
在ChatGPT发布一年之后,生成式AI已经成为一个具有确定性的技术浪潮,而伊隆·马斯克旗下的xAI公司计划在本周将它11月初发布的大模型Grok接入X平台(推特),对X Premium+订阅者们开放。
xAI在今年7月成立,之后迅速训练出Grok-0这个基础模型,然后又经过调优进化成Grok-1。这个模型虽然参数只有大约330亿,但是能力已经超过llama2 70B和GPT-3.5,尤其在数学和编码方面表现突出。研究团队也在大模型的推理能力和可靠性方面开展研究。
马斯克组建了一个豪华的核心技术团队,团队成员们来自DeepMind、OpenAI、谷歌研究院、微软研究院、特斯拉和多伦多大学,主导过多个AI基础算法研究和知名AI项目,华人比例奇高,其中还有两位研究人员的论文引用数超过20万。
Grok将通过独家访问X(原推特)及其实时的用户生成的帖子和信息来实现差异化,它能访问在X上发布的最新数据,并在用户询问实时问题时提供最新信息。

如果您对人工智能的新浪潮有兴趣,有见解,有创业意愿,欢迎扫码添加“阿尔法小助理”,备注您的“姓名+职位”,与我们深度连接。

打造“追求真理的”的AI,马斯克组建了豪华核心团队
作为xAI的创始人,马斯克对AI有深刻的积累和认知。一方面,早在2013年,他就开启了特斯拉在自动驾驶方面的探索,目前特斯拉的自动驾驶硬件迭代到第四代,FSD算法迭代到V12版本,并将在近期更新。
另一方面,马斯克是OpenAI的联合创始人之一,当OpenAI还是非盈利研究组织时,他为OpenAI注入了5000万-1亿美元资金,支持它的早期发展。而OpenAI的联合创始人之一Andrej Karpathy在2017年6月-2022年7月担任特斯拉的AI总监,主导着特斯拉的自动驾驶项目。
2018年,马斯克离开了OpenAI,根据OpenAI的博客文章和马斯克后来的推文,理由是防止随着特斯拉更加专注于人工智能而与OpenAI产生利益冲突;根据Semafor报道,马斯克曾提议他接管OpenAI的领导,并在提议被拒绝后离开;而《金融时报》报道称,马斯克的离开也是由于与其他董事会成员和员工在OpenAI的人工智能安全方法上的冲突。
在离开OpenAI多年,且ChatGPT引发了AI热潮后,马斯克于今年7月宣布成立xAI,这家公司的目标是构建能“理解宇宙真正本质”的人工智能。

马斯克在接受采访时表示:“从人工智能安全的角度来看,一个极度好奇的人工智能,一个试图理解宇宙的人工智能,将会支持人类。”
豪华的核心技术团队
马斯克搭建了一个豪华的核心技术团队,他们来自DeepMind、OpenAI、谷歌研究院、微软研究院、特斯拉和多伦多大学。
他们在过去主导过不少AI研究和技术的突破,例如Adam优化器,对抗性示例,Transformer-XL,Memorizing Transformer,自动形式化等。此外,还包括AlphaStar、AlphaCode、Inception、Minerva、GPT-3.5和GPT-4等工程和产品方面的重要成果。
这个团队除了来自大厂和研究院外,还有一个特点是大多数拥有扎实的数学、物理背景。

例如xAI联合创始人杨格(Greg Yang )在哈佛取得数学学士与计算机硕士学位,师从丘成桐。丘成桐带着杨格出席活动、认识各个方向的博士生、数学家,还推荐他申请数学界本科生能取得的最高荣誉:摩根奖。

杨格透露,xAI将深入研究人工智能的一个方面—“深度学习的数学”,并“为大型神经网络发展‘万物理论’”,以将人工智能“提升到下一个层次”。
除了作为联合创始人的杨格外,在核心团队中还有张国栋 (Guodong Zhang),戴自航 (Zihang Dai),吴宇怀(Yuhuai Tony Wu),以及之后加入的Jimmy Ba、xiao sun、Ting Chen等华人成员,他们都在底层技术上有建树。
戴自航(Zihang Dai)是CMU和Google Brain于2019年发布预训练语言模型XLNet论文的共同一作,这个模型在20项任务上超越了当时的SOTA模型BERT。

戴自航2009年入读清华经管学院的信息管理与信息系统专业,此后前往 CMU开启六年的计算机硕博生涯,师从Yiming Yang。在博士期间深度参与图灵奖得主Yoshua Bengio创立的Mila实验室,Google Brain团队,并在博士毕业后正式加入Google Brain,担任研究科学家,主要方向为自然语言处理、模型预训练。
张国栋( Guodong Zhang)本科就读于浙江大学,他在辅修的竺可桢学院工程教育高级班中连续三年排名专业第一;此后,他前往多伦多大学攻读机器学习博士学位。

读博期间,他在Geoffrey Hinton的指导下,作为谷歌大脑团队的实习生从事大规模优化与快速权重线性注意力研究(Large-scale optimization and fast-weights linear attention),而他也在多智能体优化与应用、深度学习、贝叶斯深度学习等领域发表顶会论文。
博士毕业后,张国栋全职加入DeepMind,成为Gemini计划(直接对标GPT-4)的核心成员,负责训练与微调大型语言模型。
吴宇怀 Yuhuai (Tony) Wu的高中和大学时光均在北美度过,他本科在纽布伦斯威克大学读数学,并在多伦多大学获得机器学习学位,师从Roger Grosse和Jimmy Ba(也是xAI核心团队成员)。

在求学期间,吴宇怀在Mila,OpenAI,DeepMind和Google做过研究员。而在他的一项研究中,他和其他研究人员训练了一个增强大语言模型Minerva,这个模型数学能力很强,在波兰的2022年国家数学考试中,答对了65%的问题。这与xAI深入研究“深度学习的数学”的目标非常匹配。
Jimmy Ba曾担任多伦多大学的助理教授(AP),他的本硕博也都在多伦多大学完成,博士时的导师是Geoffrey Hinton。

他还是加拿大先进研究院人工智能主席,长期目标是如何构建具有类人效率和适应性的通用问题解决机器。Jimmy Ba在谷歌学术的引用数达到200844,而光是与Adam优化器有关的论文就超过16万,2015年与注意力相关的论文引用也超过1.1万。他事实上也是现在大模型技术的理论奠基人之一。
xiao sun在北京大学获得学士学位,在耶鲁大学获得EE的博士学位,此后在IBM Watson和Meta担任研究科学家。他的技术背景不在于AI模型,而在于AI相关的硬件和半导体,尤其是AI的软硬件协同。他曾获得MIT TR35(35岁以下创新35人)奖项。
Ting Chen在北京邮电大学获得学士学位,在美国东北大学和UCLA分别获得一个博士学位。之后他在谷歌Brain担任研究科学家,他的谷歌学术总引用数达到22363。他引用数最高的论文提出SimCLR,一个简单的视觉表示对比学习框架。这篇论文是与Geoffrey Hinton合作的,引用数达到了14579。
除了Jimmy Ba外,创始团队中还有另一位谷歌学术论文应用数超过20万的资深研究者,他是Christian Szegedy。Szegedy是吴宇怀在谷歌时的团队负责人,在谷歌工作了13年,有两篇论文引用数超过5万,另有多篇超过1万,文章的方向都指向AI的本质性算法研究。Szegedy是波恩大学应用数学博士。
Igor Babuschkin和Toby Pohlen共同参与了DeepMind著名的AI项目AlphaStar,AlphaStar从50万局「星际争霸 2」游戏中学习,随后自己玩了1.2亿局来精进技术。最终,它达到了最高的宗师段位,水平超越了99.8%玩家。

Grok-1模型能力仅次于GPT-4,在推理和数学能力上优化
xAI在11月初发布了他们的第一个基础大语言模型Grok-1(约330亿参数),这个模型是在它们的原型大模型Grok-0的基础上经过微调和RLHF完成。他的训练数据截至2023年第三季度,输出上下文长度为8k。
据称,Grok-0只使用了一半的训练资源,就达到了接近llama 2 70B的能力,之后又在推理和编码能力进行了针对性的优化。
在xAI官方公布的测试中,我们可以评估Grok-1的能力。在这个评测中,主要包括:
1.GSM8k:中学数学文字问题,使用思维链提示。
2.MMLU:多学科选择题,考验综合理解能力。
3.HumanEval:Python代码完成任务,考验编码能力。
4.MATH:中学和高中数学问题,用LaTeX编写,考验更高阶的数学能力。
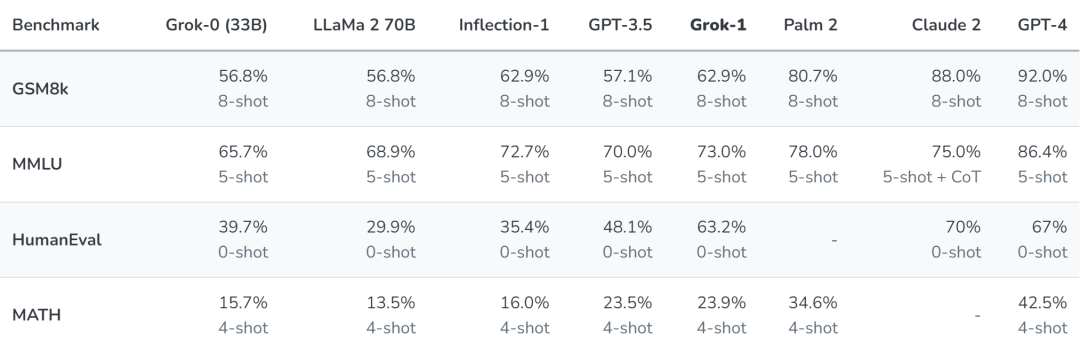
从图表中可以看出,Grok-1在几乎所有的测试中都领先llama 2 70B和GPT-3.5,在HumanEval和Math这两个测试中更是大幅领先llama 2 70B。但是它与Claude2和GPT-4仍然存在可见的差距。
不过鉴于Grok-1的模型规模应该只有33B,而且训练资源上只花费了llama 2 70B的一半,我们可以说它在效率方面有突出表现。未来若推出参数规模更大的版本,能力还有提升的空间。
由于以上的测试都比较主流,为了摒除刻意优化的因素,xAI测试了Grok与主要竞争对手在2023年匈牙利国家高中数学期末考试上的实际表现,这更贴近真实场景,为表公平,xAI没有为这次评估做特别的调整。

实验结果显示,Grok以C级(59%)通过了考试,而Claude-2也获得了相同的成绩(55%),GPT-4则以B级(68%)通过。
除了大模型,xAI还公布了PromptIDE,这是一个集成的开发环境,专为提示工程和可解释性研究而设计。PromptIDE的目的是为了让工程师和研究人员能够透明地访问Grok-1。这个IDE旨在赋予用户能力,帮助他们快速探索LLM的能力。
在11月初刚发布大模型时,Grok-1只对有限的用户开放,在本周xAI计划将Grok的能力向X Premium+订阅者们开放,xAI也为Grok提供了搜索工具和实时信息的访问权限,这一点相较于其他模型具有差异化优势。
它还提供专用的“趣味”模式、多任务处理、可分享的聊天和对话反馈。趣味模式将是所有功能中最有趣的,因为它赋予Grok独特的个性,使其能够以带有讽刺和幽默的方式进行更吸引人的对话。

大模型的竞争格局会变么?能力将往何处发展?
在ChatGPT发布正好一年的这一天,看起来OpenAI的模型能力和生态产品建设在各个大模型厂商中仍旧是明显领先的。能够与它竞争的公司Anthropic,Inflection,包括xAI都还处于追赶态势。谷歌,亚马逊等大厂也仍然落后。
基础大模型厂商之间的竞争,是全方位的竞争,而且鉴于AI模型预训练需要的高成本,当未来模型版本迭代时,又需要持续投入巨大的算力和资金成本。除此之外,找到能够充分释放模型能力价值的场景也非常重要,不然无法形成反馈的循环。
目前来看,xAI不缺人才,也不缺算力和资金,此外因为X(推特)的存在,它也不愁在前期找不到应用场景。尽管Grok-1现在的绝对能力与GPT-4仍然有差距,但是当后续它有更大规模参数的版本出现后,将会大大缩小与OpenAI的距离。
大模型的竞争是大厂与超级独角兽的竞争,但是正因为有这些公司在竞争和迭代,做应用的公司和终端的用户才会有越来越强,越来越便宜的AI能力使用,最终所有行业都会被AI翻新一遍。
在大模型进入公众视野一年后,对于大模型的局限性我们有了更清楚的认知,那就是推理能力和可靠性的不足。而在发展方向上,肯定是多模态。
xAI为了应对这些问题,也做了定向研究,对于推理能力不足,他们研究可扩展的工具辅助监督学习,让AI和人类协同对AI模型进行调优。
对于AI的可靠性不足,他们研究形式验证,对抗性鲁棒性等技术,增强AI的可靠性。此外,尽管目前Grok因为参数量的原因在多模态能力上不如GPT-4等模型,但是xAI也在积极研究这个方向,未来会有具备视觉和音频能力的模型。









