FlashAttention-2提出后,便得到了大量关注。本文将具体讲述FlashAttention-2的前世今生,包括FlashAttention1&2的原理解析、加速效果比较以及面向AIGC的加速实践,在这里将相关内容与大家分享~将 Transformers 扩展到更长的序列长度一直是过去几年的一个热点问题,这将有助于提高语言建模和高分辨率图像理解的能力,也有利于音频和视频生成方面的新应用场景研发。Attention层是扩展到更长序列的主要瓶颈,因为它的运行时间和内存占用是序列长度的二次方。使用近似计算的Attention方法,可以通过减少FLOP计算次数、甚至于牺牲模型质量来降低计算复杂性,但通常无法实现大比例的加速。由斯坦福大学提出的FlashAttention方法,让使用更长sequence计算Attention成为可能,并且通过线性级别的增长来节省内存以及加速计算。因为FlashAttention没有进行近似计算,所以也没有精度损失。然而,FlashAttention的实际速度仍然和理论上的运算速度差距较大,仅达到理论最大 FLOPs/s 的 25-40%。效率低下的原因主要是不同线程块和warp之间的工作分区不理想,导致低占用率或不必要的共享内存读/写。为此,2023年7月,论文作者进一步提出了FlashAttention-2,实现了Attention计算速度的大幅度提升。
▐ 主要内容
FlashAttention主要关注IO-aware,进一步优化GPU显存的读写效率。这是一种 IO 感知的精确Attention算法,它使用tiling(这里可以理解为分块)来减少 GPU 高带宽内存 (HBM) 和 GPU 片上 SRAM 之间的内存读/写次数。这里的HBM可以理解为显存,SRAM可以理解为cache。通过测试IO复杂性,相比标准 Attention,FlashAttention需要更少的 HBM 访问,并且对于不同的SRAM 大小来说都是有效的。除此以外,FlashAttention还可以扩展到block-sparse attention,产生比任何现有近似注意力方法更快的近似注意力算法。FlashAttention与 MLPerf 1.1 训练速度相比,对于BERT-large(序列长度 512)实现端到端wall-clock加速15%,对于GPT-2(序列长度 1K)加速 3 倍。FlashAttention 和block-sparse FlashAttention 可在 Transformers 中实现更长的上下文,从而产生更高质量的模型,GPT-2 上的困惑度提升0.7,长文档分类的test结果提高 6.4 个点。▐ 主要操作
背景知识:
上图的左图,表示存储结构,可以简单理解为:SRAM表示缓存,HBM表示显存,DRAM表示内存。
在不访问整个输入的情况下优化attention计算,并减少相关计算量。重构attention计算,将输入分割成块,并对分块进行多次传递,从而逐步执行attention计算(该步骤称为tiling)。
如上图所示,FlashAttention 使用tiling来防止在相对较慢的 GPU显存上实现大型 𝑁 × 𝑁 注意力矩阵(虚线框)计算。在外部循环(红色箭头)中,FlashAttention 循环遍历 K 和 V 矩阵块,并将它们加载到快速片上 SRAM。在每个块中,FlashAttention 循环遍历 Q 矩阵块(蓝色箭头),将它们加载到 SRAM,并将注意力计算的输出写回 HBM。
将输入Q、K、V矩阵分成很多块,将它们从较慢的HBM加载到较快的SRAM,然后在SRAM计算关于这些块的注意力输出。对每个块的计算结果缩放之后进行add操作,则得到正确的结果,具体伪代码如图:

FlashAttention不专门存储用于后向计算的大型中间计算结果。在SRAM中存储前向计算中的 softmax 归一化因子,以便在后向传递计算梯度的时候快速得到中间结果,这比从 HBM 读取中间计算结果的标准方法更快。FlashAttention不存储前向计算中𝑂(𝑁2)复杂度的中间值,但是后向传递通常需要矩阵 S, P ∈ R𝑁 ×𝑁 来计算相对于 Q、K、V 的梯度。通过存储输出 O 和 softmax 归一化统计量 (𝑚, ℓ),则可以在 SRAM 中的 Q、K、V 块的后向计算中快速重新计算注意力矩阵 S 和 P。这可以看作是checkpoint的一种形式。如下图所示,FlashAttention由于tiling分块操作和recomputing操作,增加了一些计算次数。但是还是通过使用SRAM减少了显存占用,通过减少hbm访问次数加快了attention计算。
▐ Block-Sparse FlashAttention
论文还提出了Block-sparse FlashAttention,其IO复杂度比FlashAttention小,与稀疏度成正比。非0矩阵越少(即0矩阵越多),稀疏化来压缩数据的空间就越大,block-sparse加速就越明显。上图中,IO复杂度与稀疏性成正比,随着稀疏性的增加(非0矩阵增加),Block-sparse FlashAttention的运行时间成比例地提高。▐ 小结
总的来说,FlashAttention有如下优点:
hbm访问次数降低,所以计算更快
在sram中计算attention,并对于后向计算提前保留中间结果,所以显存占用更少
可以使用更长的sequence,使得模型训练效果更好
对于attention计算,加速明显。如果加上稀疏化处理,速度会更快。
▐ 主要内容
FlashAttention 的整体速度仍然和单独进行矩阵乘法 (GEMM) 的运算速度差距较大,仅达到理论最大 FLOPs/s 的 25-40%。作者观察到效率低下的原因是不同线程块和warp之间的工作分区不理想,导致低占用率或不必要的共享内存读/写。最新提出 FlashAttention-2,通过更好的工作分区来解决这些问题,主要包含的操作:1.调整算法以减少非矩阵乘运算的计算次数。2.跨不同线程块进行并行化注意力计算。3.在每个线程块内, 在 warp 之间优化工作分配以减少共享内存的通信。与FlashAttention 相比,FlashAttention-2速度提高了约 2 倍,达到 A100 上理论最大 FLOPs/s 的 50-73%,接近 GEMM 操作的效率。根据经验验证,当使用端到端来训练 GPT 式模型时,FlashAttention-2 的训练速度高达每 A100 GPU 225 TFLOPs/s(模型 FLOPs 利用率为 72%)。不同设置(有或没有causal mask、不同头部尺寸)的测试表明,FlashAttention-2 比 FlashAttention 实现了约 2 倍的加速,在前向传递中达到理论最大吞吐量的 73%,在后向传递中达到理论最大吞吐量的 63%。▐ 主要操作
调整算法以减少非 matmul(矩阵乘法) FLOP 的数量,同时不改变输出。虽然非 matmul FLOP 只占总 FLOP 的一小部分,但它们由于 GPU 具有专门的矩阵乘法单元,非矩阵乘法的运算需要更长的时间来执行,矩阵乘法吞吐量可以比非矩阵乘法吞吐量高出16倍。因此,减少非 matmul FLOP 并尽可能多的进行 matmul FLOP 非常重要。吞吐量是指单位时间内完成的任务数量或数据处理量。在这个上下文中,吞吐量指的是执行矩阵乘法操作时的性能表现,以及执行其他非矩阵乘法操作时的性能表现。这句话的意思是,执行矩阵乘法操作时,系统能够以每单位时间处理更多的任务或数据,其数量可以高达非矩阵乘法操作时的16倍。这表明矩阵乘法操作在性能上比其他操作更加高效。
Forward pass:优化qkv的softmax计算中非矩阵运算Backward pass:FlashAttention-2的后向传递与FlashAttention几乎相同,主要区别在于需要进行梯度计算与更新。这里做了一个小调整,只使用求和结果𝐿,而不是 softmax 中的行式最大值和行式指数和。
除了batchsize维度和head数目维度,还在序列长度维度上对前向传播和反向传播进行并行化处理,提高并行性。在序列较长的情况下,提高GPU资源的占用率。FlashAttention对于batchsize和head数目进行并行化处理,FlashAttention2基于序列长度进行并行化。当批量大小和head数量较小时,序列长度上增加的并行性有助于提高占用率(正在使用的 GPU 资源的比例),从而在这种情况下实现加速。
Forward pass:对批量维度和头数维度进行并行化,如 FlashAttention 中所做的那样。对于外循环(在序列长度上),将它们调度到不需要彼此通信的不同线程块上,每个工作线程负责关注矩阵的一行block块。外循环每次处理一行block,内循环每次处理这一行中的一列block,这和FlashAttention处理方式是不同的。
Backward pass:不同列块之间唯一共享的计算是算法 2 中更新的dQ,其中我们需要将 dQ从 HBM 加载到 SRAM,然后在片上通过 dQ更新,并写回 HBM。我们使用原子添加在不同线程块之间进行通信以更新 dQ。我们也在序列长度维度上进行并行化,并为后向传递的每一列block块安排 1 个工作线程(和前向传递是反过来的)。
在一个注意力计算的block内,在一个thread block的不同warp之间优化工作划分,以减少通信和共享内存的读/写。
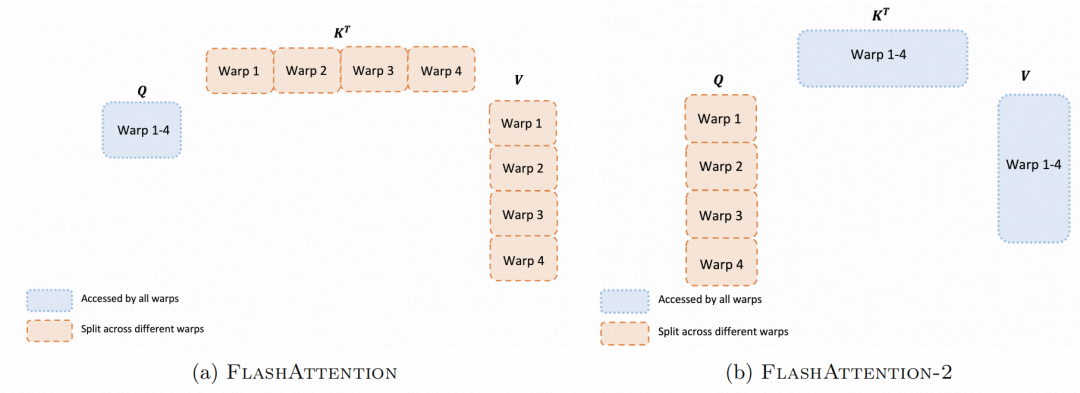
在每个线程块内,我们也必须决定如何在不同的 warp 之间划分工作。我们通常每个线程块使用 4 或 8 个 warp,分区如上图所示。
Forward pass:对于每个块,FlashAttention 将 K 和 V 分割到 4 个 warp 上,同时保持 Q 可被所有 warp 访问。每个warp相乘得到 QK⊤ 的slice,然后它们需要与 V 的slice相乘并进行通信以将结果相加。这称为“split-K”方案。然而,这是低效的,因为所有 warp 都需要将其中间结果写入共享内存,进行同步,然后将中间结果相加。这些共享内存读/写会减慢 FlashAttention 中的前向传播速度。在 FlashAttention-2 中,我们将 Q 分成 4 个经线,同时保持所有经线均可访问 K 和 V。在每个扭曲执行矩阵乘法以获得 QK⊤ 切片后,它们只需与共享的 V 切片相乘即可获得相应的输出切片。warp 之间不需要通信。共享内存读/写的减少可以提高速度。
warp:由多个thread组成,是编程层面的概念。
flash1:k和v被分为4个不同的warp,q和k计算、再和v计算,每一次计算的中间结果都要写入共享内存,并在之后被读取。这样就增加了共享内存的读写次数、拖慢了速度。
flash2:将q分为4个不同的warp,然后计算qk、计算v。但是这里k和v不需要通信,所以计算v的时候,不需要新的内存读写。这样就减少了读写次数、加快了程序。
Backward pass:对于后向传递,我们选择对warp进行分区以避免“split-K”方案,从而减少共享内存的读/写次数,并再次提高速度。由于所有不同输入和梯度 Q、K、V、O、dO、dQ、dK、dV 之间的依赖性更加复杂,它需要一些同步操作。▐ 小结
FlashAttention-2可以加速attention计算。测量FlashAttention-2 在不同序列长度上的运行时间,并与 PyTorch、FlashAttention 和 Triton 中的 FlashAttention 中的标准实现进行比较。FlashAttention-2 比 FlashAttention 快 1.7-3.0 倍,比 Triton 中的 FlashAttention 快 1.3-2.5 倍,比标准注意力实现快 3-10 倍。FlashAttention-2可以加速端到端训练。当使用端到端在 2k 或 8k 序列长度上训练大小为 1.3B 和 2.7B 的 GPT 型模型时,FlashAttention-2 与 FlashAttention 相比可实现高达 1.3 倍的加速,与基线相比可实现 2.8 倍的加速 没有FlashAttention。每个 A100 GPU 的 FlashAttention-2 速度高达 225 TFLOPs/s(模型 FLOPs 利用率为 72%)。FlashAttention-2 比 FlashAttention 快 2 倍,可以用之前训练 8k 上下文模型的时间,来训练具有 16k 更长上下文的模型。使用更长的context训练模型,可以更好理解长篇书籍和报告、高分辨率图像、音频和视频。
FlashAttention-2加速实践
▐ 时间与显存的优化效果
对于qkv计算,比较FlashAttention2与custom pytorch、xformers(FlashAttention1)的时间与显存消耗。如果只考虑QKV计算,flash attention2耗时是xformers(flash attention1)的一半,内存节省也更多一些。
flash attention2耗时是xformers(flash attention1)的一半,内存节省也更多一些
test 0 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>shape: (9, 351, 16, 64), dtype: torch.bfloat16, causal: Truecustom pytorch time: 0.000754, peak memory: 113 MBflash attention time: 0.000103, speedup: 7.29; peak memory: 45 MB, save: 60%xformers time: 0.000255, speedup: 2.95; peak memory: 63 MB, save: 44%test 1 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>shape: (9, 351, 16, 64), dtype: torch.bfloat16, causal: Truecustom pytorch time: 0.000703, peak memory: 131 MBflash attention time: 0.000106, speedup: 6.63; peak memory: 57 MB, save: 56%xformers time: 0.000252, speedup: 2.80; peak memory: 70 MB, save: 46%test 2 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>shape: (9, 351, 16, 64), dtype: torch.bfloat16, causal: Truecustom pytorch time: 0.000721, peak memory: 131 MBflash attention time: 0.000106, speedup: 6.78; peak memory: 57 MB, save: 56%xformers time: 0.000263, speedup: 2.74; peak memory: 70 MB, save: 46%test 3 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>shape: (9, 351, 16, 64), dtype: torch.bfloat16, causal: Truecustom pytorch
time: 0.000704, peak memory: 131 MBflash attention time: 0.000105, speedup: 6.71; peak memory: 57 MB, save: 56%xformers time: 0.000249, speedup: 2.82; peak memory: 70 MB, save: 46%test 4 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>shape: (9, 351, 16, 64), dtype: torch.bfloat16, causal: Truecustom pytorch time: 0.000700, peak memory: 131 MBflash attention time: 0.000110, speedup: 6.35; peak memory: 57 MB, save: 56%xformers time: 0.000254, speedup: 2.75; peak memory: 70 MB, save: 46%test 5 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>shape: (9, 351, 16, 64), dtype: torch.bfloat16, causal: Truecustom pytorch time: 0.000766, peak memory: 131 MBflash attention time: 0.000106, speedup: 7.25; peak memory: 57 MB, save: 56%xformers time: 0.000252, speedup: 3.04; peak memory: 70 MB, save: 46%test 6 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>shape: (9, 351, 16, 64), dtype: torch.bfloat16, causal: Truecustom pytorch time: 0.000684, peak memory: 131 MBflash attention time: 0.000101, speedup: 6.77; peak memory: 57 MB, save: 56%xformers time: 0.000268, speedup: 2.56; peak memory: 70 MB, save: 46%test 7 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>shape: (9, 351, 16, 64), dtype: torch.bfloat16, causal: Truecustom pytorch time: 0.000717, peak memory: 131 MBflash attention time: 0.000110, speedup: 6.52; peak memory: 57 MB, save: 56%xformers
time: 0.000254, speedup: 2.82; peak memory: 70 MB, save: 46%test 8 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>shape: (9, 351, 16, 64), dtype: torch.bfloat16, causal: Truecustom pytorch time: 0.000700, peak memory: 131 MBflash attention time: 0.000100, speedup: 6.98; peak memory: 57 MB, save: 56%xformers time: 0.000253, speedup: 2.77; peak memory: 70 MB, save: 46%test 8 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>shape: (9, 351, 16, 64), dtype: torch.bfloat16, causal: Truecustom pytorch time: 0.000700, peak memory: 131 MBflash attention time: 0.000100, speedup: 6.98; peak memory: 57 MB, save: 56%xformers time: 0.000253, speedup: 2.77; peak memory: 70 MB, save: 46%test 9 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>shape: (9, 351, 16, 64), dtype: torch.bfloat16, causal: Truecustom pytorch time: 0.000721, peak memory: 131 MBflash attention time: 0.000102, speedup: 7.10; peak memory: 57 MB, save: 56%xformers time: 0.000251, speedup: 2.87; peak memory: 70 MB, save: 46%
▐ 精度损失比较
计算FlashAttention2对于注意力机制的精度损失,与pytorch的计算精度进行对比。
绝大部分用例都可以通过测试,并且符合要求:
dQ Pytorch mean diff: 0.000698089599609375dK Pytorch mean diff: 0.0005950927734375dV Pytorch mean diff: 0.000537872314453125.Actual dropout fraction: 0.17163611948490143Output max diff: 0.001953125Output mean diff: 2.9206275939941406e-05Pytorch max diff: 0.0029296875Pytorch mean diff: 8.106231689453125e-05Attention max diff: 0.000244140625
Attention Pytorch max diff: 0.000732421875dQ max diff: 0.0025577545166015625dK max diff: 0.00390625dV max diff: 0.0078125dQ mean diff: 3.904104232788086e-05dK mean diff: 0.0001360177993774414dV mean diff: 0.0001475811004638672dQ Pytorch max diff: 0.00390625dK Pytorch max diff: 0.004150390625dV Pytorch max diff: 0.0078125dQ Pytorch mean diff: 8.702278137207031e-05dK Pytorch mean diff: 0.00025916099548339844dV Pytorch mean diff: 0.0002474784851074219.Actual dropout fraction: 0.17163611948490143Output max diff: 0.015625Output mean diff: 0.0002346038818359375Pytorch max diff: 0.015625Pytorch mean diff: 0.00064849853515625Attention max diff: 0.001953125Attention Pytorch max diff: 0.00390625dQ max diff: 0.01953125dK max diff: 0.033203125dV max diff: 0.0625dQ mean diff: 0.0003108978271484375dK mean diff: 0.00109100341796875dV mean diff: 0.0011749267578125dQ Pytorch max diff: 0.01806640625dK Pytorch max diff: 0.0390625dV Pytorch max diff: 0.0625dQ Pytorch mean diff: 0.00069427490234375dK Pytorch mean diff: 0.0020751953125dV Pytorch mean diff: 0.001953125...
FAILED tests/test_flash_attn.py::test_flash_attn_race_condition[0.0-128-128-False-dtype0] - assert FalseFAILED tests/test_flash_attn.py::test_flash_attn_race_condition[0.0-128-128-True-dtype0] - assert FalseFAILED tests/test_flash_attn.py::test_flash_attn_bwd_transpose[128-128-False-dtype0] - AssertionError: assert 236.75 <= (2 * 0.0009765625)FAILED tests/test_flash_attn.py::test_flash_attn_bwd_transpose[128-128-False-dtype1] - AssertionError: assert 22144.0 <= (2 * 0.0078125)FAILED tests/test_flash_attn.py::test_flash_attn_bwd_transpose[128-128-True-dtype0] - AssertionError: assert 2.724609375 <= (2 * 0.001953125)FAILED tests/test_flash_attn.py::test_flash_attn_bwd_transpose[128-128-True-dtype1] - AssertionError: assert 95.5 <= (2 * 0.015625)
FlashAttention2与参考方法的输出和梯度相比,误差很小并在可控范围内。对于不同的head dimensions, input dtype, sequence length, causal / non-causal,FlashAttention2的最大数值误差最多是 Pytorch的baseline中的数值误差的两倍。对于前向计算和后向计算。前向计算,是确定性的,每次测试结果可以复现。后向计算,非确定性(没有bit级别的确定性),每次结果可能有略微的不一样(比如输入不变,seed改变)。如果只做推理,则只涉及前向计算,所以计算是确定性的。
▐ 环境信息
NVIDIA A10, CUDA Version: 11.4, webui-1.5.1, eas推理平台
▐
加速效果
xformers(flash1):
| 文生图(512*512)(batchsize=1) | 文生图(512*512)(batchsize=4) |
| unet耗时(s) | 1 1 1 1 | 4 4 4 4 |
unet耗时(it/s) (step = 20) | 11.11it/s 11.27it/s 11.27it/s 11.27it/s | 4.33it/s 4.33it/s 4.33it/s 4.33it/s |
| 文生图(512*512) | 文生图(512*512)(batchsize=4) |
| unet耗时(s) | 1 1 1 1 | 4 4 4 4 |
unet耗时(it/s) (step = 20) | 11.13it/s 11.75it/s 11.46it/s 11.92it/s | 4.69it/s 4.69it/s 4.69it/s 4.68it/s |
相对于xformers(flash1),xformers(flash2)提速:
| unet过程提速 |
| 文生图加速(一次生成1图) | (11.57-11.23)/11.23=3% |
| 文生图加速(一次生成4图) | (4.69-4.33)/4.33=8.3% |
▐
精度比较
xformers(flash1)
| 文生图(512*512)_ouput1 | 文生图(512*512)_ouput2 |
 |  |
xformers(flash2)
| 文生图(512*512)_ouput1 | 文生图(512*512)_ouput2 |
 |  |
使用不同的加速方法,AIGC生成图像,均符合预期,无精度损失。
注:这里未固定seed,所以图像会有变化,但是生成效果符合预期。
▐ AIGC加速分析
使用flash_attention2,对sd加速,相比flash_attention1,加速比例并不高,或者说无法达到论文中那么高的加速比例。
flash_attention2主要是针对qkv计算进行加速,sd的推理过程中还有很多别的计算。推理过程中,进行采样(去噪),具有大量的计算,qkv计算只是推理计算的一部分。对于大图,计算量也更大,qkv的计算比例也更大,所以可以得到更多的加速效果。
SD模型的网络结构:
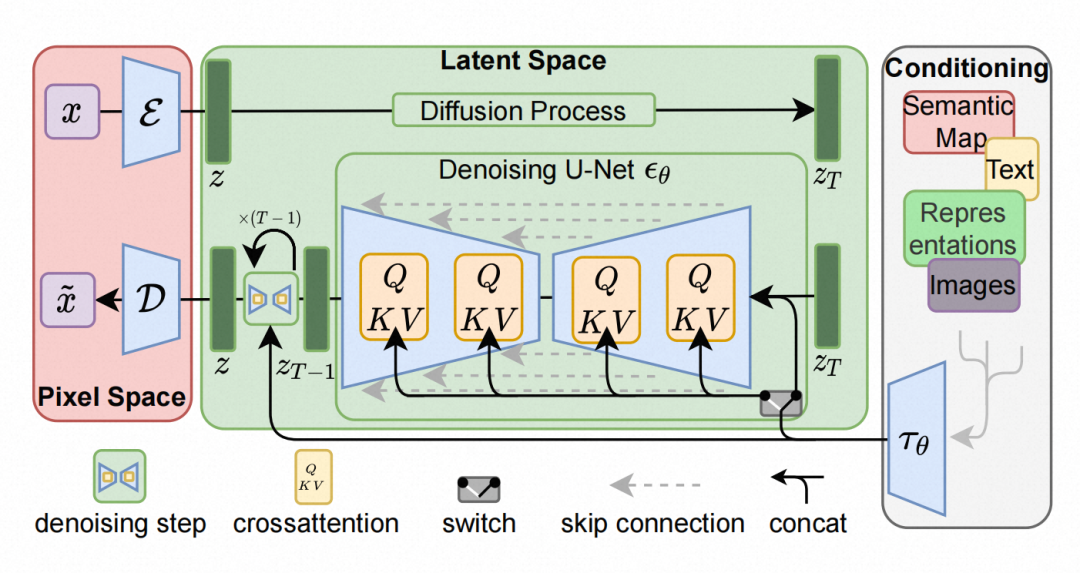
目前方法对于sd的提速,主要针对stable diffusion的神经网络本身。但是webui还有别的耗时:1.webui生图以外,还需要进行很多后处理,比如序列化反序列化、图片后处理、转换格式、传递图片等。2.webui是一个社区项目,兼容的功能非常多、而且杂,里面各种判断逻辑。这些操作拖慢了速度,端到端速度表现一般。加速比例,对于不同的GPU效果不一样。3090这张卡比较特殊,计算性能好,但是显存的读取速度很差。所以在batchsize小的时候,性能卡在显存读取速度上,加速比高不起来。如果想看到更高的加速比,可以试试加大batchsize,这样diffusion占用的时间变多,网络和反序列化消耗时间的占比变小。如果用A系列卡效果会好一些。A10的性能比3090差,和他的显存读取速度匹配,加速方法对算法的优化比较符合卡的特点。
FlashAttention-2与fastunet对于AIGC联合加速为了进一步优化aigc生图效率,使用webui更快速地进行加速,我们针对diffusion model特点,通过fastunet与FlashAttention-2结合的方式进行加速,并取得了相对于flash1已有加速效果的大于40%的提速。▐ 实验环境
NVIDIA A10, CUDA Version: 11.4, webui-1.5.1, eas推理平台▐ 加速效果
xformers(flash2)+fastunet
| 文生图(512*512) | 文生图(512*512)(batchsize=4) |
| unet耗时(s) | | 3 3 3 3 |
unet耗时(it/s) (step = 20) | 17.06it/s 18.22it/s 17.36it/s 16.43it/s | 6.26it/s 6.27it/s 6.25it/s 6.25it/s |
相对于xformers(flash1),xformers(flash2)+fastunet提速:
| unet过程提速 |
| 文生图加速(一次生成1图) | (17.26-11.23)/11.23=54% |
| 文生图加速(一次生成4图) | (6.26-4.33)/4.33=45% |
加速效果:flash attention2 + fastunet > flash attention2 > flash attention1
使用xformers(flash2)+fastunet加速方法,AIGC生成图像,结果符合预期,无精度损失。
| 文生图(512*512)_ouput1 | 文生图(512*512)_ouput2 |
| |
生图过程主要有两部分耗时:controlnet与unet
旧方法:xformers 0.0.20,使用flash attention1加速sd(unet+controlnet)
新方法:1.当前的fastunet只加速unet里的attention(换为flash attention2)。2.xformers0.0.21加速包括controlnet在内的所有attention(换为flash attention2)。3.fastunett还对其他算子也做了一些fuse操作,也起到了加速效果。
fastunet和xformers0.0.21加速的底层逻辑,都是使用flash attention2优化attention。fastunet和xformers0.0.21叠加使用,可以最大程度起到加速效果。新的加速方法主要针对attention计算进行优化,所以在unet及其attention部分会有更高比例的加速。
近年来,让 Transformers 能够处理更长的序列长度一直备受关注。这一发展有助于提升语言建模和高分辨率图像理解的能力,并为音频和视频生成等新的应用场景带来了机遇。FlashAttention方法使得使用更长的序列计算注意力成为可能,并通过线性级别的增长来节省内存并加速计算。这一方法为处理长序列的Transformer模型提供了一种有效的解决方案。最新提出的FlashAttention-2,也进一步实现了attention计算速度的大幅度提升。
当我们一直在关注GPU显存大小以及计算能力的时候,FlashAttention关注了GPU显存以外的SRAM,从而优化attention计算。也为我们解决问题提供了思考,即在主流关注的技术点以外,还有一些被忽视的但依旧可以解决问题的思路。面对实际效果与理论效果的差距,FlashAttention-2则进一步找到gap原因,通过关注矩阵运算、序列并行、工作分区等问题,优化计算效果。这也提醒我们,对于性能问题的解决,从软硬件结合的角度出发,才能更充分的解决问题。
在AIGC领域的生图任务中,使用diffusion model进行相关计算,需要大量时间完成生图过程。所以,通过FlashAttention-2等多种加速方法进一步提升AIGC的生图效率,具有深刻意义。我们团队致力于家装行业AIGC进行相关研发,以提高家装AI模型的效果。我们希望与对此方向感兴趣的同学一起探讨和交流。

团队介绍
我们是淘天集团-场景智能技术团队,一支专注于通过AI和3D技术驱动商业创新的技术团队, 依托大淘宝丰富的业务形态和海量的用户、数据, 致力于为消费者提供创新的场景化导购体验, 为商家提供高效的场景化内容创作工具, 为淘宝打造围绕家的场景的第一消费入口。我们不断探索并实践新的技术, 通过持续的技术创新和突破,创新用户导购体验, 提升商家内容生产力, 让用户享受更好的消费体验, 让商家更高效、低成本地经营。











