使用机器学习成功构建了一个分类管道,根据 Sentinel-2 卫星图像的时间序列生成 10 m 分辨率的农田掩模。用它创建了 2020 年多个地区地区的二值地图。通过采用空间交叉验证方法来选择模型,解决了可靠地面实况数据有限的挑战(发展中国家偏远地区经常出现这种情况)以及空间自相关的挑战。空间交叉验证证明是提高模型泛化能力的有效技术。评估了支持向量机(SVM)和随机森林(RF)分类器,并选择随机森林作为最终模型,因为其具有与 SVM 相当的良好精度,但推理时间要短得多。还对特征工程进行了消融研究,并分析了特征重要性,确认了上下文特征在解释作物分类模型性能方面的相关性,特别是在苹果收获季节的 NIR 波段(主要使用三个测试集验证了该模型,研究区域的每个地区各一个。总体而言,提出的 RF 方法在准确率、召回率、精确度和 F1 分数的三个方面的加权平均方面取得了超过 87% 的性能。最后,提出了最终的农田地图,将预测农田像素的海拔可视化,以便通过检查其通常的生长海拔来定位特定作物物种时使用它我们的农田地图比现有农田地图(例如哥白尼土地覆盖图(100米)和GFSAD(30米)农田图)具有更高的空间分辨率(10米)。解决地图问题,研究表明本研究提供了视觉上更准确的农田地图,同时具有更高的空间精度。本地图可通过农业用谷歌地球引擎公开访问组织、政府、农民生产者团体和供应链利益相关者。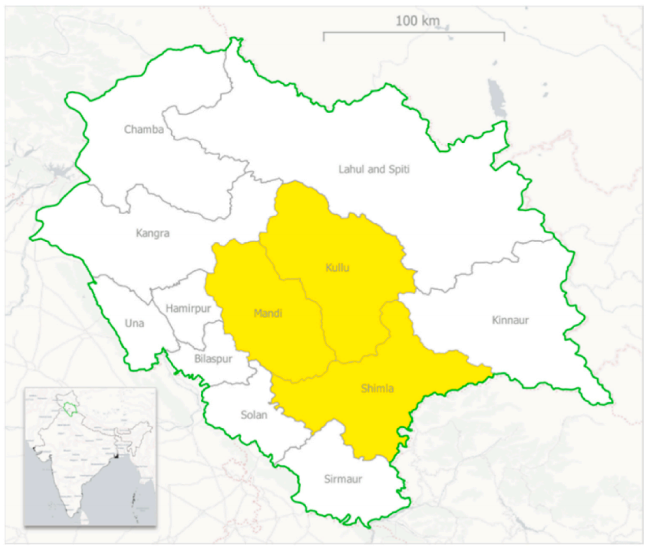
在印度喜马偕尔邦(绿色)的研究区域的位置:库鲁、曼迪和希姆拉区(黄色)

2020年以上的43SFR瓷砖上的遥感样本的真彩色图像。每张图像的比例为100×100平方公里。可
以看到地球表面也在相应地演变

数据预处理步骤的影响的例子,包括大气校正、云掩模(均为单个时间步长)和常规时间采样
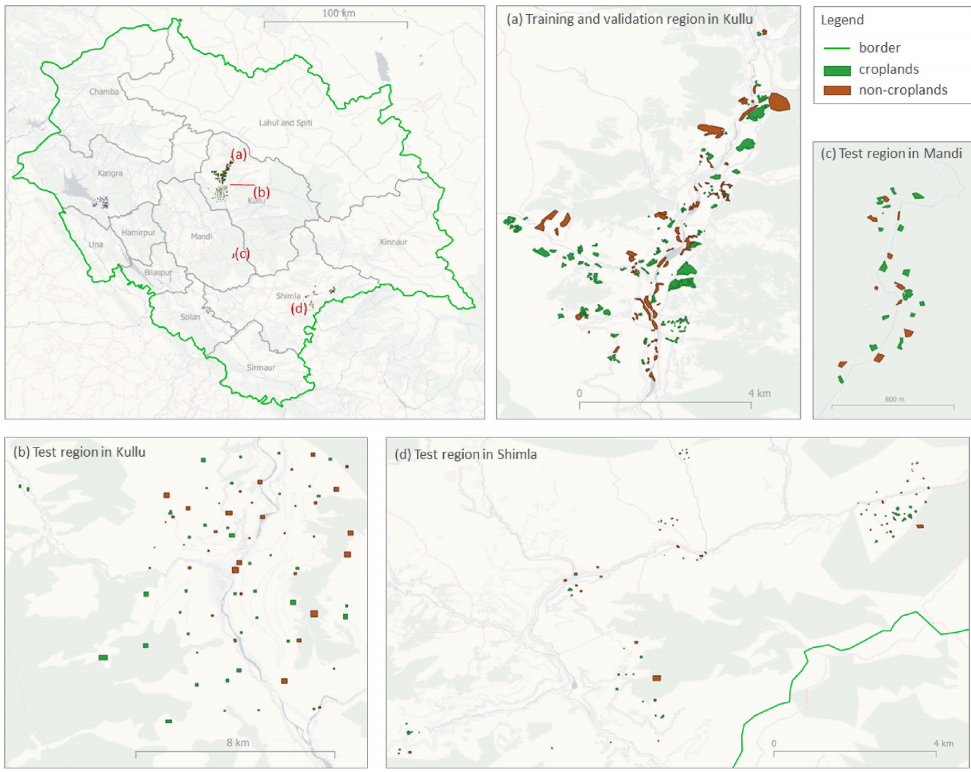
在研究区域的标签分布。在Kullu有一个大型的训练和验证区域(a),在Kullu、Mandi和Shimla有三个小型的测试区域(b,c,d)
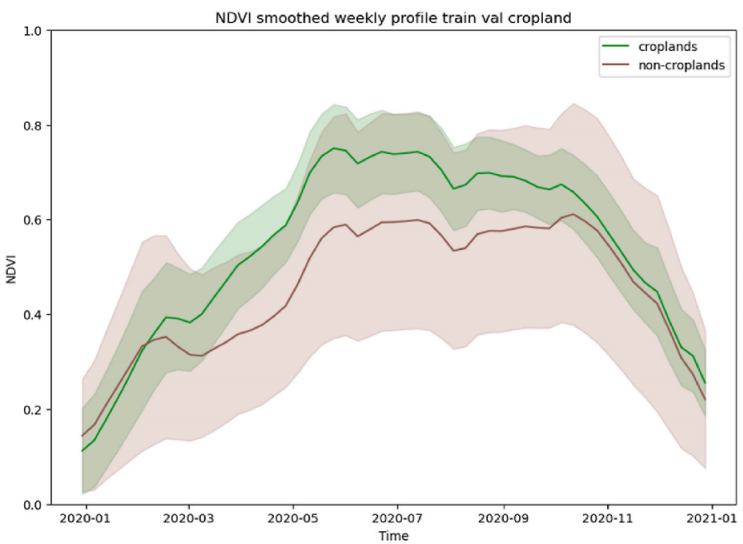
在训练和验证区域上的农田和非农田多边形的平滑平均NDVI周剖面(时间序列上的缺失数据之前已经用线性插值填充)。阴影区域代表一个标准差
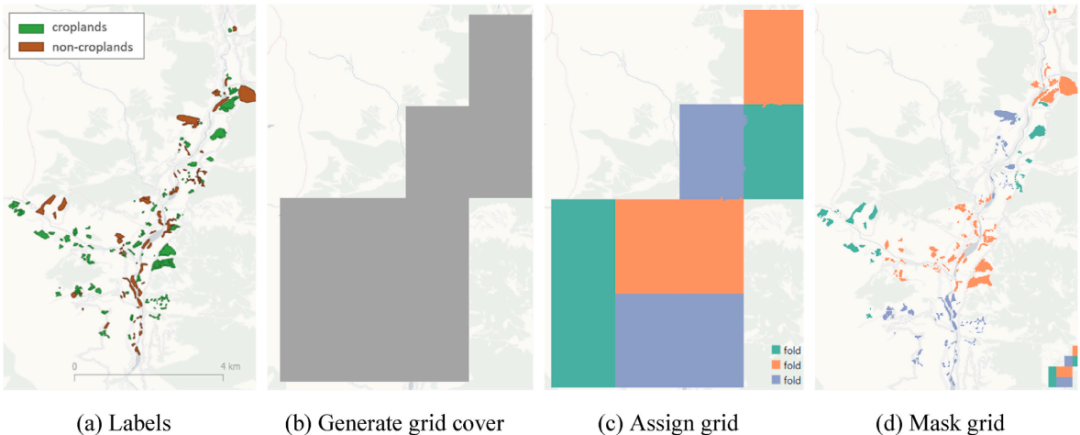
执行空间交叉验证的步骤
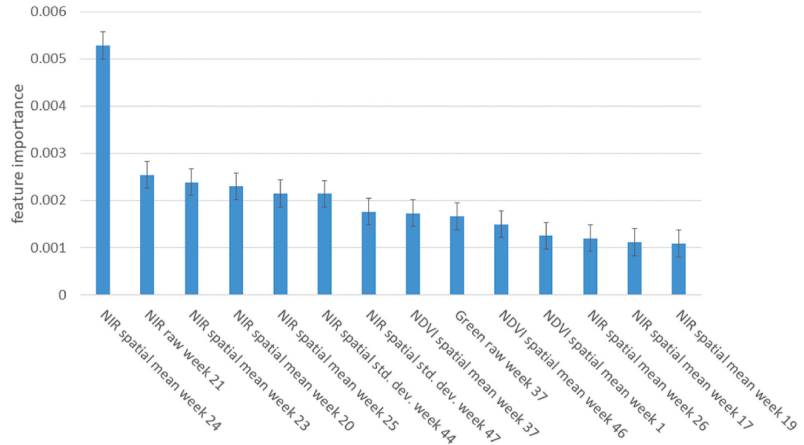
最终随机森林模型在三个测试集上的排列特征的重要性。误差条代表一个标准差

使用我们的RF模型、哥白尼土地覆盖图(布赫霍恩,2020)和GFSAD农田图(Phalkee,2017)对我们测试集中的三个示例区域进行定性比较。其中包括谷歌基础图图像(2016年12月30日),以供参考。我们还包括了在这些位置上标记的地面真实多边形(注意,不一定是全面的)。白色像素表示农田预测,黑色像素表示非农田预测(除了地面真相,其中黑色表示未标记)
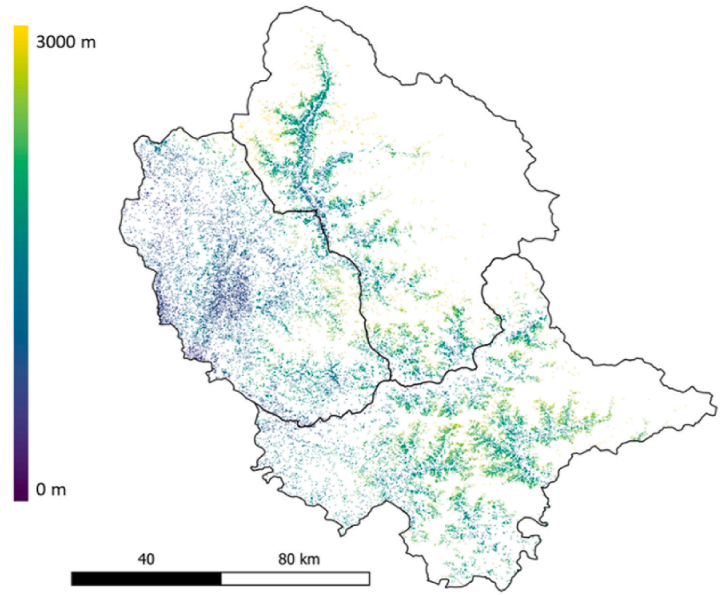
2020年,印度喜马偕尔邦的库尔卢、曼迪和希姆拉地区的耕地预测图。该地图是根据海拔高度绘制的,以便于瞄准不同的作物,考虑到他们的生长海拔范围。关于更高分辨率版本的地图,请参考提供的谷歌地球引擎脚本










