数据集在计算机科学和数据科学中发挥着至关重要的作用。它们用于训练和评估机器学习模型,研究和开发新算法,改进数据质量,解决实际问题,推动科学研究,支持数据可视化,以及决策制定。数据集提供了丰富的信息,用于理解和应用数据,从而支持各种应用领域,包括医疗、金融、交通、社交媒体等。正确选择和处理数据集是确保数据驱动应用成功的关键因素,对于创新和解决复杂问题至关重要。因此,数据集不仅是技术发展的基础,也是推动科学进步和社会决策制定的强大工具。
无论是图像识别,自然语言处理,医疗保健还是任何其他人工智能领域感兴趣,这些数据集都是非常重要的,所以本文将整理常用且有效的20个数据集。
MNIST:这是用于图像识别任务的经典数据集,包含从0到9的手写数字图像,可以说它是图像识别的Hello World

CIFAR-10:另一个流行的图像识别数据集CIFAR-10包含10种不同类别的对象,如飞机、汽车和动物。

ImageNet:最大的图像识别数据集之一,ImageNet包含超过22,000个类别的数百万标记图像。

COCO:这个数据集通常用于对象检测任务,包含超过30万张图像和超过200万个对象实例,标记在80个类别中。

cityscape:用于自动驾驶任务的数据集,cityscape包含来自各个城市的街道场景,并对汽车、行人和建筑物等对象进行了像素级注释。

Pascal VOC:另一个流行的对象检测数据集Pascal VOC包含来自现实世界场景的图像,这些图像带有对象边界框和对象类标签。
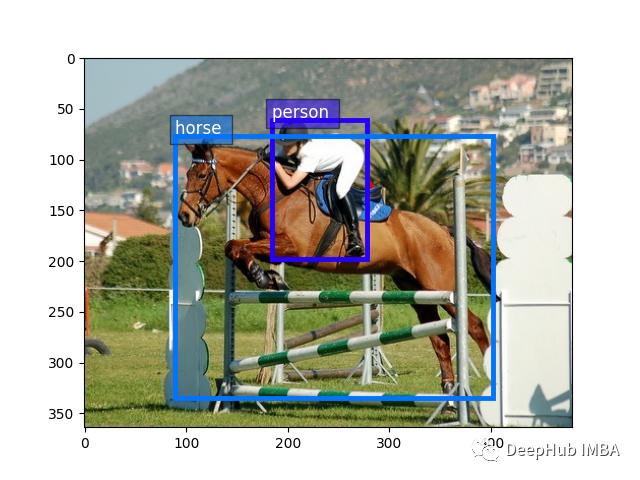
WikiText:一个大规模的语言建模数据集,包含来自维基百科文章的超过1亿个令牌。如果将Penn Treebank与WikiText-2进行比较,后者的规模和数量几乎是前者的两倍。相比之下,WikiText -103比其他版本大110倍。
Penn Treebank:一个广泛用于自然语言处理任务的数据集,Penn Treebank包含来自华尔街日报的解析文本。
以下是这两个数据集的比较:
SNLI:斯坦福自然语言推理数据集包含570,000个标记为蕴涵,矛盾或中立的句子对。它支持自然语言推理系统,也可以称为RTE(识别文本蕴涵)。
SQuAD:斯坦福问答数据集包含维基百科文章中提出的问题,以及相应的答案文本跨度。

MIMIC-III: MIMIC-III是一个大型电子健康记录数据集,包含来自40,000多名患者的各种临床记录和诊断数据。

Fashion-MNIST: MNIST数据集的一个变体,Fashion-MNIST包含服装项目的图像,而不是手写数字。Fashion-MNIST数据集包含Zalando的服装图像,其中包括60,000个训练样本和10,000个测试样本。

CelebA:包含年龄、性别和面部表情等属性的名人面部数据集。该数据集帮助各种应用程序验证面部识别作为其安全系统。本数据集的原始数据由香港的MMLAB发布。

Kinetics:一个人类动作识别的数据集,Kinetics包含超过50,000个视频剪辑,其中包括人们进行各种动作,如散步,跑步和跳舞。每个视频剪辑的持续时间为10秒,突出显示了600组人类动作。

Open Images:一个用于对象检测任务的大规模数据集,Open Images包含数百万张带有600多个对象类别注释的图像。

LJSpeech:一个用于文本到语音合成的数据集,LJSpeech包含131000个单个说话者朗读报纸上句子的短音频记录。演讲者从7本非虚构的书中摘录了部分内容。
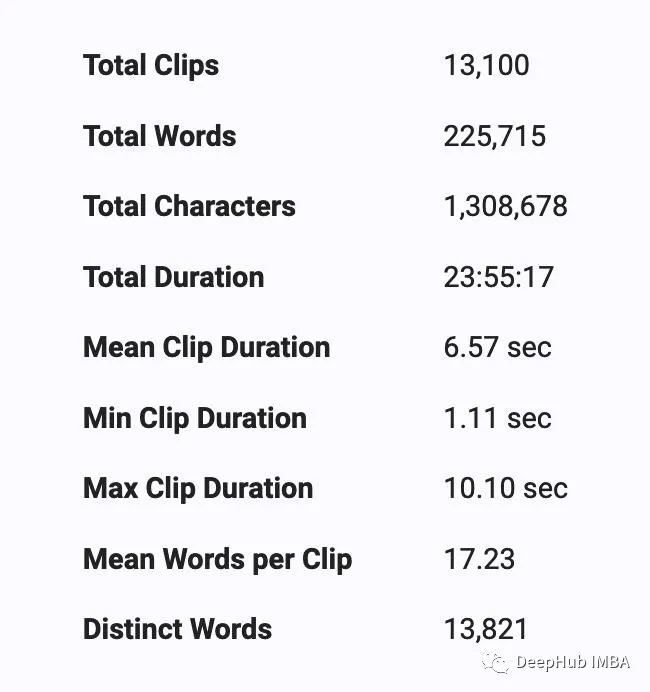
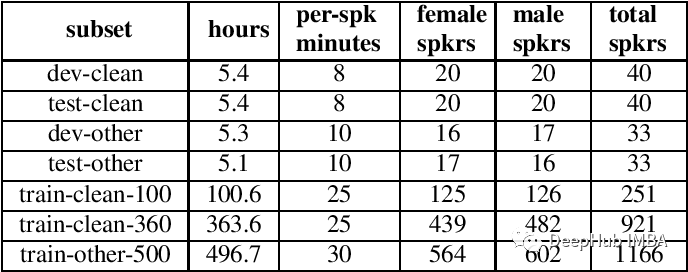
librispeech :一个用于语音识别任务的数据集,librispeech 包含了超过1000小时的录音,是LibriVox有声读物的一部分,带有相应的转录本。
AudioSet:一个音频事件识别的数据集,AudioSet包含了超过527类声音的录音。这些声音片段的持续时间为10秒。它是通过使用youtube元数据和基于研究的内容来组织的。

NSynth:一个用于乐器合成的数据集,NSynth包含各种乐器的录音,具有相应的音高和音色信息。它是由1006种乐器组合而成的一组曲子,共产生305979首优美的曲子。
Chess:用于国际象棋比赛预测的数据集,包含来自数千场比赛的数据,其中包含玩家评级和棋子移动序列等信息。

数据集在数据科学和人工智能领域中是不可或缺的工具,它们为模型的训练和评估、问题的解决以及科学研究提供了基础数据。选择适当的数据集并进行有效的数据处理和分析是确保数据驱动应用程序成功的重要一步。









