
两位美国会计学教授Baruch Lev和Feng Gu在其新著《会计的没落与复兴》中,挑衅性地认为会计没有跟上经济结构的世俗变化。随着实物生产资料重要性的下降,企业的价值越来越多地由无形资产驱动。在这种知识经济中,专有技术、客户、品牌和网络解释了投资者所关系的价值。他们的分析进一步评估了市场之间日益脱节的情况,即企业披露的信息,尤其是会计信息与投资者最为关心的企业价值开始背道而驰,相关性日益下降。
投资者们是否应该转向一种新的信息来源与分析方式?具体到当下技术热点上,机器学习成为了这一问题的关键。那么,机器学习能否帮助提供更好的高质量前瞻性信息?
事实上,会计界对于机器学习这一技术的兴趣一直在增长,将机器学习整合为一套报告工具,以预测、诊断和提高报告质量,各种新的研究表明,机器学习可以预测错误和违规行为,测量信息含量,分析财务报表或改进审计程序等。
来自华盛顿大学的Jeremy Bertomeu于2020年8月在会计学国际顶级期刊《Review of Accounting Studies》发表论文“Machine learning improves accounting: discussion, implementation and research opportunities”。在这篇论文中,作者回顾了机器学习在会计学领域应用的独特挑战。
以2019年Review of Accounting Studies学术年会上提出的"机器学习改善会计估计"(Ding, K., Lev, B., Peng, X., Sun, T., Vasarhelyi, M.A. (2019). Machine learning improves accounting estimates. Review of Accounting Studies.)为跳板,作者检验了为什么机器学习能提供超越管理者的预测效果。另外,本文的核心是在会计研究常用的面板数据设定下构建了适用机器学习的处理方法。最后,作者还提供了机器学习在会计领域具有应用潜力的方向。
相关阅读:
更新 | 从JAE、AR、JAR、RAS、CAR看中国大陆高校在会计学领域排名
Jeremy Bertome
圣路易斯华盛顿大学助理教授
研究领域:财务会计和监管
根据Google Scholar,Jeremy Bertome已经在《Journal of Financial Economies》、《Journal of Accounting and Economics》、《The Accounting Review》、《Journal of Accounting Research》、《Review of Accounting Studies》、《Contemporary Accounting Research》和《Management Science》等国际顶刊发表论文20余篇,谷歌引用量为1568次。
首先在这一章,作者的分析基于论文:Ding, K., Lev, B., Peng, X., Sun, T., Vasarhelyi, M.A. (2019). Machine learning improves accounting estimates. Review of Accounting Studies。该论文发现机器学习能够比管理者产生更好的预测效果,但明明机器学习并没有掌握会计专业知识。因此,这一章作者仔细地分析了有可能导致这一结果的各种假设,展示机器学习为什么能够赋能会计预测。
机器学习可以被认为是一个算法,在给定企业外部主体(例如,监管者、投资者等)可观测信息集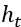 的情况下,输出一个关注变量
的情况下,输出一个关注变量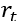 的估计量
的估计量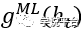 。这里,不妨假设机器学习算法的目标是在给定所有已知信息的情况下,高效地估计该数量的条件均值,即:
。这里,不妨假设机器学习算法的目标是在给定所有已知信息的情况下,高效地估计该数量的条件均值,即:
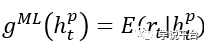
另一方面,以人力会计专家为主的管理层则采用不同的估计程序,既可以由现存的会计理论驱动,也可以被自身的各类需求所驱动,从而做出最大化其效用的估计:
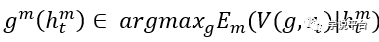
其中:
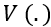 是管理者的效用函数;
是管理者的效用函数;
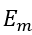 是管理者的主观期望;
是管理者的主观期望;
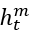 是管理者在做出估计时采用的信息集合。
是管理者在做出估计时采用的信息集合。
这里,可以通过对比机器学习的估计过程,以及管理层的估计过程得知一些暗含在设定里的有趣假设:
信息缺失:由于两种估计使用的信息集不同,管理者有可能有意识的忽略某些变量,从而导致估计效果不同。模型偏误:由于两种估计使用的函数不同,机器学习中使用数据驱动的条件均值函数,而管理层则使用基于会计理论与个人经验的主观期望函数,从而导致估计效果不同。
目标偏移:在机器学习模型中,目标常常是一个损失函数,即机器学习力求对现有数据最优拟合的模型参数组合。但在管理层估计中,主观效用函数的存在导致管理层可能并非以估计效果最大化作为目标,从而导致估计效果不同。
上述三种可能性,均潜在地导致了机器学习模型预测效果高于管理层预测。在后面的工作中,作者一一进行检验(具体检验过程限于篇幅可参读原文)。
经过检验,作者发现,管理层预测之所以不如机器学习模型,主要源于其模型预测与目标偏移这两个因素,而非信息缺失。即管理层虽然掌握了尽可能多的信息来源,但是人工会计专家使用的模型过于简单,或者并不能适应最新的数据特点,并且管理层有时会处于自身的需求考虑,如税盾、外部监管和自利情况,调整其预测的目标函数,最终导致了管理层预测能力下降。
相反地,机器学习模型则完全由数据驱动,拒绝了潜在的模型误设,并且由于机器学习模型的目标是最小化某一损失函数,所以也不存在目标偏移的情况,因此提供了更好的会计预测能力。
首先,作者介绍了几个关于机器学习的错误认识。
机器学习是关于预测的,而计量学是关于解释的。准确的预测的确是机器学习的主要应用领域,但计量学中常用的模型仍然是“预测”作为内核的。如计量经济学中的"解释"一词指识别能够在样本外预测结果的真实因果机制。对于尚不可观测的反事实实验,其研究关键也是“预测”反事实结果。
机器学习不需要具体函数形式,而统计模型需要提供函数形式。实际上,机器学习中使用许多模型作为估计的函数形式,例如线性回归是一种传统的机器学习算法。反过来,许多统计模型旨在确定因变量和自变量之间的平滑关系,而不需要分布或函数形式的参数知识。
机器学习不需要具体的数学公式表达,而统计学家则需要更为严谨的数据生成过程假设。统计学有着检验估计量理论性质的悠久的理论工作传统。然而,这主要是由于该领域的成熟度所导致的,这使得研究人员有时间为大多数估计程序开发一个完整的理论背景。但无论研究者是否明确指定数据生成过程,科学方法将假设客观数据生成过程的存在,这意味着标准估计量和机器学习估计量事实上是存在某些数学性质的(虽然对于机器学习来说,相关理论的确较为薄弱)。
机器学习必须平衡学习和过拟合,而统计模型不需要考虑过拟合。许多统计模型可能容易发生过拟合,并且有明确的参数,如果不加以检查,就会使数据过拟合。例如,任何研究者都熟悉公司固定效应如何在短面板中吸收感兴趣的经济变化,以及有时包括太多无关变量或交互项可能改变估计指的显著性。
当然,机器学习作为现代统计方法的代表之一,仍然与传统方法之间存在显著的差别,主要有:1.机器学习的模型形式的确更为复杂 2.机器学习的参数评价并非使用显著性,而是样本外预测效果 3.机器学习通常不存在闭式解,通过迭代、更新、传播等算法是机器学习的主要估计方式。
在这一部分中,作者介绍了在会计学领域应用机器学习方法时的基本操作原则与步骤。
应用机器学习方法的第一个步骤就是将样本分为三个子样本训练集、验证集与测试集,其中训练集用于对任意给定的超参数θ建立估计模型中的其他参数,而验证集用于选择最优的超参数组合θ*,最终,测试集则用于评估估计量的性能。但不幸的是,在会计研究中常用的面板数据中,创建具有独立误差项的子样本是不可能的。至少,面板中的观测很可能具有公司内或时间内的相关性。因此,作者提供了三种方法进行解决,(1)滚动窗口估计,即从样本起始期开始,滚动向前更新样本集,该想法类似传统计量中的时间固定效应;(2)K折交叉验证,这一方法广泛地在机器学习领域应用,其目标就是通过划分样本,使得模型在多个子样本间达到平均效果最优,而不是在某一行业或某一年形成过拟合;(3)则是如下图所示的划分方法,该方法适用于样本量较大的情况:
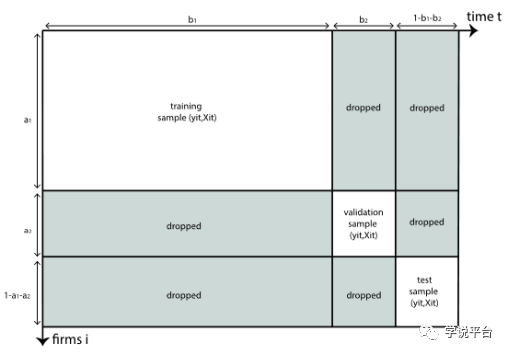
完成样本划分后,使用训练集与验证集完成模型超参数选择。具体地,通过设定一系列可能的超参数组合,模型在训练集训练,并且在验证集进行预测,以验证集预测效果作为标准,选择最优的超参数组合作为模型确定使用的超参数,即确定了机器模型的具体形式。
在机器学习领域中,有很多方法对模型效果进行了评估,比如在分类任务中,可以使用召回率、F1率、ROC等指标,在回归任务中,R2、分组绘图等方法都能提供很好的评估方法,但是作者提醒,在会计领域中,实际应用是最为核心的部分,会计信息使用者不可能对所有类型的错误都一视同仁。应计项目的低估可能更为重要,特别是对于处于困境或面临诉讼风险的公司而言。因此,如果不对合理的决策问题进行更多的实验,也不对信息含量进行更一般的度量,仅通过一些“数学指标”是无法"改善"会计估计的。
毫无争议,机器学习工具正在使实证研究发生革命性的变化,因此,作者将在最后的讨论部分致力于为未来的研究提供机会。
1. 拥抱实证研究中的训练、验证和测试思维。有时对于一个实证问题,显著的参数估计值很难区分是一个真正的结论,还是在某种操作下的“过拟合”产物,所以机器学习领域中的训练、验证和测试思维可以用于提升实证模型的稳健性。
2. 更好的控制变量组。检验一个理论需要对替代机制进行良好的控制。然而,标准实证方法限制了研究设计中可纳入的变量的数量,此外,线性假设排除了大量可能反映真实世界设置的交互作用。而机器学习可以让研究人员使用更稳健的过程来包括大量的控制变量其相互作用。
3.丰富了会计学中的经典范式:盈余管理和稳健性。许多盈余管理模型在控制了假定驱动应计利润的经济因素后,依赖于从应计利润中提取残差作为指标,因此导致了盈余管理模型的激增。并且由于简单的模型不能很好地拟合应计利润,因此残差当中的信息可能远远多于“盈余管理”。但机器学习从大量的协变量中学习,并提供更准确的估计残差。
4.探索被理论忽略的关系。尽管许多研究人员可能不愿意承认这一点,但目前的测试方法,即研究人员选择一个研究设计来"测试"一个理论是有问题的,因为研究人员会千方百计地验证一个理论(或者,至少,沿着某一理论的预期来组织一组结果)。这个问题污染了任何理论先于实证模型出现的视角。而机器学习练习不需要在没有理论参考的情况下组织数据,因此不受验证理论的目标的污染。通过报告特征重要性及其相互作用,它可以提供解释力,即理论对可能解释样本的特征的解释。简而言之,机器学习提供了一种证据先于理论的方法。
5.在实验室、田野和自然实验中进行可信数据挖掘。注册报告的形式在会计学中已经开始增多(在实验开始前就投稿或发表),这种研究方法需要研究者具有更为全面的数据挖掘能力。机器学习通过学习所有可能的相互作用,并使用一个测试集来评估这些相互作用的真实存在,它不仅足够广泛地发现所有的模式,而且还可以提供工具来测试这些模式的稳健性。
6. 更好的财务比率。财务比率的种类与数量在财务报表分析中激增,导致实践者不得不淹没在一组大规模高维度的相关变量中。哪个指标更能概括一个公司的状态?机器学习的进步可以帮助选择信息和设计更好的比率。事实上,这项研究议程进一步表明,我们能以系统的方式重新设计会计数字中提供的信息,向投资者提供更为相关以及更有价值的信息。
原文链接:https://doi.org/10.1007/s11142-020-09554-9









