尽管人工智能算法具备着给人类发展带来巨大益处的潜力,但是对该技术潜在风险的担忧也不容忽视。其中的一个风险便是ChatGPT等大语言模型(large language model ,LLM)所生成的文本可能包含误导用户的错误事实和偏见。随着人们开始使用 ChatGPT 检索信息和生成新内容,大语言模型所提供的答案中存在的政治偏见,可能会产生负面影响,效果类似于传统媒体或社交媒体偏见对政治行为或者选举的影响。
麻省理工大学经济学教授Acemoglu(2021)认为,人工智能技术将对我们生活的多个方面产生变革性影响,对经济和政治产生重要影响。然而,与其他技术一样,人们如何使用人工智能将决定其效果对社会是最有利还是最有害。尽管最近有文献探讨社交媒体及其对人工智能的使用如何塑造甚至损害民主进程(Levy,2021;Zhuravskaya, 2020),但大语言模型为人工智能和政治造成了不同程度的扭曲。一个典型的担忧是人工智能驱动的系统如何根据人们的特征(例如性别、种族、年龄,或者更细微的政治信仰)来进行歧视(Peters,2022)。
ChatGPT 作为一个交互式工具,可以让用户提出问题并获取事实信息。先前的研究表明,大语言模型(LLM) 会影响用户的观点(Jakesch et al., 2023)。因此,ChatGPT 或其他大语言模型所以提供的答案是否存在偏见是一个值得研究的问题。
媒体偏见(media bias)对于本研究也有借鉴意义。由于媒体有告知公众事实的义务,因此出现了有关其偏见的重要问题。研究媒体偏见的一种途径是通过建模了解偏见的渠道和影响(Castañeda & Martinelli, 2018;Gentzkow & Shapiro, 2006)。另一种是实证分析偏见的决定因素和后果。我们可以根据经验分析媒体是否存在偏见,并研究它是否以及如何产生有害影响,特别是在民主进程方面(Levendusky,2013;Bernhardt ,2008)。政治家认识到媒体的重要性,经常制定最合适的媒体战略(Ozerturk,2018)或利用广告和背书来影响选民(Chiang & Knight,2011;Law,2021)。媒体报道可以将当地事件的影响扩大到全国范围,从而提高其政治相关性(Engist & Schafmeister,2022)。媒体甚至可以通过抹黑和诽谤政治对手来实施破坏(Chowdhury & Gürtler,2015)。可以说,大语言模型可以发挥与媒体类似的影响力(Jakesch et al., 2023)。然而,一个更基本的问题是如何衡量大语言模型的偏见。尽管有公认的衡量媒体政治偏见的方法(Groseclose & Milyo,2005;Bernhardt et al.,2008),但这种方法不能完全适用于对大语言模型的验证。
三、实证研究方法
1. 政治罗盘问题设计
本研究首先使用政治罗盘(Political Compass, www.politicalcompass.org)的问卷量表,来衡量ChatGPT回答的政治倾向,因为它的问题涉及政治的两个重要且相关的维度(经济和社会)。因此,政治罗盘可以衡量一个人在经济范围上是偏左还是偏右。从社会角度来看,它衡量一个人是威权主义者还是自由主义者。它产生了四个象限,我们列出了相应的历史人物原型:威权主义左派——约瑟夫·斯大林;威权主义右派——温斯顿·丘吉尔;自由主义者左派——圣雄甘地;或自由主义右派——弗里德里希·哈耶克。
研究设置的政治罗盘将问题分为四级,回答选项为“(0) 非常不同意”、“(1) 不同意”、“(2) 同意”和“(3) 非常同意”。没有中间选择,因此ChatGPT必须选择非中立立场。
一个潜在的担忧是政治罗盘的问题是否具有足够的心理测量特性。我们认为这在我们的案例中不是一个重要问题。政治罗盘中问题所具有的关键特性是,问题的答案取决于政治信仰。我们要求 ChatGPT 在不指定任何个人资料的情况下回答问题,冒充民主党人或冒充共和党人,每次冒充都会有 62 个答案。然后,我们衡量非模仿答案与民主党或共和党模仿答案之间的关联。因此,每个问题都是对自身的控制,我们不需要计算答案将如何将受访者定位在经济和社会取向轴上。尽管如此,我们还使用另一种调查问卷,即 IDR 实验室政治坐标测试 (Political Coordinates Test),作为稳健性测试。
2. 当前大语言模型的拟人效果
最近的几篇论文讨论了大语言模型模仿人类的能力,在各种场景下提供类似人类的响应。Argyle(2022) 是最早的研究之一,表明 ChatGPT 的基本模型 GPT-3 能够根据人口统计数据生成复制多个子组的已知分布的答案。在一篇以教育为重点的论文中,Cowen 和 Tabarrok(2023)提出了一系列经济学教学策略。其中之一就像专家一样向 ChatGPT 寻求答案,例如,“通货膨胀的原因是什么,诺贝尔奖获得者米尔顿·弗里德曼可能会解释这一点?” 与我们的用途更密切相关的另一种用途是模拟某种类型的人。Cowen 和 Tabarrok(2023)建议用大语言模型制定人物角色,例如“中西部/男性/共和党/牙医”,以获得经济学实验的答案。最后,Parker (2023) 证明 ChatGPT 可以模拟人类行为,根据智能体的经验和环境采取不同的行动。总之,考虑到这些新兴文献中的所有证据,ChatGPT 很可能能够正确地模仿民主党或共和党等相对简单的角色。
3. 大语言模型的随机性
本研究亟待解决的一个关键问题是大语言模型的随机性(randomness)。温度参数(temperature parameter)可以用于控制生成结果的多样性和随机性。然而,即使将其设置为尽可能低的水平(比如0),同一问题的答案依然会有所不同。
解决随机性的第一步是向每个模仿者询问相同的问题 100 次。在每次运行中,我们都会随机化问题的顺序,以防止标准化回答或上下文偏差。在第二步中,我们使用这 100 轮响应来计算每个答案和模拟的引导平均值 6,重复 1000 次。我们的程序(如图 1 所示)可以得出更可靠的推论。
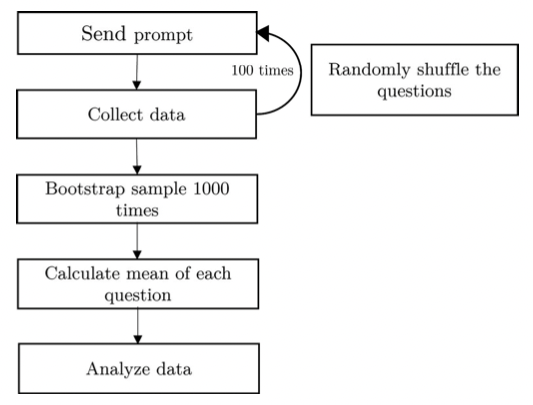
图1:实验数据收集概略
我们使用这些答案的增强方法进行主要分析。我们测量默认的DefaultGPT(即不指定任何特定配置文件或行为)的答案与给定模拟(PoliticalGPT)的答案之间的关联程度。下图的等式显示了这一关联,其中 DefaultGPTi 是 ChatGPT 针对调查问卷中第 i-eth 问题提供的 100 轮回答的 1000 次随机抽样平均值。PoliticalGPTi是二分变量,对于ChatGPT来说,要么冒充民主党人,要么冒充共和党人。
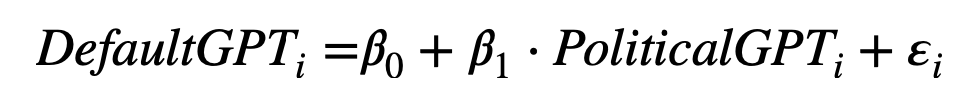
我们的模拟策略包括一个基础测试,其中 ChatGPT 模拟一个普通的民主党人或共和党人。为了增强 ChatGPT理解民主党和共和党概念的保证,我们利用我们的策略让 ChatGPT 模仿激进的民主党或共和党。通过使用这种剂量反应方法,我们可以验证关系是否会按照更极端的观点发生预期的变化。
4. 数据
在正式进入分析之前,我们提供证据表明 ChatGPT理解普通民主党或共和党以及激进民主党或共和党的概念。表 1 包含了训练 ChatGPT 的提示词以及 ChatGPT 提供的完整答案,表明它可以识别民主党和共和党的立场以及平均立场和激进立场之间的差异。因此,要求它模仿任何一方都应该提供每种政治立场的观点。

表 1:实验训练ChatGPT提示词及其回答
考虑到 ChatGPT 固有的随机性以及它生成出不准确答案的可能性,我们通过计算政治罗盘工具如何定位每种政治立场问卷的 100 轮答案来进行验证。这种方法提供了对政治观点的细致入微的理解,我们利用它对 ChatGPT 答案的概率性质及其平均和激进拟人化的行为进行可视化分析。
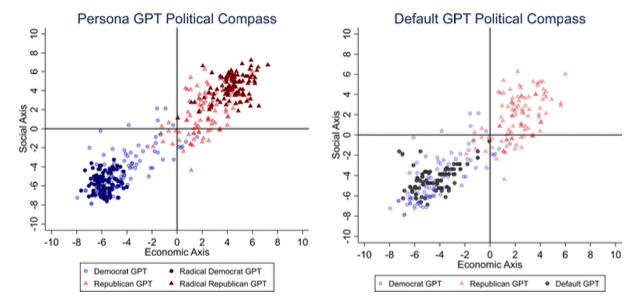
图2:ChatGPT回答的可视化结果









