉涛信息咨询有限公司不正当竞争纠纷案(2016)沪73民终242号判决书,二审法院维持了一审判决,一审判决认定百度公司的搜索引擎抓取涉案信息并不违反Robots协议,但这并不意味着百度公司可以任意使用上述信息,百度公司应当本着诚实信用的原则和公认的商业道德,合理控制来源于其他网站信息的使用范围和方式[4]。
当前的数据标记规则及在使用AI标记的情况下如何反馈标记规则?
办法第八条要求在生成式人工智能技术研发过程中进行数据标注的,提供者应当制定符合本办法要求的清晰、具体、可操作的标注规则。
目前常见的数据标记方法包括贴边原则、独立原则、不越界原则、唯一性原则、定位孔原则等。在制定标注规则时,往往会对对标注的数据进行观察,找出图片内物体的共同特征。当遇到不确定的类别,应根据实际情况对标注的场景进行细分,然后再训练模型[5]。现在,办法要求这些规则需要清晰、具体、可操作性。而当前已有用AI进行数据标记的,AI标记的逻辑和算法也需要符合上述清晰、具体、可操作性的要求。
内容生产者的责任有哪些?
办法第九条要求服务提供者应当依法承担网络信息内容生产者责任。而“内容生产者”的责任主要体现在《网络信息内容生态治理规定》中。《网络信息内容生态治理规定》第二章“网络信息内容生产者”重点规范了有关责任,可以概括为以下三点:
鼓励内网络信息内容生产者制作、复制、发布符合价值观的信息;
禁止网络信息内容生产者制作、复制、发布背离价值观的信息;
针对具有危害的不良信息,网络信息内容生产者应当采取措施,防范和抵制制作、复制、发布。
需要说明的是,《网络信息内容生态治理规定》中的规定指向三个主体:
网络信息内容生产者,是指制作、复制、发布网络信息内容的组织或者个人;
网络信息内容服务平台,是指提供网络信息内容传播服务的网络信息服务提供者;
网络信息内容服务使用者,是指使用网络信息内容服务的组织或者个人。
办法中要求服务提供者承担内容生产者的责任而非内容服务平台的责任,笔者认为这是从当前以大模型为典型的生成式人工智能产品特征以及《网络信息内容生态治理规定》的具体规定来考量的。生成式人工智能具备内容创造功能,其最后反馈的内容收到训练时给予信息的价值观的影响。对服务提供者提出承担内容生产者责任的要求,是因为在产品研发、服务提供过程中需要提供者积极主动对进行价值观方面的审核。同时,信息服务平台的一些基本要求,例如设置投诉通道等也需要服务提供者落实。
通用性产品如何做好未成年人保护?
办法第十条要求服务提供者采取有效措施防范未成年人用户过度依赖或者沉迷生成式人工智能服。当前许多头部企业已经形成完善的包括防沉迷系统、儿童模式、内容过滤、家长控制等具体措施。而对于初创型开发者而言,我国当前并未有正式出台的文件专门就具体的产品设计提供指导,仅2020年发布的《信息安全技术 个人信息告知同意指南》(征求意见稿)中有关“告知同意”的具体方式可供参考。
《信息安全技术 个人信息告知同意指南》(征求意见稿)附 录 A(资料性附录)未成年人个人信息的告知同意中的内容。对于通用性产品(不针对特定场景、人群、领域),可以参考其中“终端或应用仅单独面向未成年人的”以外的产品的可采措施。参考其他实务人员总结的内容,如下:
1、在儿童的身份验证方式上,可采取较弱的核验方式对用户进行身份核实,如在用户协议及隐私政策中强调推定其为具有完全民事行为能力的个人,如果为儿童,则必须在其父母或监护人的同意及监督下使用,通常来说即为较为合规的方式。
2、当用户通过年龄验证机制被判定为14周岁以下的未成年人时,此时需要进一步核验监护人的身份并获取其单独同意。核验的方式可直接在监护人终端或应用界面中完成。例如在儿童的终端或应用界面提示为满足国家有关儿童个人信息保护的要求,需要该儿童将有关产品或服务的个人信息使用规则等信息告知其监护人,此时可在该儿童的终端或应用界面上生成用于分享给其监护人的超链接或二维码。儿童可分享超链接或二维码至其监护人,其监护人打开该超链接或扫一扫该二维码之后可以下载或进入监护人专门的终端或应用,该监护人可在该终端或应用界面上确认其是否为该未成年人的监护人。
3、监护人同意机制的告知及同意验证方式的选择上,儿童端可以通过简明、易于理解的形式展示其在使用产品过程中可能遇到的个人信息问题,并加以注意;监护人端可以通过弹窗、提示框、文字说明等形式详细说明儿童信息收集、使用的情况,并重点提示儿童人个人信息的敏感性。同意方式上,可在向监护人告知个人信息使用规则等信息时同时征求监护人的同意[6]。
如何判断属于“具有舆论属性或者社会动员能力的算法推荐服务提供者”,从而需要进行算法备案?
办法第十七条要求提供具有舆论属性或者社会动员能力的生成式人工智能服务的,应当按照国家有关规定开展安全评估,并按照《互联网信息服务算法推荐管理规定》履行算法备案和变更、注销备案手续。
《具有舆论属性或社会动员能力的互联网信息服务安全评估规定》第三条规定,“联网信息服务提供者具有下列情形之一的,应当依照本规定自行开展安全评估,并对评估结果负责:((一)具有舆论属性或社会动员能力的信息服务上线,或者信息服务增设相关功能的;(二)使用新技术新应用,使信息服务的功能属性、技术实现方式、基础资源配置等发生重大变更,导致舆论属性或者社会动员能力发生重大变化的;(三)用户规模显著增加,导致信息服务的舆论属性或者社会动员能力发生重大变化的;(四)发生违法有害信息传播扩散,表明已有安全措施难以有效防控网络安全风险的;(五)地市级以上网信部门或者公安机关书面通知需要进行安全评估的其他情形。”。
目前的许多大模型产品因为与上述第(一)(二)项符合从而需要完成算法备案。算法备案系统:https://beian.cac.gov.cn/#/index,相关企业和个人可以通过网站内公示的填报指南完成主体信息、算法信息、关联产品及功能信息或技术服务方式这三方面的填报工作。
中华人民共和国国家互联网信息办公室:《专家解读|制度与技术同频共振:生成式人工智能治理的中国方案》http://www.cac.gov.cn/2023-07/13/c_1690898364234016.htm,2023年7月19日最后访问。百家号:《算法监管元年开启:剑指“大数据杀熟” 新闻推荐平台需获服务资质》https://baijiahao.baidu.com/s?id=1721069485367251119&wfr=spider&for=pc,2023年7月19日最后访问。聚法案例:https://www.jufaanli.com/detail/H2tZHDqA/?q=%EF%BC%882013%EF%BC%89%E4%B8%80%E4%B8%AD%E6%B0%91%E5%88%9D%E5%AD%97%E7%AC%AC2668%E5%8F%B7&%EF%BC%882013%EF%BC%89%E4%B8%80%E4%B8%AD%E6%B0%91%E5%88%9D%E5%AD%97%E7%AC%AC2668%E5%8F%B7&src=search&k=&last_search_uuid=701fb031d691cd7a32028508863f712f&level_id=2&p=&search_uuid=9d19ab0404f0b21404228ba4e765e4dc,2023年7月19日最后访问。聚法案例:https://www.jufaanli.com/detail/kaMajqvS/?q=%EF%BC%882016%EF%BC%89%E6%B2%AA73%2C%E6%B0%91%E7%BB%88242%2C%E5%8F%B7&%EF%BC%882016%EF%BC%89%E6%B2%AA73&%E6%B0%91%E7%BB%88242&%E5%8F%B7&src=search&k=&last_search_uuid=b8e15e1d9cdb090c4b8ea33974d187db&level_id=2&p=&search_uuid=d89ec66791825e0dcced42776c932241,2023年7月19日最后访问。搜狐网:《懂的都懂:数据标注项目的规则怎么制定?》https://m.sohu.com/a/637991048_518843,2023年7月19日最后访问。网络法实务圈微信公众号:《家长同意已失效,请及时续费(上):儿童监护人同意机制法规篇》https://mp.weixin.qq.com/s/_QEXCFns8zEa-wHwGgxz-A
作者简介
程念
浙江垦丁律师事务所人工智能法律研究部负责人,中国政法大学法学硕士(网络法学专业),专注于数据合规、个人信息保护、直播短视频、人工智能及涉网诉讼、元宇宙与NFT合规等互联网法律实务工作,为多家知名网络公司提供常年法律顾问服务等,参与首例5G云游戏侵权案、直播带货预期可得追回案等典型案件的办理,参与撰写《直播与短视频产业合规蓝皮书》《元宇宙与元规则——元宇宙产业及元规则体系建构蓝皮书》等报告。参与编写著作《理解与实施》。