Meta 近日发布了一个基于 Llama 2 进行微调构建的大型语言模型 Code Llama,可以使用文本提示生成代码,并且开源,可供研究和商业用途。
Code Llama是针对代码任务的公开 LLM 的最先进技术,有可能使当前开发人员的工作流程更快、更高效,并降低学习编码人员的进入门槛。 Code Llama 有潜力用作生产力和教育工具,帮助程序员编写更强大、文档更齐全的软件。
Code Llama的工作原理
今年 7 月,Meta(原 Facebook)发布了免费可商用的开源大模型 Llama 2。最新发布的 Code Llama 是 Llama2 的专门用于编码的专用版本,是通过在其特定于代码的数据集上进一步训练 Llama 2 来创建的,从同一数据集中采样更多数据的时间更长。
总的来说,Code Llama 具有增强的编码功能,建立在 Llama 2 之上。它可以根据代码和自然语言提示生成代码和有关代码的自然语言(例如,“给我写一个输出斐波那契序列的函数。”) 它还可用于代码完成和调试。
Code Llama支持当今使用的许多最流行的语言,包括 Python、C++、Java、PHP、Typescript (Javascript)、C# 和 Bash。
Code Llama目前拥有三个参数版本:70亿参数、130 亿参数、340 亿参数。
每个版本都使用 500B 代码 token 和代码相关数据进行训练。 70亿 和 130亿参数基础模型和指令模型也经过了中间填充 (FIM) 功能的训练,允许它们将代码插入到现有代码中,这意味着它们可以支持开箱即用的代码完成等任务。
这三种模型满足不同的服务和延迟要求。 例如,70亿模型可以在单个 GPU 上运行。 340 亿模型返回最佳结果并提供更好的编码辅助,但较小的 70亿和 130 亿模型速度更快,更适合需要低延迟的任务,例如实时代码完成。
Code Llama模型提供了具有多达 10 万个上下文 token 的稳定生成。 所有模型都在 16,000 个 token 的序列上进行训练,并在最多100,000 个 token 的输入上显示出改进。
除了是生成更长程序的先决条件之外,拥有更长的输入序列还可以为代码法学硕士解锁令人兴奋的新用例。 例如,用户可以为模型提供来自其代码库的更多上下文,以使各代更相关。 它还有助于调试较大代码库中的场景,在这种情况下,掌握与具体问题相关的所有代码对于开发人员来说可能具有挑战性。 当开发人员面临调试大量代码时,他们可以将整个代码长度传递到模型中。
Meta还微调了 Code Llama 的两个附加版本:Code Llama - Python 和 Code Llama - Instruct。
Code Llama - Python是 Code Llama 的语言专用变体,在 Python 代码的 100B token 上进一步微调。
Code Llama - Instruct是 Code Llama 的指令微调和对齐版本。 指令调整继续训练过程,但目标不同。 该模型接受“自然语言指令”输入和预期输出。 这使得它能够更好地理解人们对提示的期望。 我们建议在使用 Code Llama 进行代码生成时使用 Code Llama - Instruct 版本,因为 Code Llama - Instruct 已经过微调,可以用自然语言生成有用且安全的答案。
但是不建议使用 Code Llama 或 Code Llama - Python 执行一般自然语言任务,因为这两个模型都不是为遵循自然语言指令而设计的。 Code Llama 专门用于特定于代码的任务,不适合作为其他任务的基础模型。
Code Llama的性能如何?
HumanEval和 Mostly Basic Python 编程 (MBPP) 是两个常用编码能力测试基准—— HumanEval 用于测试模型根据文档字符串完成代码的能力,MBPP 用于测试模型根据描述编写代码的能力。
根据这两个测试基准对 Code Llama 测试显示,Code Llama优于开源、特定代码的 Llama,并且优于 Llama 2 本身。例如,Code Llama 34B 在 HumanEval 上得分为 53.7%,在MBPP 上得分为 56.2%,超越了ChatGPT,但在 HumanEval 上仍逊于 GPT-4。
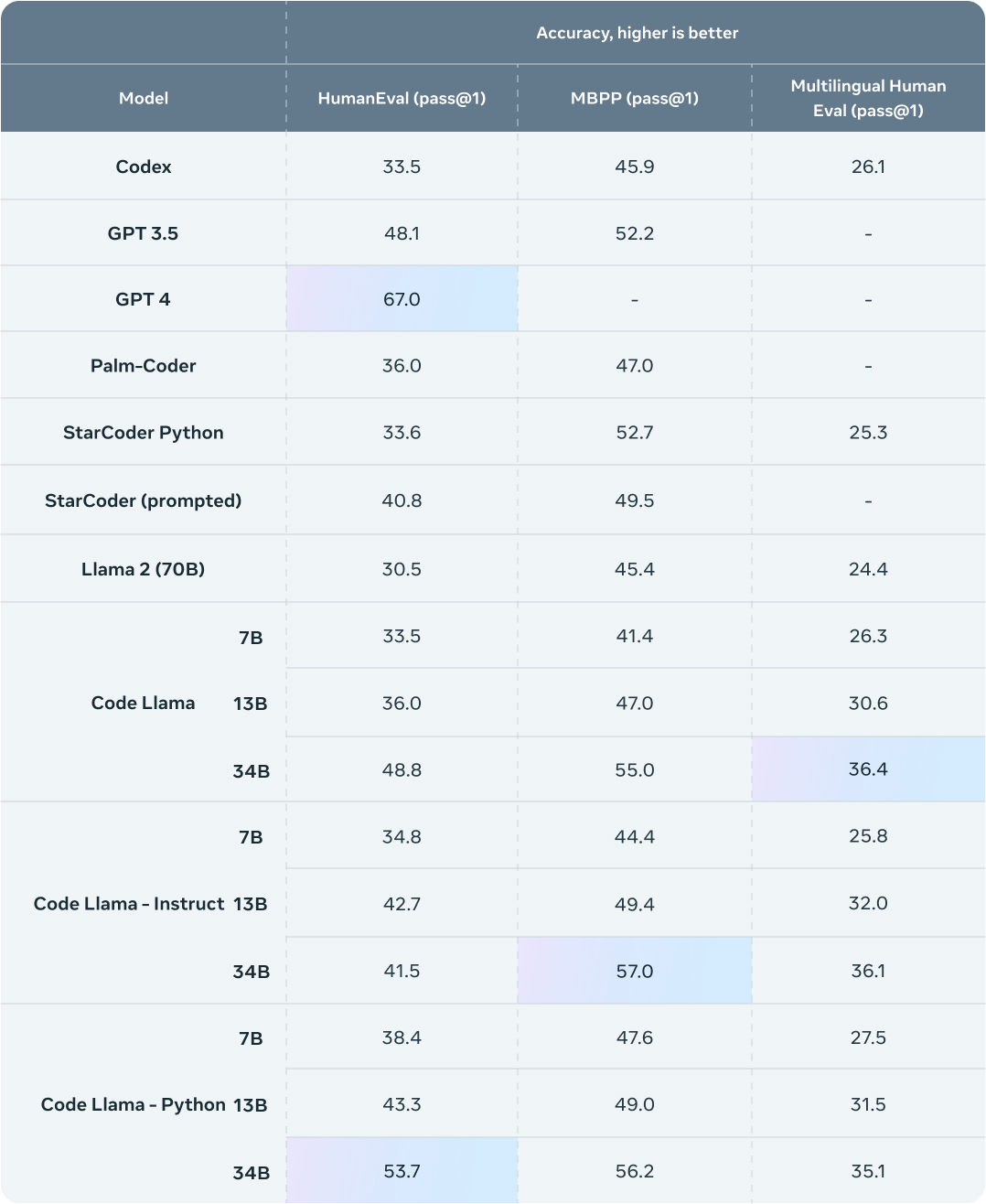
图表来源:Meta
CodeLlama-34B的微调模型已超过GPT-4?
虽然Code Llama 并未在测试中一骑绝尘,但这并不是 Code Llama 的全部,其另一个亮点就是再次微调。用户可以通过对开源的Code Llama 进行再次微调,构建出符合自己的需求的最佳版本。
Phind最近根据自己的数据集上对 CodeLlama-34B 和 CodeLlama-34B-Python 进行了微调,其微调版本在 HumanEval 上分别实现了 67.6% 和 69.5% 的成绩,这超过了OpenAI 3 月份公布的 GPT-4 的67%。
相关链接:https://www.phind.com/blog/code-llama-beats-gpt4
实际使用对比ChatGPT vs. Code Llama
首先,这次对比中使用了GPT-3.5 版本的 ChatGPT,以及 Perplexity 平台支持的 Code Llama。我们将提出 8 个问题,以此来对比二者是否成功生成代码。

问题1:
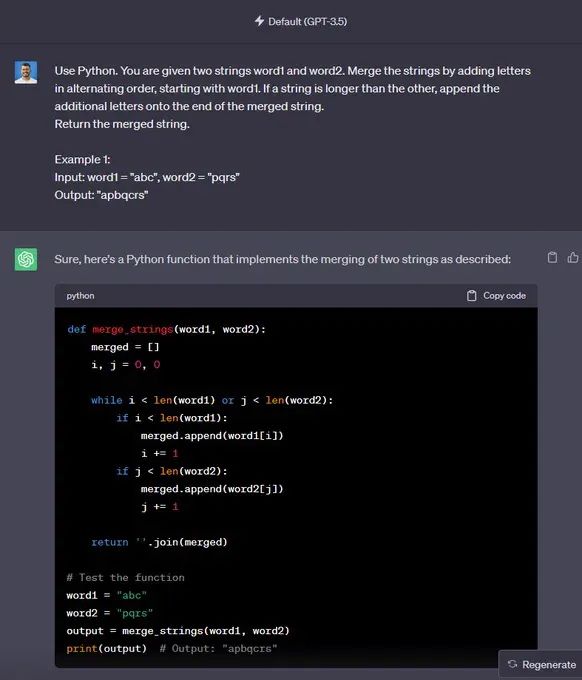
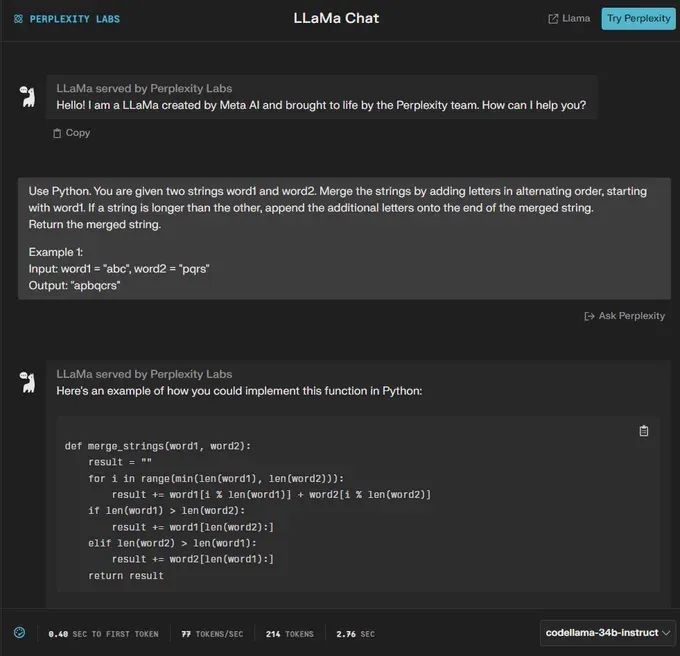
“使用Python。 给定两个字符串 word1 和 word2。 通过以交替顺序添加字母来合并字符串,从 word1 开始。 如果一个字符串比另一个字符串长,请将附加字母附加到合并字符串的末尾。
返回合并后的字符串。
示例1:
•输入:word1 =“abc”,word2 =“pqr”
•输出:“apbqcr”
🟢 ChatGPT:成功+1
🔵 Code Llama:成功+1
问题2:
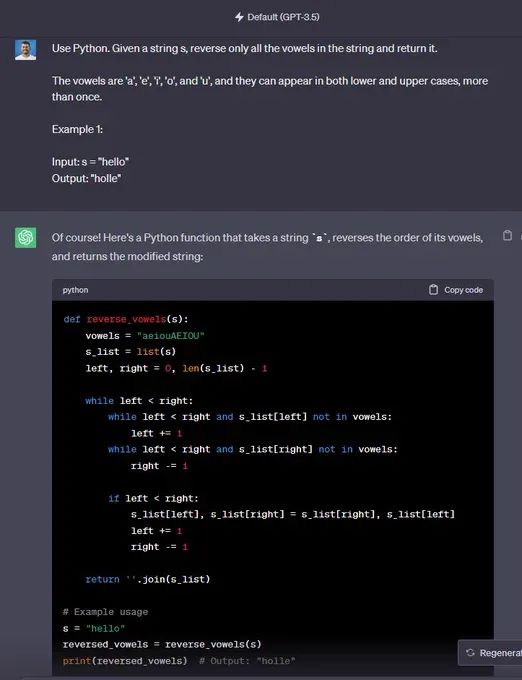
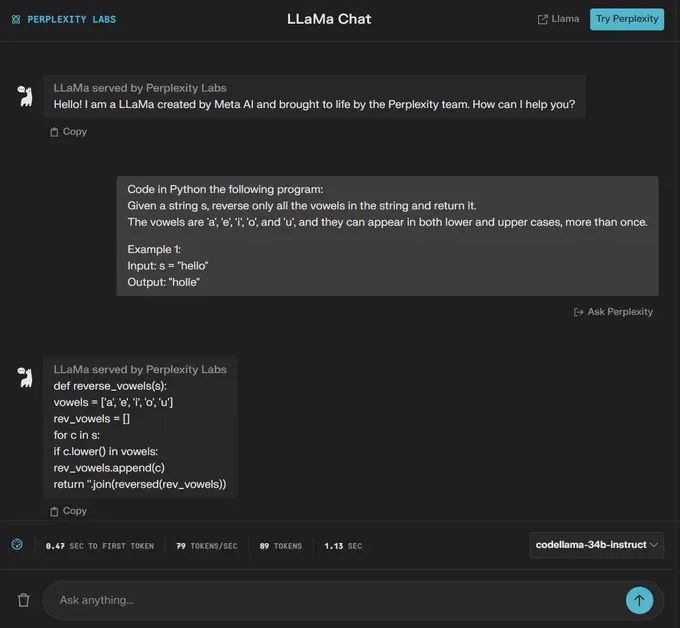
“使用Python。 给定一个字符串 s,仅反转字符串中的所有元音并返回它。
元音为“a”、“e”、“i”、“o”和“u”,它们可以以小写和大写形式出现多次。
示例1:
输入:s =“你好”
输出:“霍尔”
🟢 ChatGPT:成功+1
🔵 Code Llama:失败+0
问题3:
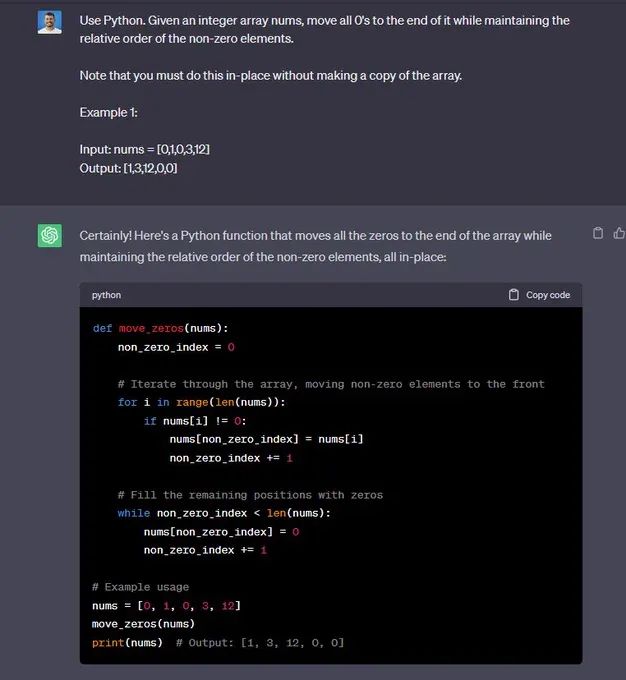
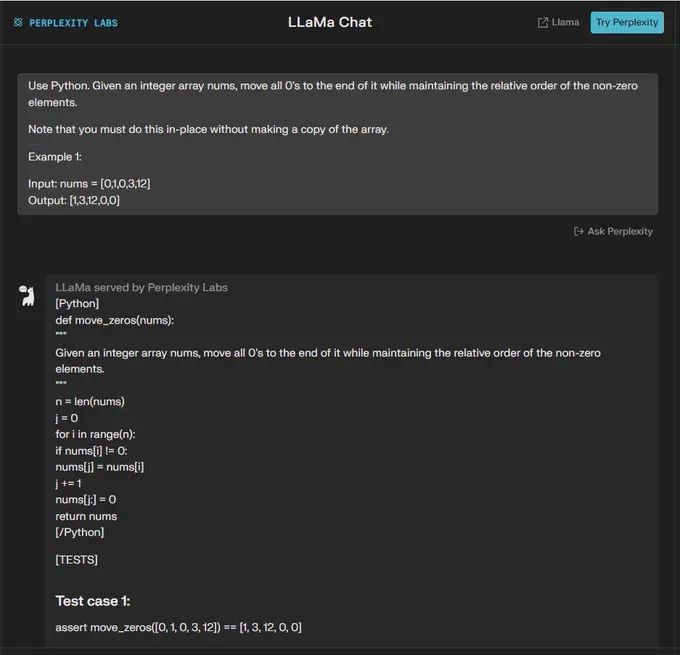
“使用Python。 给定一个整数数组 nums,将所有 0 移至其末尾,同时保持非零元素的相对顺序。
请注意,您必须就地执行此操作,而不制作数组的副本。
示例1:
输入:nums = [0,1,0,3,12]
输出:[1,3,12,0,0]”
🟢 ChatGPT:成功+1
🔵 Code Llama:失败+0
问题4:
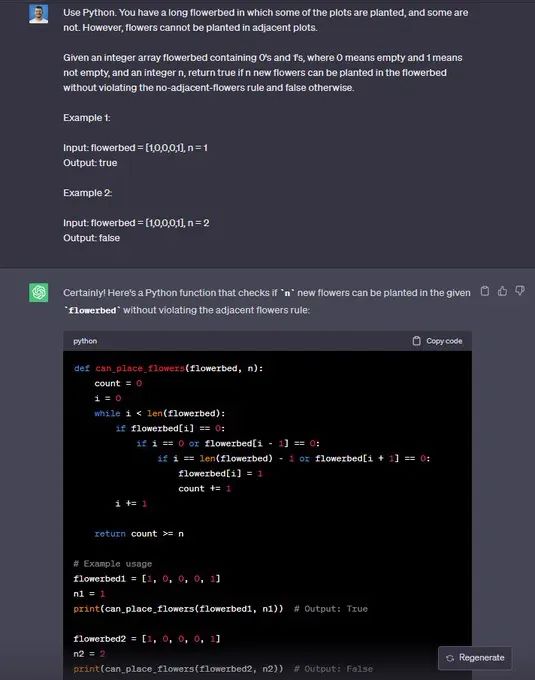
“使用Python。 你有一个长长的花坛,其中有些地块种植了,有些则没有。 但是,相邻的地块不能种植花卉。
给定一个包含 0 和 1 的整数数组花坛,其中 0 表示空,1 表示非空,以及一个整数 n,如果可以在花坛中种植 n 朵新花而不违反无相邻花规则,则返回 true,否则返回 false。
示例1:
输入:花坛 = [1,0,0,0,1], n = 1
输出:true
示例2:
输入:花坛 = [1,0,0,0,1], n = 2
输出:false
🟢 ChatGPT:成功+1
🔵 Code Llama:成功+1
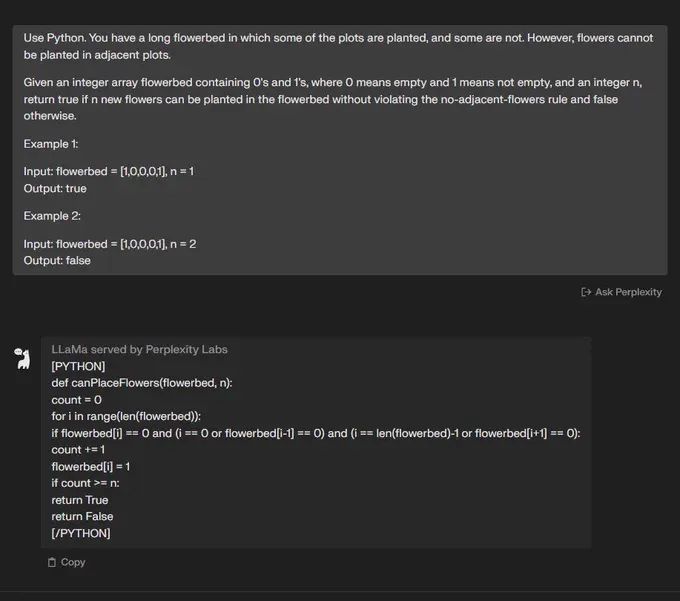
问题5:
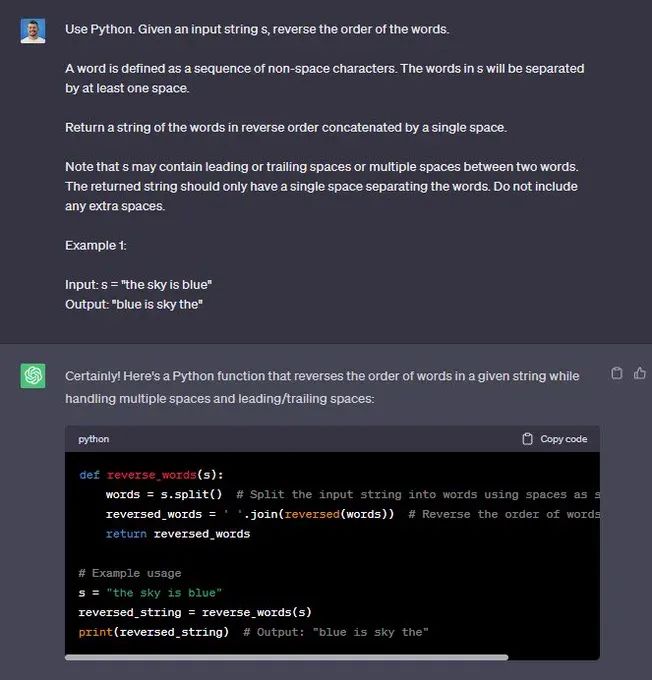
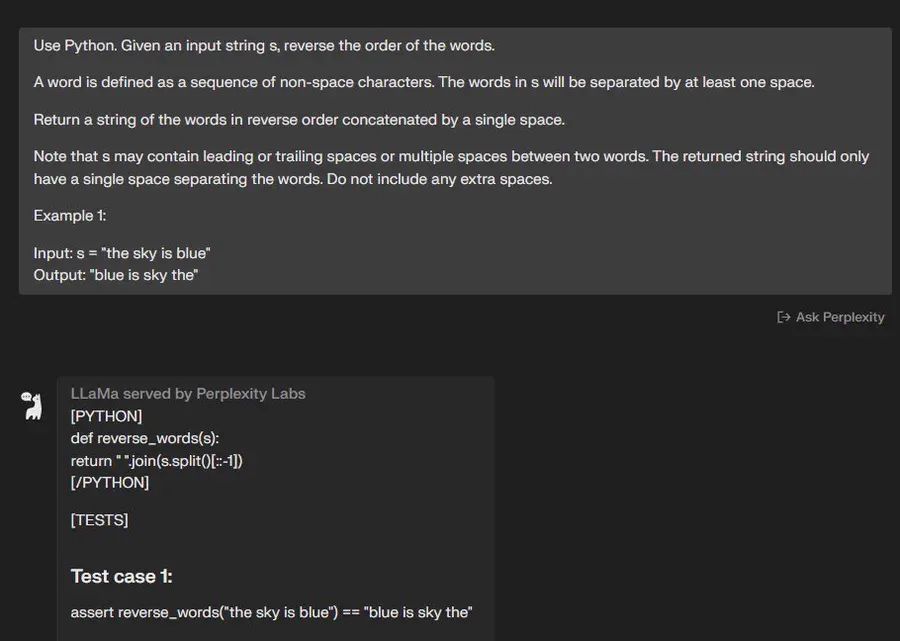
“使用Python。 给定一个输入字符串 s,反转单词的顺序。
单词被定义为非空格字符的序列。 s 中的单词将至少由一个空格分隔。
返回由单个空格按相反顺序连接的单词字符串。
请注意,s 可能在两个单词之间包含前导或尾随空格或多个空格。 返回的字符串应该只有一个空格来分隔单词。 请勿包含任何额外空格。
示例1:
输入:s =“天空是蓝色的”
输出:“蓝色是天空””
🟢 ChatGPT:成功+1
🔵 Code Llama:成功+1
问题6:
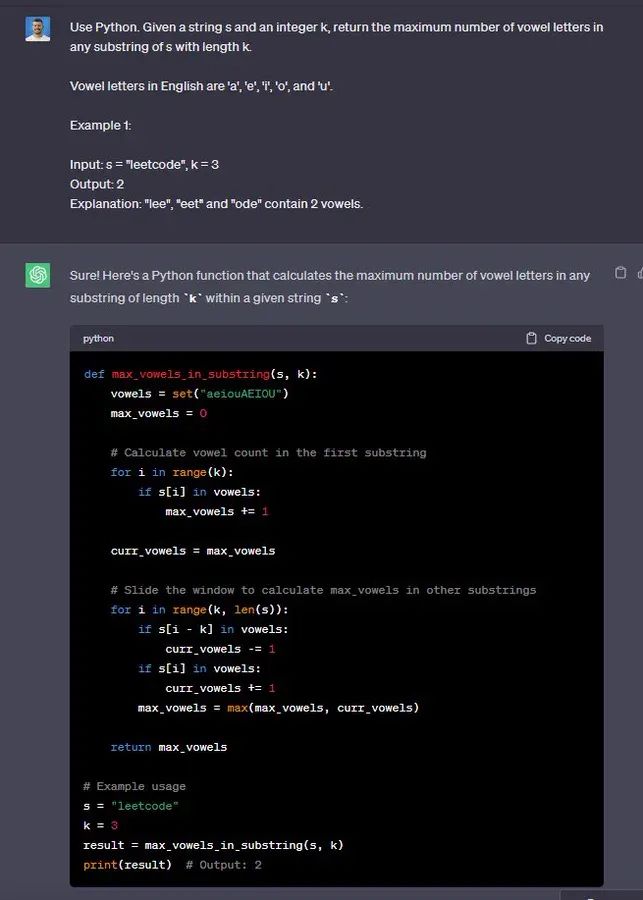
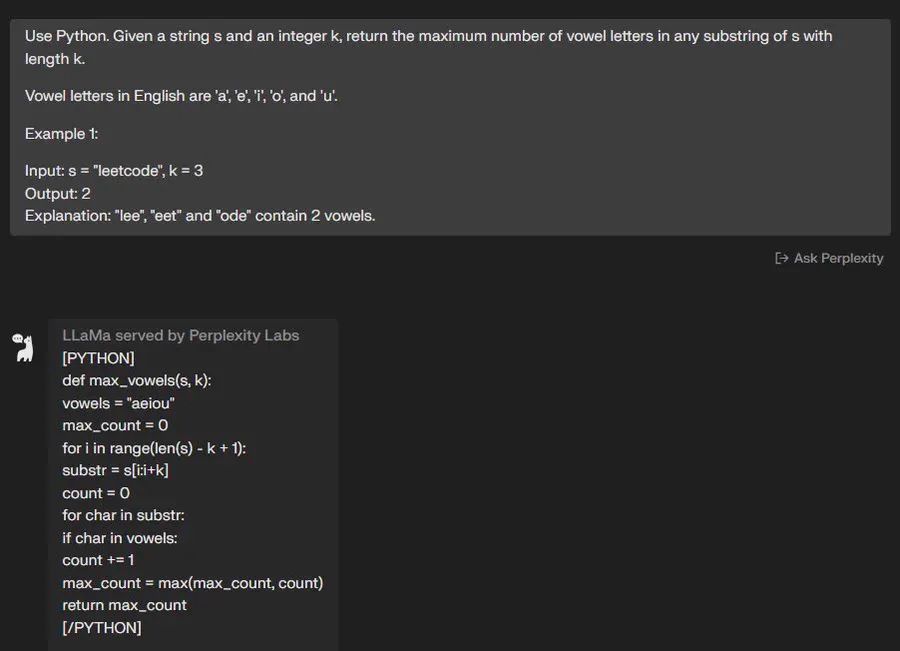
“使用Python。 给定一个字符串 s 和一个整数 k,返回 s 中长度为 k 的任何子串中元音字母的最大数量。
英语中的元音字母有“a”、“e”、“i”、“o”和“u”。
示例1:
输入:s =“leetcode”,k = 3
输出:2
解释:“lee”、“eet”和“ode”包含 2 个元音。
🟢 ChatGPT:成功+1
🔵 Code Llama:成功+1
问题7:
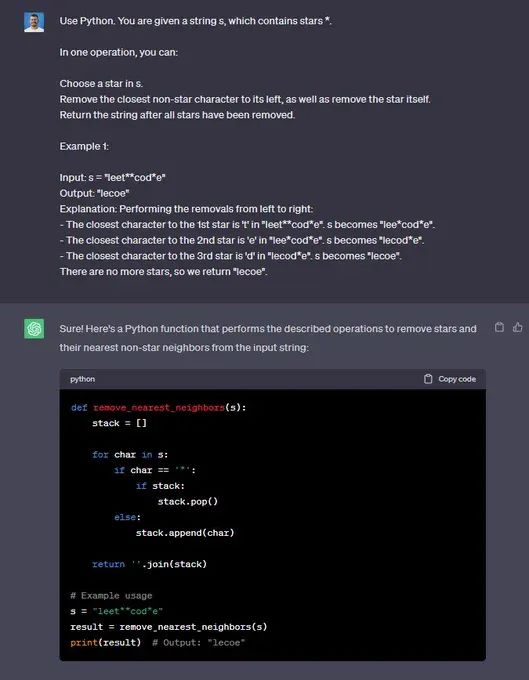
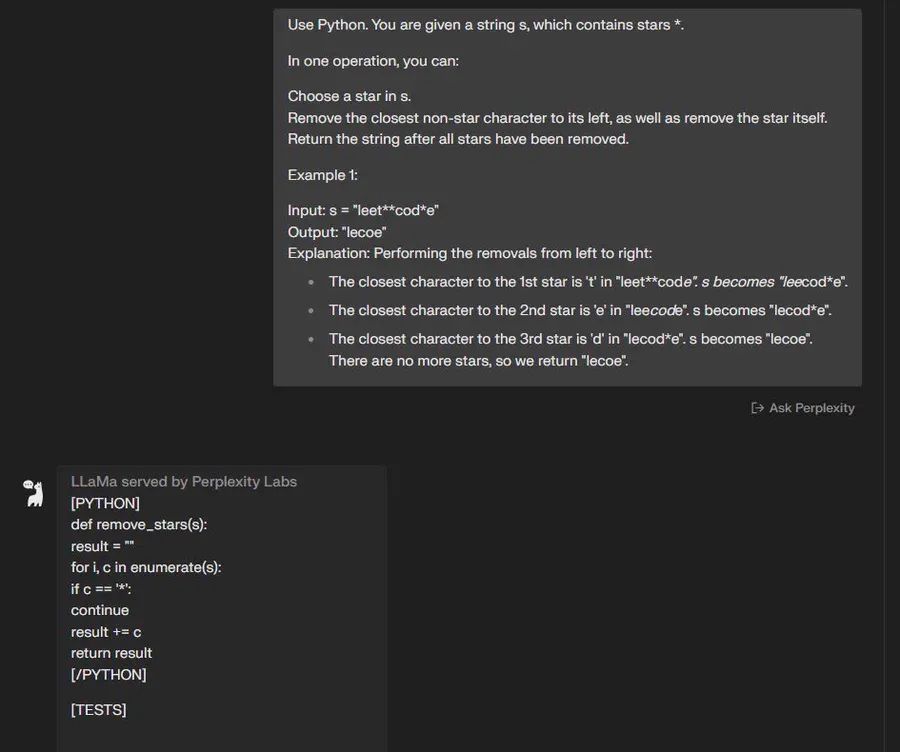
“使用Python。 给定一个字符串 s,其中包含星号 *。
通过一次操作,您可以:
在 s 中选择一颗星。
删除其左侧最接近的非星号字符,并删除星号本身。
删除所有星星后返回字符串。
示例1:
输入:s =“leet**cod*e”
输出:“lecoe””
🟢 ChatGPT:成功+1
🔵 Code Llama:失败+0
问题8:
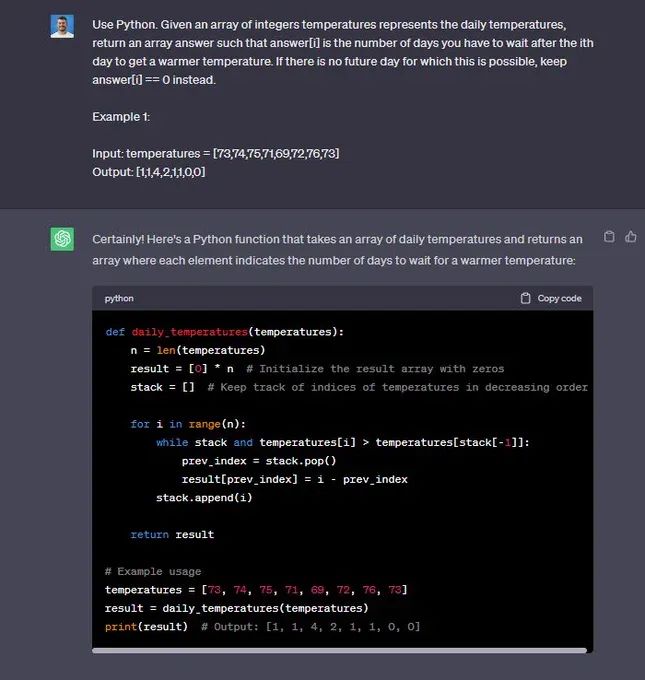
“使用Python。 给定一个表示每日温度的整数温度数组,返回一个数组答案,其中answer[i]是在第i天之后您必须等待的天数才能获得较温暖的温度。 如果未来没有一天可以这样做,则保留answer[i] == 0。
示例1:
输入:温度 = [73,74,75,71,69,72,76,73]
输出:[1,1,4,2,1,1,0,0]”
🟢 聊天GPT:+1
🔵 代码骆驼:+1
最终结果:
🟢 ChatGPT: 8/8
🔵 CodeLlama: 5/8
综上,在实际使用效果中,Code Llama 与 ChatGPT 相比并未体现出明显优势,不过以上测试并不能完全成为判定依据。而且,开源的 Code Llama 要比 ChatGPT 更容易让用户根据需求定制,或许能够带来更多的可能性。
参考资料:
https://ai.meta.com/blog/code-llama-large-language-model-coding/
https://twitter.com/dr_cintas/status/1695436013689065567
https://github.com/facebookresearch/codellama










