来源 | 机器之心
近日,arxiv 上发布了一篇论文,对 Transformer 的数学原理进行全新解读,内容很长,知识很多,十二分建议阅读原文。
2017 年,Vaswani 等人发表的 《Attention is all you need》成为神经网络架构发展的一个重要里程碑。这篇论文的核心贡献是自注意机制,这是 Transformers 区别于传统架构的创新之处,在其卓越的实用性能中发挥了重要作用。事实上,这一创新已成为计算机视觉和自然语言处理等领域人工智能进步的关键催化剂,同时在大语言模型的出现中也起到了关键作用。因此,了解 Transformers,尤其是自注意处理数据的机制,是一个至关重要但在很大程度上尚未充分研究的领域。
论文地址:https://arxiv.org/pdf/2312.10794.pdf深度神经网络(DNNs)有一个共同特征:输入数据按照顺序,被逐层处理,形成一个时间离散的动态系统(具体内容可以参考 MIT 出版的《深度学习》,国内也被称为「花书」)。这种观点已被成功地用于将残差网络建模到时间连续的动态系统上,后者被称为神经常微分方程(neural ODEs)。在神经常微分方程中,输入图像  在时间间隔 (0,T) 上会按照给定的时变速度场
在时间间隔 (0,T) 上会按照给定的时变速度场  进行演化。因此,DNN 可以看作是从一个
进行演化。因此,DNN 可以看作是从一个  到另一个
到另一个 的流映射(Flow Map)
的流映射(Flow Map) 。即使在经典 DNN 架构限制下的速度场
。即使在经典 DNN 架构限制下的速度场 中,流映射之间也具有很强的相似性。研究者们发现,Transformers 实际上是在
中,流映射之间也具有很强的相似性。研究者们发现,Transformers 实际上是在 上的流映射,即 d 维概率测度空间(the space of probability measures)间的映射。为了实现这种在度量空间间进行转换的流映射,Transformers 需要建立了一个平均场相互作用的粒子系统(mean-field interacting particle system.)。具体来说,每个粒子(在深度学习语境下可以理解为 token)都遵循向量场的流动,流动取决于所有粒子的经验测度(empirical measure)。反过来,方程决定了粒子经验测量的演变进程,这个过程可能会持续很长时间,需要进行持续关注。对此,研究者的主要观察结果是,粒子们往往最终会聚集到一起。这种现象在诸如单向推导(即预测序列中的下一个词)的学习任务中会尤为明显。输出度量对下一个 token 的概率分布进行编码,根据聚类结果就可以筛选出少量可能的结果。
本文的研究结果表明,极限分布实际上是一个点质量,不存在多样性或随机性,但这与实际观测结果不符。这一明显的悖论因粒子存在长时间的可变状态得到解决。从图 2 和图 4 中可以看出,Transformers 具有两种不同的时间尺度:在第一阶段,所有 token 迅速形成几个簇,而在第二阶段(较第一阶段速度慢得多),通过簇的成对合并过程,所有 token 最终坍缩为一个点。
上的流映射,即 d 维概率测度空间(the space of probability measures)间的映射。为了实现这种在度量空间间进行转换的流映射,Transformers 需要建立了一个平均场相互作用的粒子系统(mean-field interacting particle system.)。具体来说,每个粒子(在深度学习语境下可以理解为 token)都遵循向量场的流动,流动取决于所有粒子的经验测度(empirical measure)。反过来,方程决定了粒子经验测量的演变进程,这个过程可能会持续很长时间,需要进行持续关注。对此,研究者的主要观察结果是,粒子们往往最终会聚集到一起。这种现象在诸如单向推导(即预测序列中的下一个词)的学习任务中会尤为明显。输出度量对下一个 token 的概率分布进行编码,根据聚类结果就可以筛选出少量可能的结果。
本文的研究结果表明,极限分布实际上是一个点质量,不存在多样性或随机性,但这与实际观测结果不符。这一明显的悖论因粒子存在长时间的可变状态得到解决。从图 2 和图 4 中可以看出,Transformers 具有两种不同的时间尺度:在第一阶段,所有 token 迅速形成几个簇,而在第二阶段(较第一阶段速度慢得多),通过簇的成对合并过程,所有 token 最终坍缩为一个点。
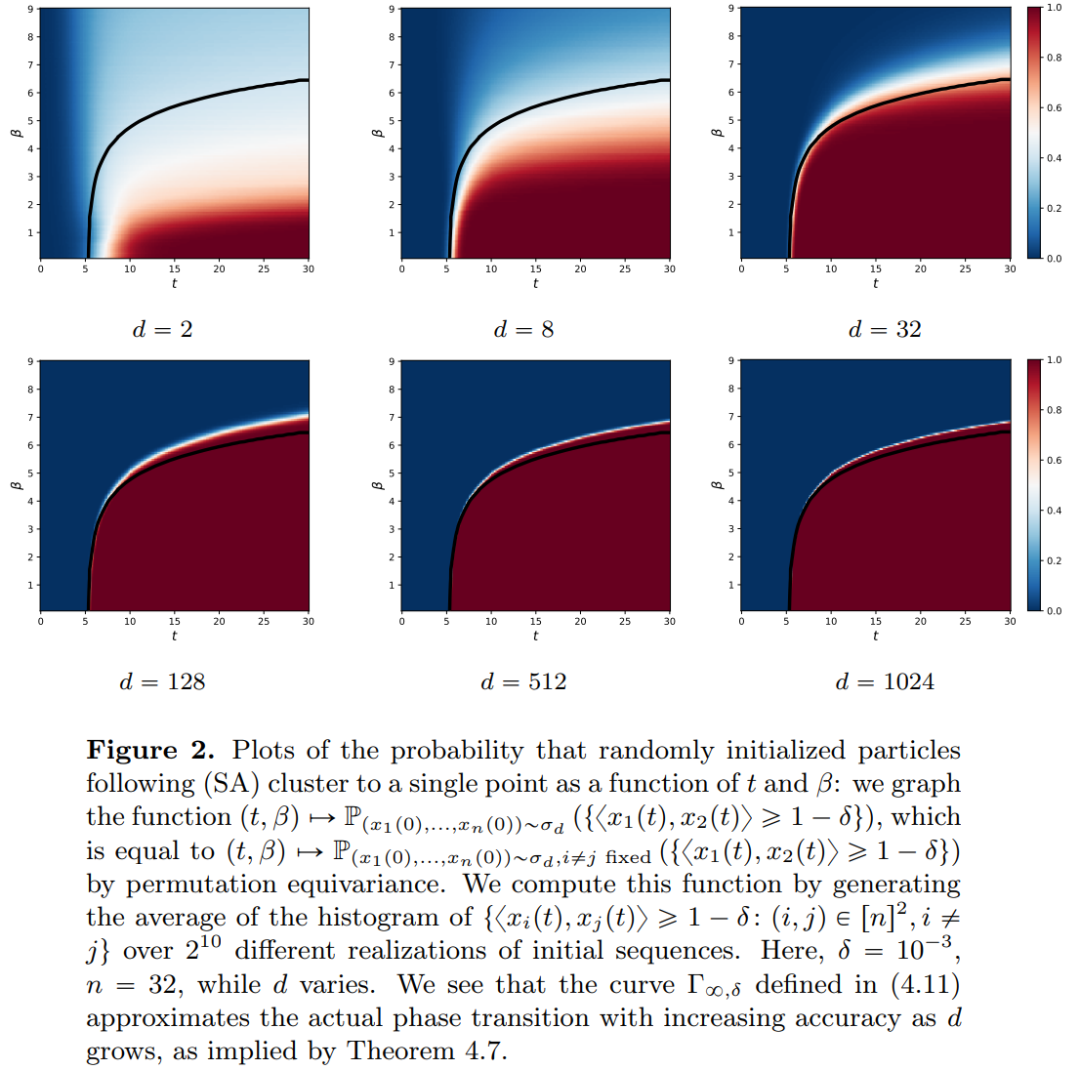
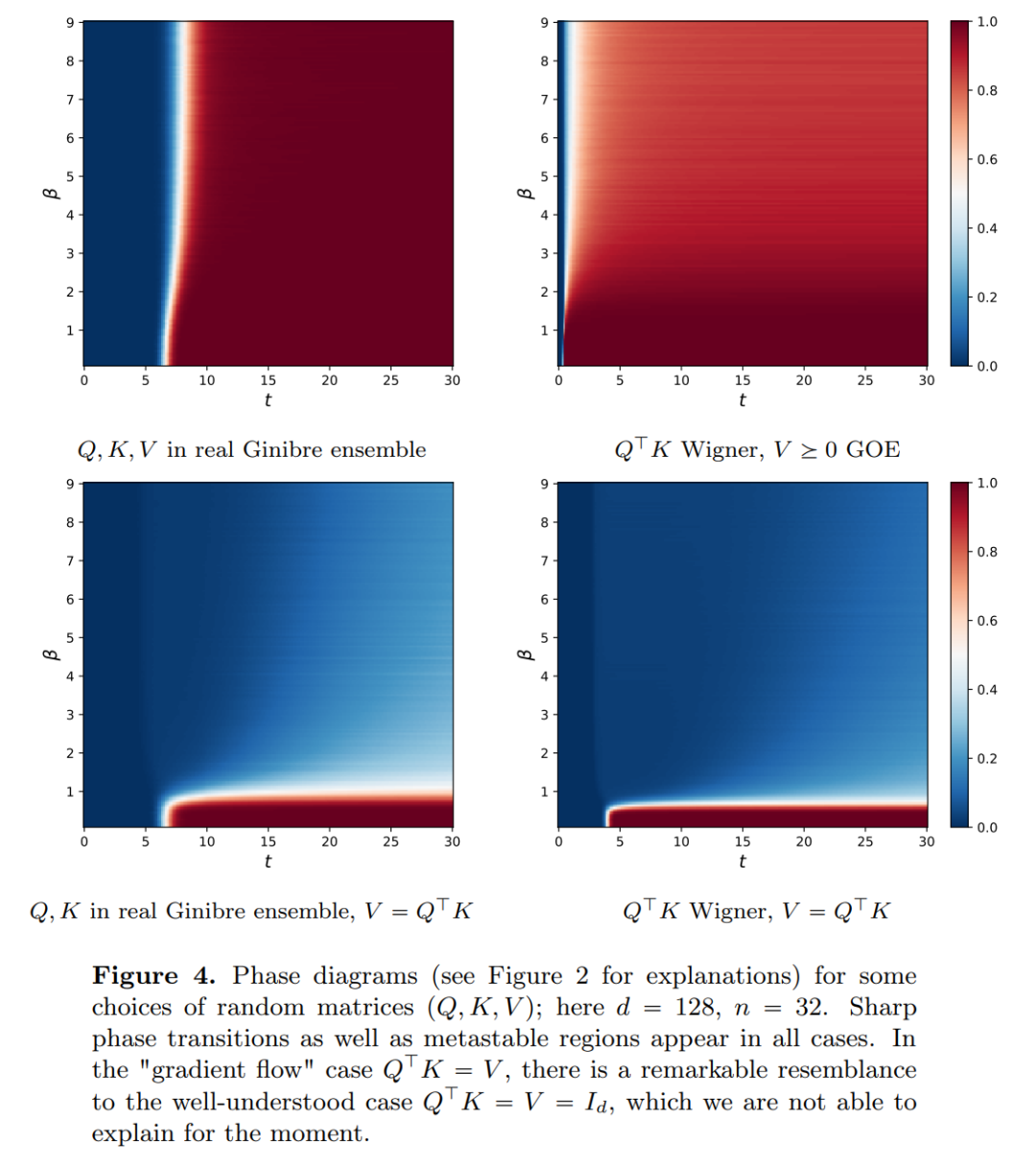
本文的目标有两个方面。一方面,本文旨在提供一个从数学角度研究 Transformers 通用且易于理解的框架。特别是,通过这些相互作用粒子系统的结构,研究者可以将其与数学中的既定主题建立具体联系,包括非线性传输方程、Wasserstein 梯度流、集体行为模型和球面上点的最优化配置等。另一方面,本文描述了几个有前景的研究方向,并特别关注长时间跨度下的聚类现象。研究者提出的主要结果指标都是新的,并且还在整篇论文中提出了他们认为有趣的开放性问题。
第 1 部分:建模。本文定义了 Transformer 架构的理想模型,该模型将层数视为连续时间变量。这种抽象方法并不新颖,与 ResNets 等经典架构所采用的方法类似。本文的模型只关注 Transformer 架构的两个关键组成部分:自注意力机制和层归一化。层归一化有效地将粒子限制在单位球  的空间内部,而自注意力机制则是通过经验度量实现粒子之间的非线性耦合。反过来,经验度量根据连续性偏微分方程进行演化。本文还为自注意引入了一个更简单好用的替代模型,一个能量函数的 Wasserstein 梯度流,而能量函数在球面上点的最优配置已经有成熟的研究方法。第二部分:聚类。在这一部分,研究者提出了在较长时间跨度下,token 聚类的新的数学结果。如定理 4.1 表明,在高维空间中,一组随机初始化在单位球上的 n 个粒子会在
的空间内部,而自注意力机制则是通过经验度量实现粒子之间的非线性耦合。反过来,经验度量根据连续性偏微分方程进行演化。本文还为自注意引入了一个更简单好用的替代模型,一个能量函数的 Wasserstein 梯度流,而能量函数在球面上点的最优配置已经有成熟的研究方法。第二部分:聚类。在这一部分,研究者提出了在较长时间跨度下,token 聚类的新的数学结果。如定理 4.1 表明,在高维空间中,一组随机初始化在单位球上的 n 个粒子会在 时聚成一个点。研究者对粒子集群收缩率的精确描述对这一结果进行了补充说明。具体来说,研究者绘制了所有粒子间距离的直方图,以及所有粒子快要完成聚类的时间点(见原文第 4 节)。研究者还在不假设维数 d 较大的情况下就得到了聚类结果(见原文第 5 节)。第 3 部分:未来展望。本文主要以开放式问题的形式提出问题,并通过数字观测加以证实,以此提出了未来研究的潜在路线。研究者首先关注维数 d = 2 的情况(见原文第 6 节),并引出与 Kuramoto 振荡器的联系。然后简要展示了如何通过对模型进行简单而自然的修改,解决球面最优化相关的难题(见原文第 7 节)。接下来的章节探讨了相互作用的粒子系统,这些粒子系统使得对 Transformer 架构中的参数进行调整成为可能,日后可能会进一步产生实际应用。
时聚成一个点。研究者对粒子集群收缩率的精确描述对这一结果进行了补充说明。具体来说,研究者绘制了所有粒子间距离的直方图,以及所有粒子快要完成聚类的时间点(见原文第 4 节)。研究者还在不假设维数 d 较大的情况下就得到了聚类结果(见原文第 5 节)。第 3 部分:未来展望。本文主要以开放式问题的形式提出问题,并通过数字观测加以证实,以此提出了未来研究的潜在路线。研究者首先关注维数 d = 2 的情况(见原文第 6 节),并引出与 Kuramoto 振荡器的联系。然后简要展示了如何通过对模型进行简单而自然的修改,解决球面最优化相关的难题(见原文第 7 节)。接下来的章节探讨了相互作用的粒子系统,这些粒子系统使得对 Transformer 架构中的参数进行调整成为可能,日后可能会进一步产生实际应用。欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)








