高熵合金(HEAs)是创新型的多主元合金,表现出优异的力学性能和巨大的成分空间,有希望为各个领域提供高性能候选材料。近年来,体心立方(BCC)高熵合金因其良好的耐高温性能而备受关注。然而,其较差的室温延展性限制了它们的应用。研究证明,可以通过调整成分来提高BCC高熵合金的室温可塑性,甚至不影响其室温及高温强度。考虑到高熵合金巨大的未探索的成分空间,通过实验试错法研发韧性BCC高熵合金的效率极低,因此需要提出一种更加高效地BCC高熵合金塑性预测及成分设计方法。
近日,北京航空航天大学材料科学与工程学院青年教师付悍巍所在团队提出了一种基于材料知识的机器学习策略,实现了对BCC高熵合金塑性的高精度建模,预测精度高于现有物理判据。通过考虑合金塑性理论、热力学和原子性质,开发了一组基于数学形式的低成本材料描述符,并证实了这些低成本的材料描述符可以有效地将材料知识引入机器学习建模,并且可以替代基于第一性原理计算的昂贵的材料描述符。该研究为后续的高强高塑性BCC高熵合金的成分设计提供了一条高效的路径。相关工作以题“Predicting and understanding the ductility of BCC
high entropy alloys via knowledge-integrated machine learning”的研究性文章发表在《Materials & Design》上。第一作者为博士研究生黄小雅,通讯作者为付悍巍。
论文链接
https://doi.org/10.1016/j.matdes.2024.112797

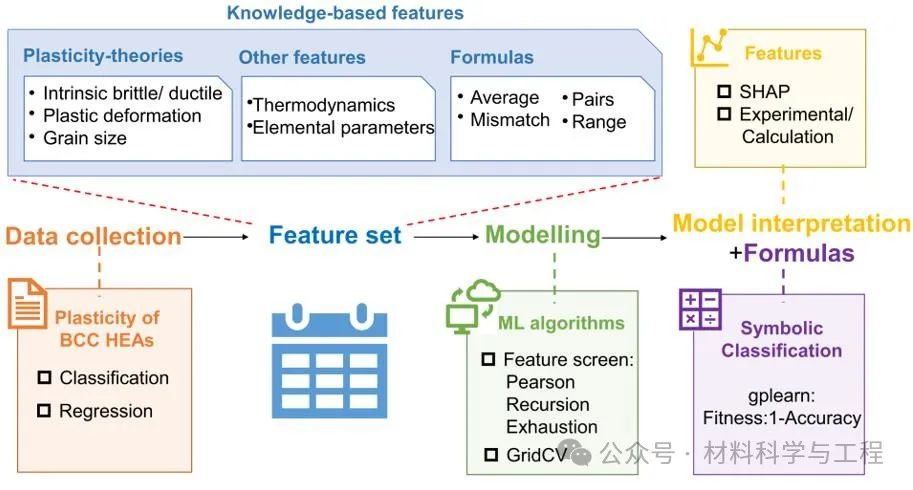
图1工作流程图:基于塑性理论(本质脆塑性、塑性行为和晶粒尺寸影响)、热力学因素(混合焓、混合熵等)以及多种元素性质(原子半径等)提出材料描述符(输入特征);采用了四种数学形式,包括均值、错配、基于原子对的均值和极差。预测任务包括塑性应变(εp)的回归任务和三分类(低塑性εp≤10%,中塑性%10<εp≤40%,高塑性εp>40%)任务,并分别经过算法筛选、特征工程和超参数优化获得最终的高精度预测模型。
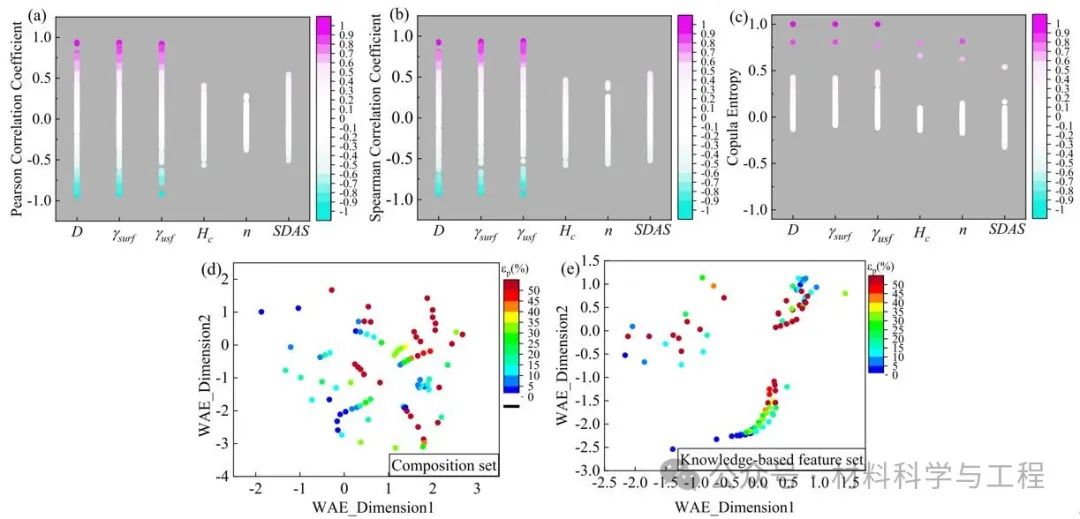
图2 基于知识的特征与材料因素之间的相关性:(a)皮尔逊相关系数(PCC);(b)斯皮尔曼相关系数(SCC);(c)连接熵(CE);(d)通过自动编码器(WAE)将合金成分数据集压缩到二维;(e)通过WAE将知识特征数据集压缩到二维。六个材料因素分别是本质脆塑性参数D、表面能γsurf、不稳定层错能γusf、应变硬化指数n、应变硬化能力Hc、二次枝晶间臂SDAS。基于知识的特征与材料因素之间有非常良好的线性或非线性关系,可很好地将材料知识引入机器学习模型。D、γsurf、γusf、是常见的昂贵的第一性原理描述符,提出的特征与其有极好的线性关系,因此可作为这些昂贵描述符的替代者。基于知识的特征集由WAE压缩后比成分集表现出更清晰地塑性分布规律,因此将有利于提高建模精度。
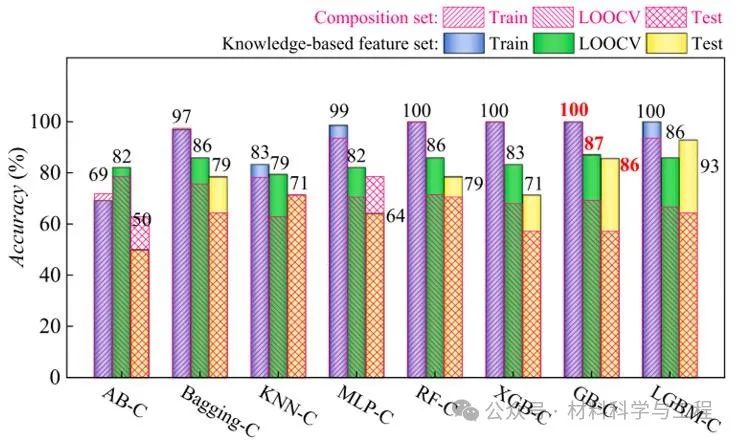
图3 三分类结果:经过优化机器学习模型精度对比表。集成算法梯度提升(GB)在训练集、测试集和验证集上表现出最优精度,且均高于85%,被作为最终的分类预测模型。
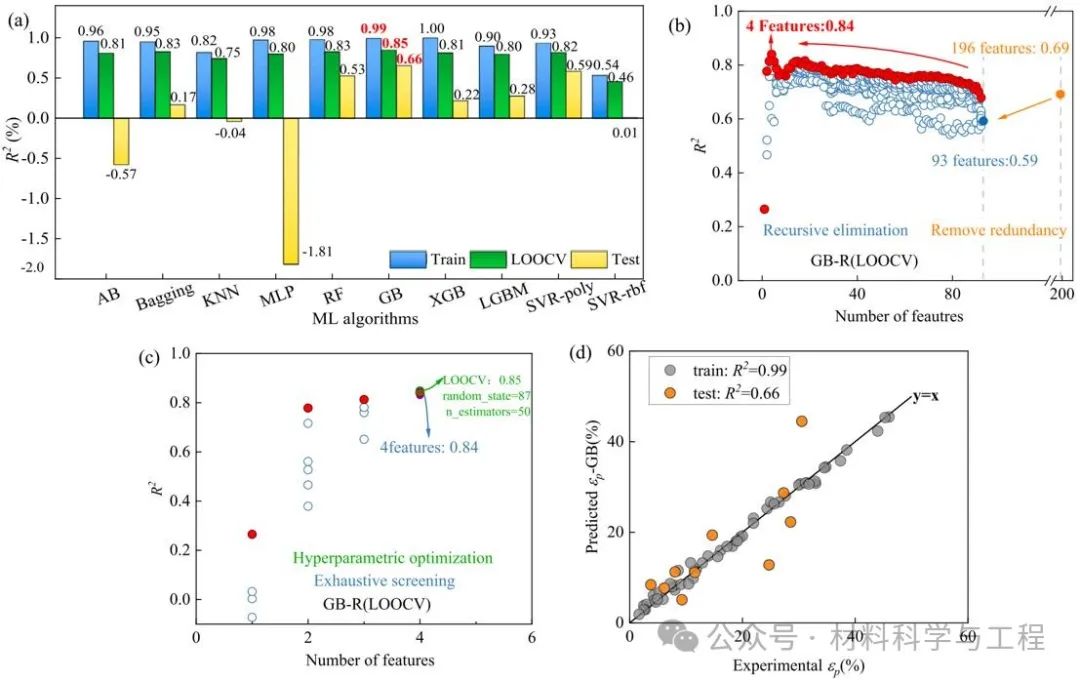
图4 回归结果:(a)优化的ML模型的结果对比。(b)-(c)基于GB算法的特征工程结果,包括去除冗余、递归消除、穷举和超参数优化。(d)基于优化的GB模型得到的训练集和测试集结果。集成算法梯度提升(GB)表现最优。

图5 三分类GB模型的可解释性分析(SHAP):(a)SHAP的重要性。(b)-(d)低塑性、中等塑性和高塑性的SHAP值。价电子浓度VEC的重要性最高,且对于三种类别的判别都有显著影响;但与半径相关的描述符在预测中也发挥了重要性。
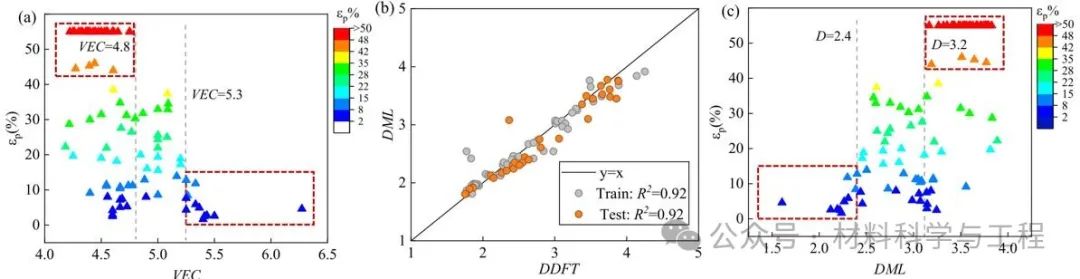
图6 BCC HEAs的两个常用塑性标准分析:(a)VEC与BCC HEAs塑性的关系;(b)基于优化的MLP模型对D的预测结果;(c)D与BCC HEAs塑性的关系。虽然D与VEC是常用的塑性判别参数,但是仅在小部分情况下可以适用。
该研究通过知识集成机器学习(ML)策略实现了体心立方高熵合金(BCC-HEAs)的一个关键但具有挑战性的目标,即精确预测其塑性。通过考虑塑性理论、热力学和原子性质,构建了一个基于知识的特征集,并证明了材料知识被有效地引入ML建模。发现了低成本数学描述符与DFT获得的昂贵材料塑性参数之间的强的线性相关性,这表明低成本描述符可作为昂贵描述符的替代。通过算法选择、特征工程和超参数优化,梯度提升算法在分类与回归两项任务中表现最好,其中分类模型对测试集和回归的预测精度达到了86%。通过关键特征筛选、可解释性分析等,证明了价电子浓度(VEC)和原子尺寸等对塑性预测的重要影响。
来自微信公众号“材料科学与工程”。感谢论文作者团队供稿支持。












