
大数据文摘授权转载自菜J学Python
作者:J哥
白岩松曾说:“高房价正在毁掉无数年轻人的爱情,毁灭了年轻人的想象力。”尤其是北上广深这类一线城市,对于一般的工薪阶层,买房更是难上加难。前不久,DT财经写了一篇文章《我只有300万预算,能在上海买到什么样的房子?》,引起了网友广泛热议。有人不禁要问,那在深圳买房又得要多少预算呢?
于是,为了深入了解深圳二手房交易市场,我用Pyhton采集了深圳在售20778套二手房数据并分析,试图从数据层面了解深圳二手房市场现状。
深圳二手房历年走势
首先,我们看一下深圳近年来二手房房价整体走势图。由图可知,2011年深圳二手房价仅为18495元/㎡,至2019年增长至62205元/㎡,增加了2.36倍。然而深圳平均工资增加不到2倍。可见,一般的工薪阶层购房压力增加也是情理之中。
深圳二手房在售房源分布
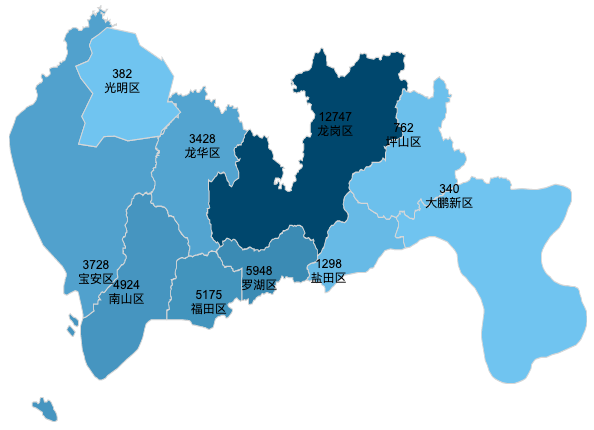
深圳二手房源主要分布在龙岗区,共计12747万套。坪山区和大鹏新区二手房源相对较少,分别为762套和340套。
深圳在售二手房房价分布
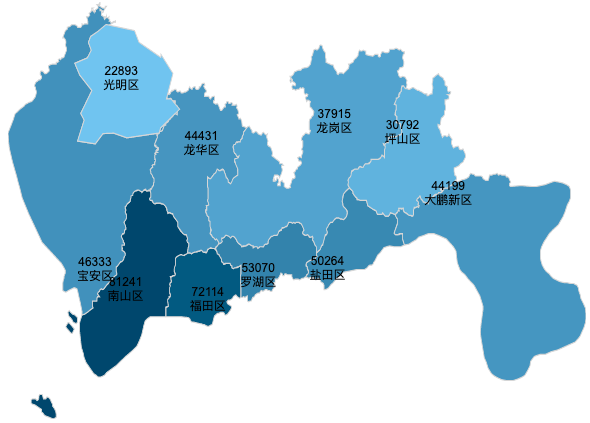
从深圳在售的二手房均价来看,南山区均价最高,高达81241元/㎡,其次是福田区和罗湖区,二手房均价分别为72114元/㎡和53070元/㎡。光明区房价最低,为22893元/㎡。
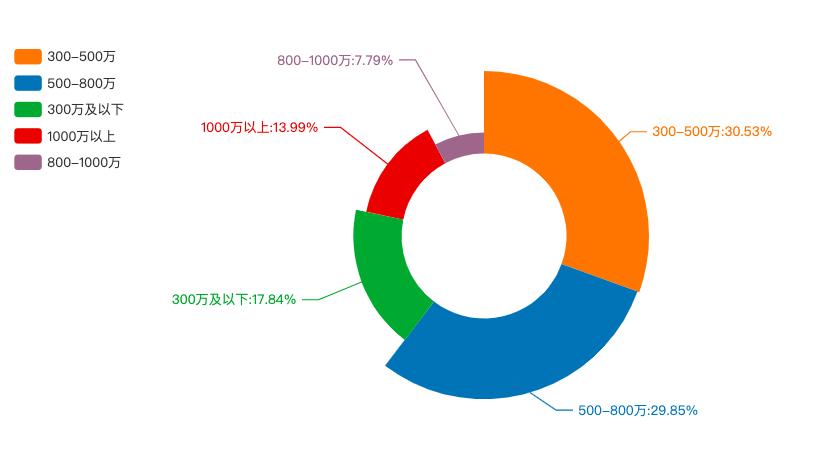
在深圳买一套二手房到底要花多少钱?我们分析了二手房的价位,从图中可以看到总价在300-500万内的最多,占比达到30.53%。500-800万的占比29.85%。300万以下的占比17.84%。
深圳在售二手房房龄分布
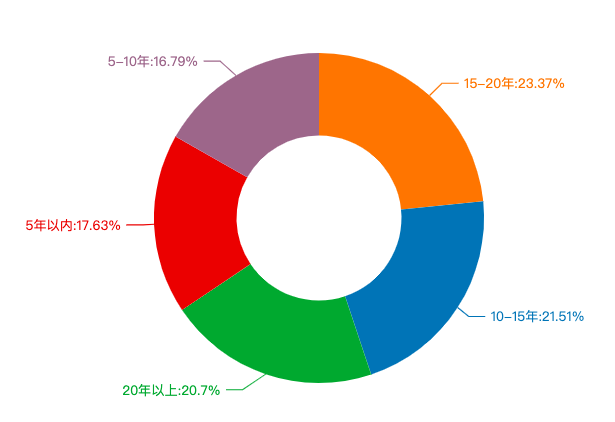
这些二手房的房龄都有多久了呢?由图可知,房龄在15-20年的最多,占比23.37%,其次是房龄在10-15年,占比21.51%。5年以内的仅占比17.63%。
不同居室二手房数量及均价
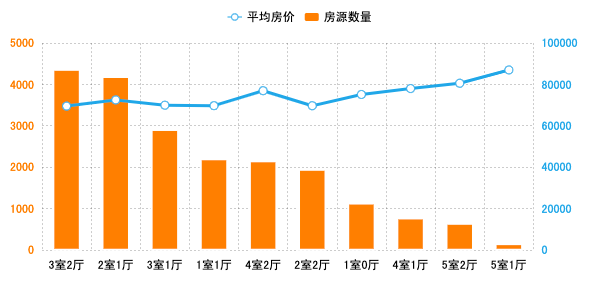
深圳二手房中,3室2厅、2室1厅和3室1厅的二手房源数量最多,5室以上的房源较少。影响二手房房价的因素很多,居室越多房价不一定就更高,由图可知,1室0厅的均价也达到了75121元/㎡。
不同朝向二手房源数量
深圳在售二手房中,朝南的房源占比最大,达31.72%,朝东南和西南次之,分别为26.10%和8.94%。
深圳在售二手房房源TOP10楼盘
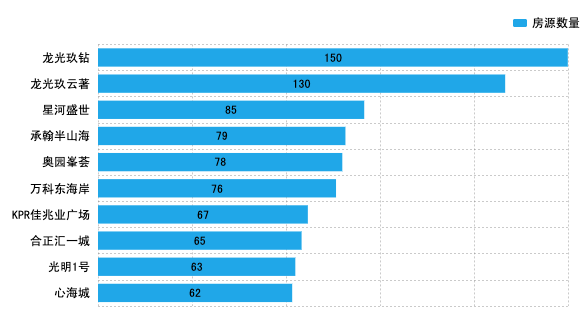
由图可知,龙光玖钻在售二手房数量最多,达到150个,其次是龙光玖云著,为130个房源。
楼层数、建筑面积与房价的关系
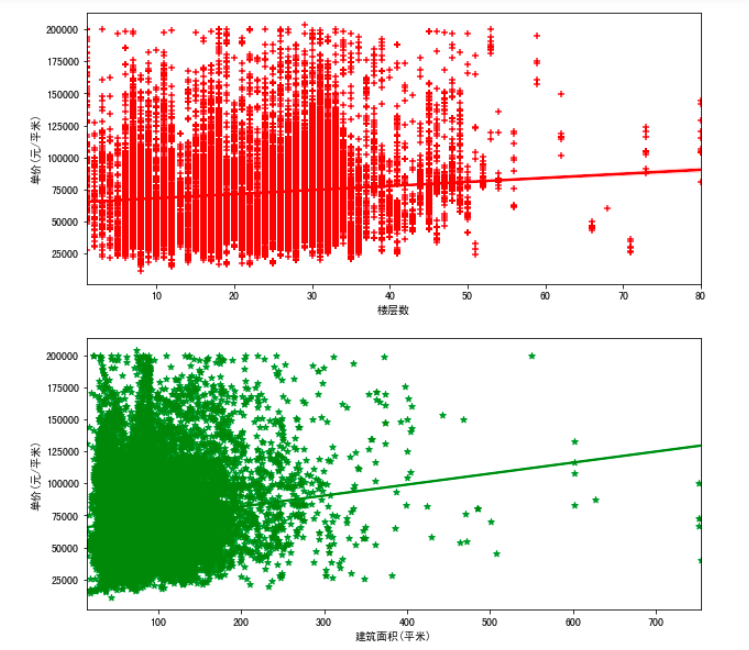
通过绘制楼层与房价、建筑面积与房价回归图可知,深圳在售二手房楼层类型分布较为分散,且楼层与房价的相关性不大,建筑面积集中分布在200㎡内,且建筑面积与房价具有较强的正相关。
本次数据来源于贝壳找房,限于篇幅,以下仅提供核心代码:
def main(): district_list = ['luohuqu', 'futianqu','nanshanqu', 'yantianqu','baoanqu', 'longgangqu','longhuaqu', 'guangmingqu','pingshanqu', 'dapengxinqu'] for district in district_list: for page in range(1,101): url = 'https://sz.ke.com/ershoufang/{0}/pg{1}/'.format(district, page)
response = requests.request("GET", url, headers = headers) print(response.status_code) if response.status_code == 200: re = response.content.decode('utf-8') print("正在提取" + district +'第' + str(page) + "页") time.sleep(random.uniform(1, 2)) print("-" * 80) parse = etree.HTML(re) num = ''.join(parse.xpath('//*[@id="beike"]/div[1]/div[4]/div[1]/div[2]/div[1]/h2/span/text()')) print(num) parse_page(parse) if int(num) == 0: break
if __name__ == '__main__': ua = UserAgent(verify_ssl=False) headers = {"User-Agent": ua.random} time.sleep(random.uniform(1, 2)) main()
本次数据清洗主要用到正则表达式,以下为数据清洗完整代码:
import csv, reimport pandas as pd
result = []rule1 = re.compile("(.+层)\(共(\d+)层\)")rule2 = re.compile("(\d+)年建")rule3 = re.compile("\d+室\d+厅")rule4 = re.compile("([\d\.]+)平米")rule5 = re.compile("([\d\.]+)")
with open("./ershoufang_shenzhen.csv", encoding="utf-8-sig") as f: f_csv = csv.reader(f) headers = next(f_csv) print(headers) for row in f_csv: tmp = {} tmp["楼盘名称"] = row[0] split_arr = re.sub("\n? {2,}\|?", "|", row[1]).split("|") for s in split_arr: s = s.strip() match = rule1.match(s) if match: tmp["楼层类型"] = match.group(1) tmp["楼层数"] = int(match.group(2)) continue match = rule2.match(s) if match: tmp["建造时间"] = match.group(1) continue match = rule3.match(s) if
match: tmp["户型"] = match.group(0) continue match = rule4.match(s) if match: tmp["建筑面积(平米)"] = float(match.group(1)) continue tmp["朝向"] = s split_arr = row[2].split("/") tmp["关注人数"] = int(split_arr[0].replace("人关注", "")) tmp["发布时间"] = split_arr[1].replace("发布", "") tmp["房价(单位:万)"] = float(row[3]) tmp["单价(元/平米)"] = float(rule5.search(row[4]).group(1)) result.append(tmp)df = pd.DataFrame(result)df.to_excel("result.xlsx", index=False)
1.本数据分析只做学习研究之用途,提供的结论仅供参考;
2.作者与贝壳找房无任何瓜葛,只是他家数据比较靠谱,大家也可以去其他二手房平台看看;
3.作者对地产行业了解甚微,相关描述可能存在不尽完善之处,请勿对号入座。

新上线一批4090/A800/H800/H100
特别适合企业级应用









