【新智元导读】最近,清华和微软的研究人员提出了一种全新的方法,能在保证输出质量不变的前提下,将提示词压缩到原始长度的20%!
在自然语言处理中,有很多信息其实是重复的。
如果能将提示词进行有效地压缩,某种程度上也相当于扩大了模型支持上下文的长度。
现有的信息熵方法是通过删除某些词或短语来减少这种冗余。
然而,作为依据的信息熵仅仅考虑了文本的单向上下文,进而可能会遗漏对于压缩至关重要的信息;此外,信息熵的计算方式与压缩提示词的真正目的并不完全一致。
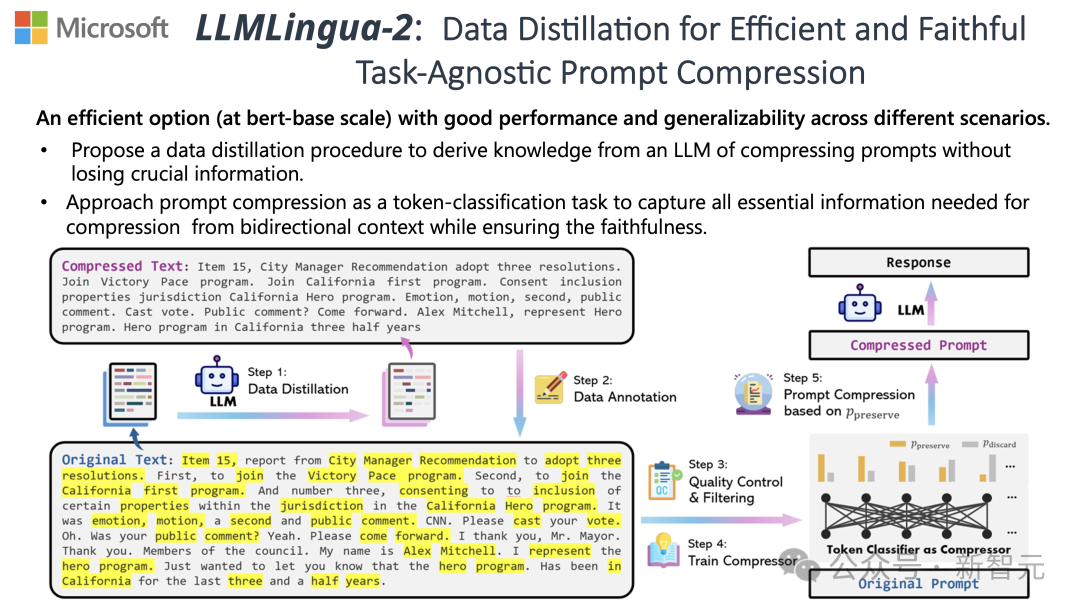
为了应对这些挑战,来自清华和微软的研究人员提出了一种全新的数据精炼流程——LLMLingua-2,目的是从大型语言模型(LLM)中提取知识,实现在不丢失关键信息的前提下对提示词进行压缩。
项目在GitHub上已经斩获3.1k星
结果显示,LLMLingua-2可以将文本长度大幅缩减至最初的20%,有效减少了处理时间和成本。
此外,与前一版本LLMLingua以及其他类似技术相比,LLMLingua 2的处理速度提高了3到6倍。
论文地址:https://arxiv.org/abs/2403.12968
在这个过程中,原始文本首先被输入模型。
模型会评估每个词的重要性,决定是保留还是删除,同时也会考虑到词语之间的关系。
最终,模型会选择那些评分最高的词汇组成一个更简短的提示词。
团队在包括MeetingBank、LongBench、ZeroScrolls、GSM8K和BBH在内的多个数据集上测试了LLMLingua-2模型。
尽管这个模型体积不大,但它在基准测试中取得了显著的性能提升,并且证明了其在不同的大语言模型(从GPT-3.5到Mistral-7B)和语种(从英语到中文)上具有出色的泛化能力。
系统提示:
作为一名杰出的语言学家,你擅长将较长的文段压缩成简短的表达方式,方法是去除那些不重要的词汇,同时尽可能多地保留信息。
用户提示:
请将给定的文本压缩成简短的表达形式,使得你(GPT-4)能够尽可能准确地还原原文。不同于常规的文本压缩,我需要你遵循以下五个条件:
1. 只移除那些不重要的词汇。
2. 保持原始词汇的顺序不变。
3. 保持原始词汇不变。
4. 不使用任何缩写或表情符号。
5. 不添加任何新的词汇或符号。
请尽可能地压缩原文,同时保留尽可能多的信息。如果你明白了,请对以下文本进行压缩:{待压缩文本}
压缩后的文本是:[...]
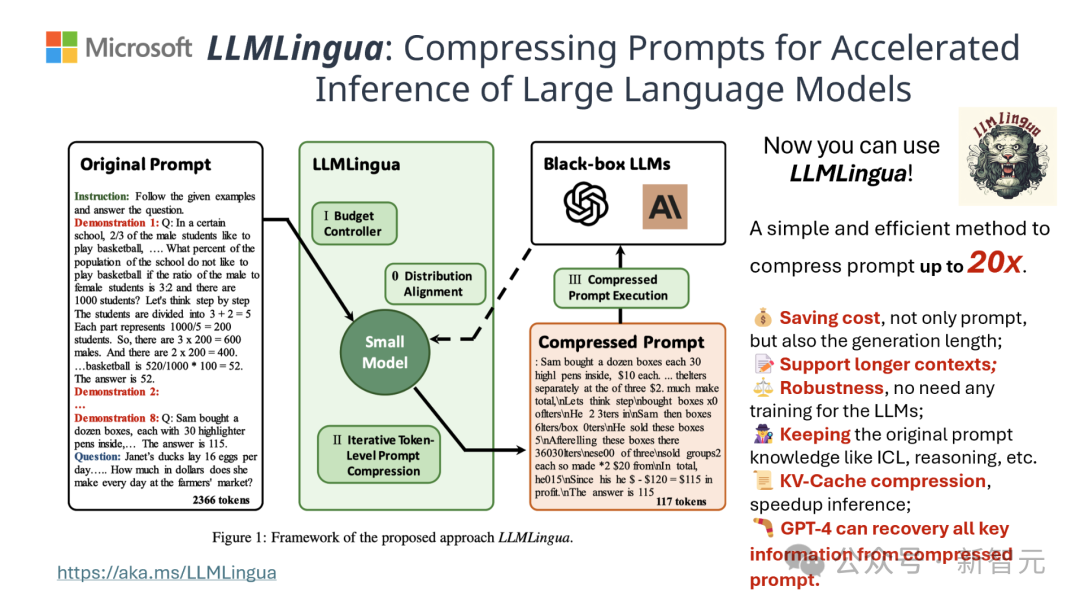
结果显示,在问答、摘要撰写和逻辑推理等多种语言任务中,LLMLingua-2都显著优于原有的LLMLingua模型和其他选择性上下文策略。
值得一提的是,这种压缩方法对于不同的大语言模型(从GPT-3.5到Mistral-7B)和不同的语言(从英语到中文)同样有效。
而且,只需两行代码,就可以实现LLMLingua-2的部署。
目前,该模型已经被集成到了广泛使用的RAG框架LangChain和LlamaIndex当中。
为了克服现有基于信息熵的文本压缩方法所面临的问题,LLMLingua-2采取了一种创新的数据提炼策略。
这一策略通过从GPT-4这样的大语言模型中抽取精华信息,实现了在不损失关键内容和避免添加错误信息的前提下,对文本进行高效压缩。
提示设计
要想充分利用GPT-4的文本压缩潜力,关键在于如何设定精确的压缩指令。
也就是在压缩文本时,指导GPT-4仅移除那些在原始文本中不那么重要的词汇,同时避免在此过程中引入任何新的词汇。
这样做的目的是为了确保压缩后的文本尽可能地保持原文的真实性和完整性。

标注与筛选
研究人员利用了从GPT-4等大语言模型中提炼出的知识,开发了一种新颖的数据标注算法。
这个算法能够对原文中的每一个词汇进行标注,明确指出在压缩过程中哪些词汇是必须保留的。
为了保证所构建数据集的高质量,他们还设计了两种质量监控机制,专门用来识别并排除那些品质不佳的数据样本。

压缩器
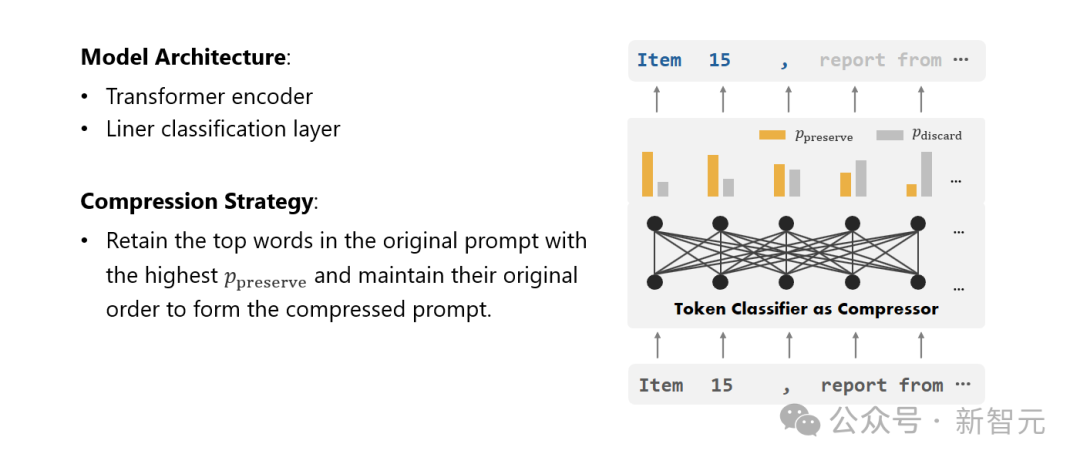
最后,研究人员将文本压缩的问题转化为了一个对每个词汇(Token)进行分类的任务,并采用了强大的Transformer作为特征提取器。
这个工具能够理解文本的前后关系,从而精确地抓取对于文本压缩至关重要的信息。
通过在精心构建的数据集上进行训练,研究人员的模型能够根据每个词汇的重要性,计算出一个概率值来决定这个词汇是应该被保留在最终的压缩文本中,还是应该被舍弃。
研究人员在一系列任务上测试了LLMLingua-2的性能,这些任务包括上下文学习、文本摘要、对话生成、多文档和单文档问答、代码生成以及合成任务,既包括了域内的数据集也包括了域外的数据集。
测试结果显示,研究人员的方法在保持高性能的同时,减少了最小的性能损失,并且在任务不特定的文本压缩方法中表现突出。
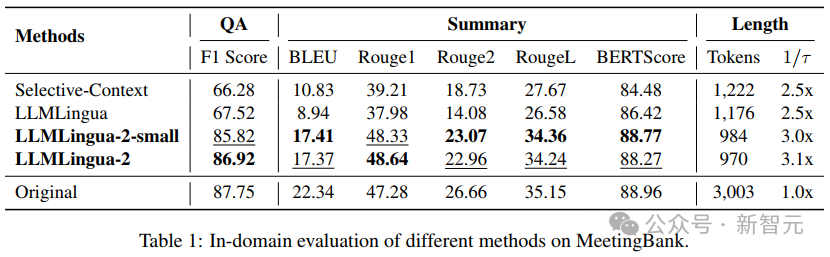
- 域内测试(MeetingBank)
研究人员将LLMLingua-2在MeetingBank测试集上的表现与其他强大的基线方法进行了对比。
尽管他们的模型规模远小于基线中使用的LLaMa-2-7B,但在问答和文本摘要任务上,研究人员的方法不仅大幅提升了性能,而且与原始文本提示的表现相差无几。
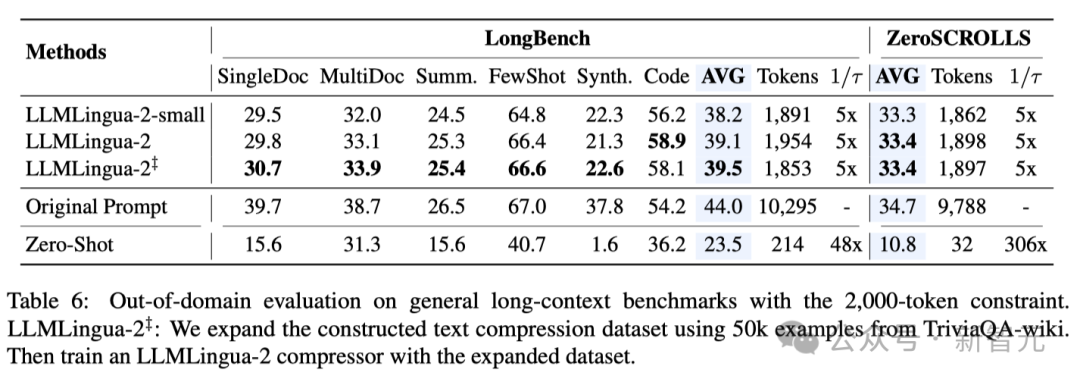
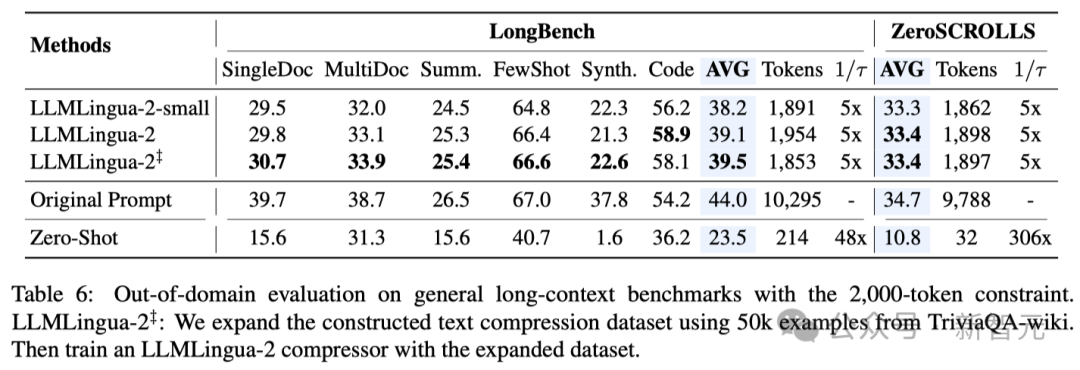
- 域外测试(LongBench、GSM8K和BBH)
考虑到研究人员的模型仅在MeetingBank的会议记录数据上进行了训练,研究人员进一步探索了其在长文本、逻辑推理和上下文学习等不同场景下的泛化能力。
值得一提的是,尽管LLMLingua-2只在一个数据集上训练,但在域外的测试中,它的表现不仅与当前最先进的任务不特定压缩方法相媲美,甚至在某些情况下还有过之而无不及。
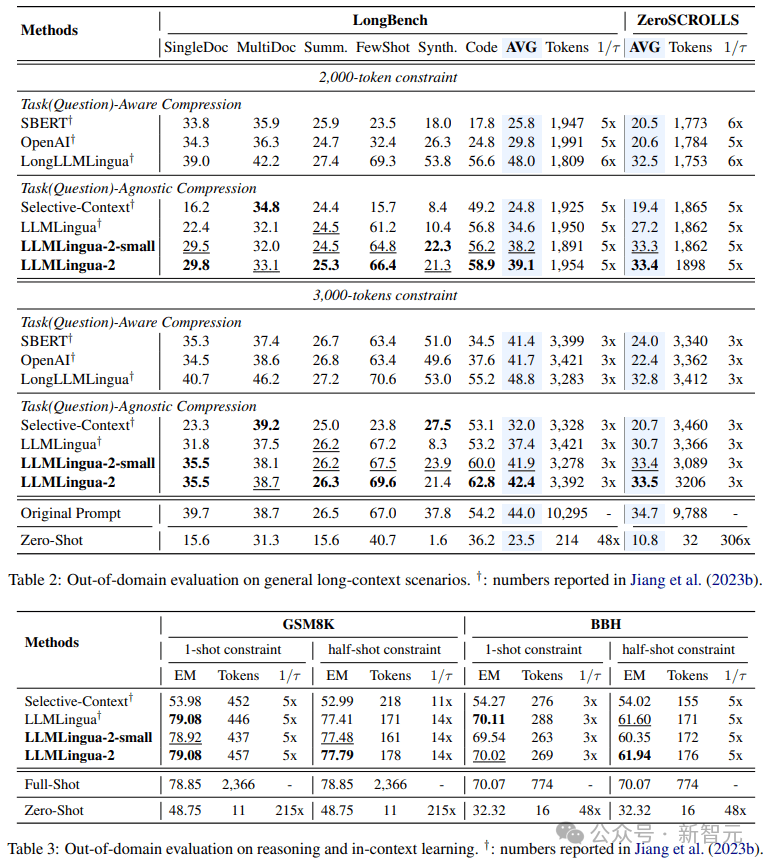
即使是研究人员的较小模型(BERT-base大小),也能达到与原始提示相当的性能,在某些情况下甚至略高于原始提示。
虽然研究人员的方法取得了可喜的成果,但与其他任务感知压缩方法(如Longbench上的LongLLMlingua)相比,研究人员的方法还存在不足。
研究人员将这种性能差距归因于它们从问题中获取的额外信息。不过,研究人员的模型具有与任务无关的特点,因此在不同场景中部署时,它是一种具有良好通用性的高效选择。
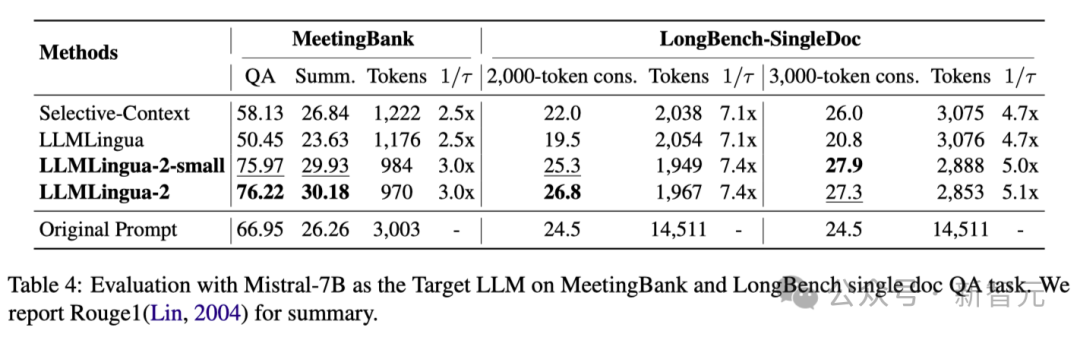
上表4列出了使用Mistral-7Bv0.1 4作为目标LLM的不同方法的结果。
与其他基线方法相比,研究人员的方法在性能上有明显的提升,展示了其在目标LLM上良好的泛化能力。
值得注意的是,LLMLingua-2的性能甚至优于原始提示。
研究人员推测,Mistral-7B在管理长上下文方面的能力可能不如GPT-3.5-Turbo。
研究人员的方法通过提供信息密度更高的短提示,有效提高了 Mistral7B 的最终推理性能。
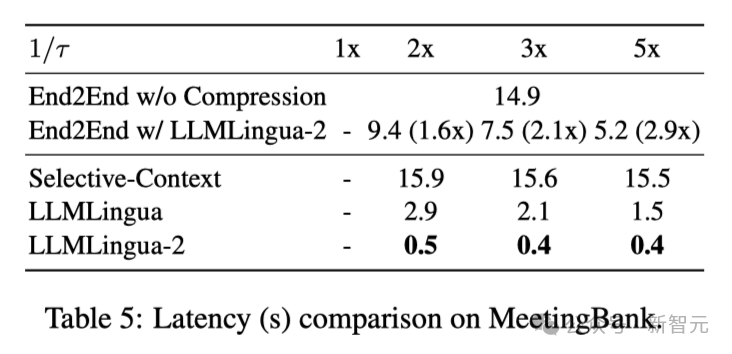
上表5显示了不同系统在不同压缩比的V100-32G GPU上的延迟。
结果表明,与其他压缩方法相比,LLMLingua2的计算开销要小得多,可以实现1.6倍到2.9倍的端到端速度提升。
此外,研究人员的方法还能将GPU内存成本降低8倍,从而降低对硬件资源的需求。
上下文意识观察 研究人员观察到,随着压缩率的增加,LLMLingua-2可以有效地保持与完整上下文相关的信息量最大的单词。
这要归功于双向上下文感知特征提取器的采用,以及明确朝着及时压缩目标进行优化的策略。
研究人员观察到,随着压缩率的增加,LLMLingua-2可以有效地保持与完整上下文相关的信息量最大的单词。
这要归功于双向上下文感知特征提取器的采用,以及明确朝着及时压缩目标进行优化的策略。
最后研究人员让GPT-4 从 LLMLingua-2压缩提示中重构原始提示音。
结果表明,GPT-4可以有效地重建原始提示,这表明在LLMLingua-2压缩过程中并没有丢失基本信息。
https://llmlingua.com/llmlingua2.html











