今日AI资讯1.Keep在线运动课程15%为AIGC生产
2.AI语音克隆创企联手AI硬件公司
3.创新奇智:发布智孔明工业大模型2.0版本
4.vivo:开放蓝心大模型应用下载
5.Adobe:推出GenStudio人工智能广告创作平台
6.Airtable AI平台推出了新的AI功能
7.开启智能新时代:2024年中国AI大模型产业发展报告
"用起一时爽,找时火葬场",很好的形容了现在工作的小伙伴们找资料时的状态,尤其是工作多年的老司机,各种方案设计,本地都可能存不下了,有的上硬盘、有的上云盘,结果就是不好找、找不到、找到的不是我想要的那个版本。那么今天给大家推荐一款开源项目:LangChain-Chatchat
 支持中文,可私有化部署,免费商用!
支持中文,可私有化部署,免费商用!Chatchat介绍
LangChain-Chatchat (原Langchain-ChatGLM) :基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现,开源、可离线部署的检索增强生成(RAG)大模型知识库项目。
虽然开源时间不久,但是势头很猛,已经斩获25.7K Star。

- 利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案;
- 支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用
开源模型离线私有部署。也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入; - 项目采用Apache License,可以免费商用,无需付费。
实现原理
实现原理如下图所示,过程包括:本地文件 -> load文本 -> 文本切分 -> 文本向量化 -> query向量化 -> 在文本向量中匹配出与query向量最相似的 top k -> 匹配出的文本作为上下文和query拼写到 prompt 中 -> 提交给 LLM -> 生成答案。
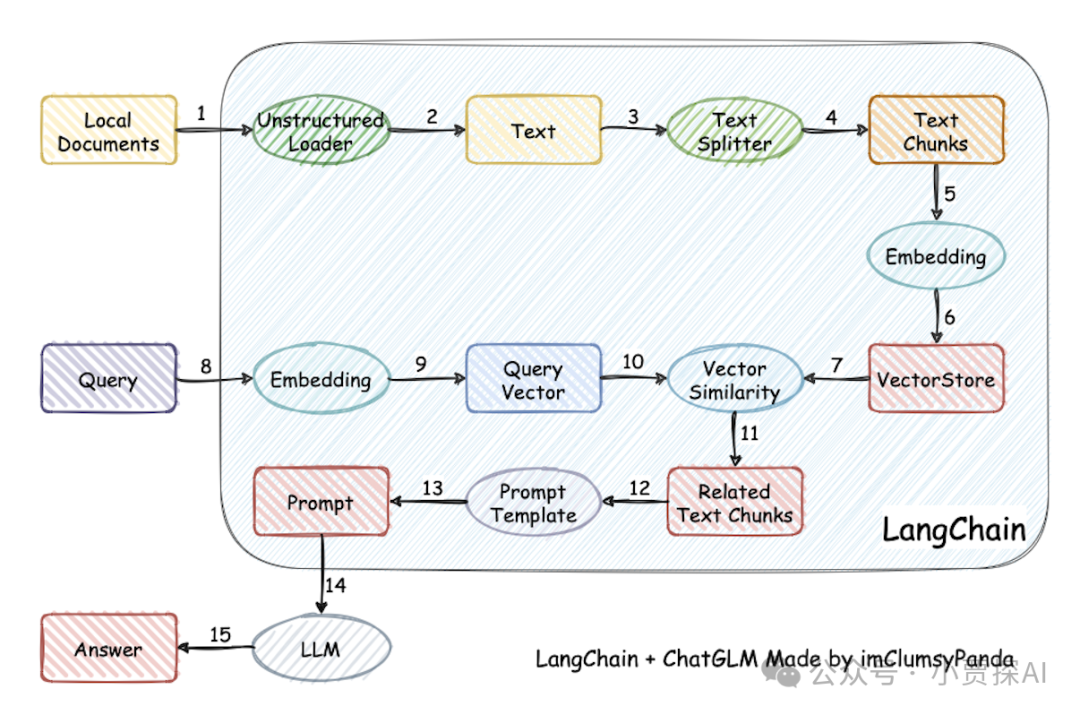
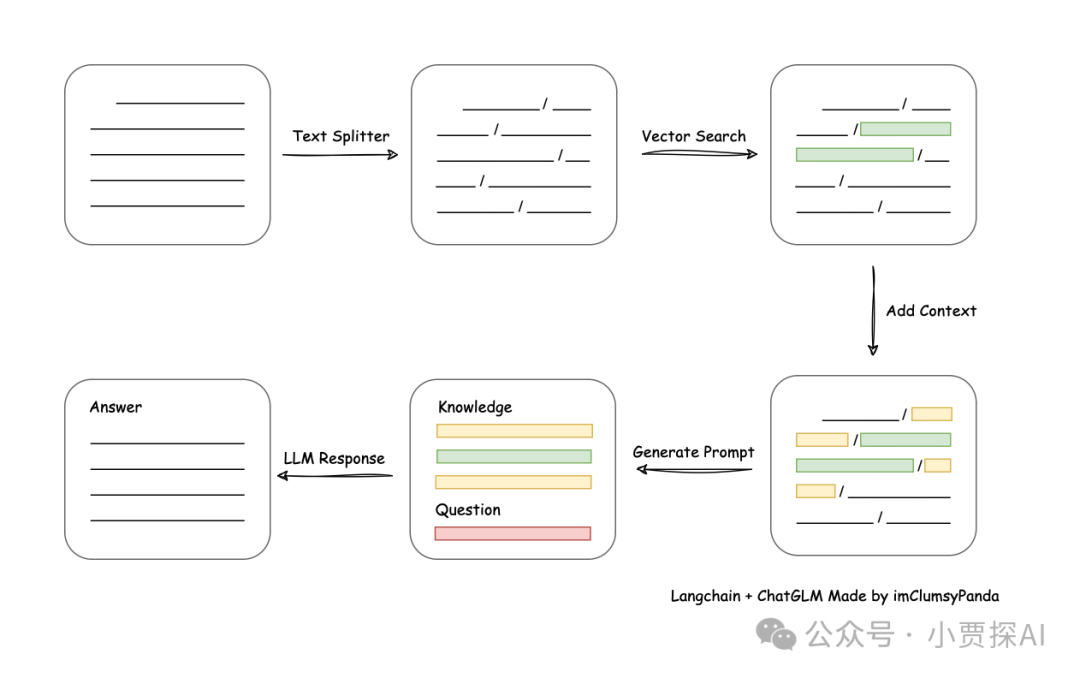
从文档处理角度来看,实现流程如下:
环境部署
软件环境
- Linux Ubuntu 22.04.5 kernel version 6.7
- Python 版本: >= 3.8(很不稳定), < 3.12,推荐3.11.7
硬件环境
取决于使用的LLM,想要顺利在GPU运行本地模型的 FP16 版本,至少需要以下的硬件配置,来保证能够实现稳定连续对话:
- ChatGLM3-6B & LLaMA-7B-Chat 等
7B模型
没有对 Int4 模型进行适配,不保证Int4模型能够正常运行。
Embedding 模型将会占用 1-2G 的显存。
例如,运行ChatGLM3-6B FP16 模型,显存占用13G,推荐使用16G以上内存。
三种部署方式:轻量化部署、Docker 部署、常规部署
1.轻量化部署
该模式的配置方式与常规模式相同,但无需安装 torch 等重依赖,通过在线API实现 LLM 和 Ebeddings 相关功能,适合没有显卡的电脑使用。
$ pip install -r requirements_lite.txt
$ python startup.py -a --lite
该模式支持的在线 Embeddings 包括:
在 model_config.py 中 将 LLM_MODELS 和 EMBEDDING_MODEL 设置为可用的在线 API 名称即可。
2.Docker 部署
docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.7
- 该版本镜像大小 43.1GB,使用 v0.2.6,以 nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04 为基础镜像
- 该版本内置两个 Embedding 模型:m3e-large,text2vec-bge-large-chinese(默认启用后者),内置 chatglm2-6b-32k
- 该版本目标为方便一键部署使用,确保已经在 Linux 上安装 NVIDIA 驱动程序
3.常规部署
# 创建虚拟环境
$ source activate ~/.bashrc
$ conda create -n env_name python=3.8
$ conda activate env_name
# 更新py库
$ pip3 install --upgrade pip
# 拉取仓库
$ git clone --recursive https://github.com/chatchat-space/Langchain-Chatchat.git
$ cd Langchain-Chatchat
$ pip install -r requirements.txt
# 默认依赖包括基本运行环境(FAISS向量库)。以下是可选依赖:
- 如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
- 如果要开启 OCR GPU 加速,请安装 rapidocr_paddle[gpu]
- 如果要使用在线 API 模型,请安装对用的 SDK
# 模型下载
需要先安装Git LFS,然后下载
$ git lfs install
$ git clone https://huggingface.co/THUDM/chatglm2-6b
$ git clone https://huggingface.co/moka-ai/m3e-base
# 初始化知识库
## 如果创建过知识库,执行以下命令:
$ python init_database.py --create-tables
## 如果第一次运行,未创建过知识库,执行以下命令:
$ python init_database.py --recreate-vs
# 一键启动
$ python startup.py -a
# 多卡启动
CUDA_VISIBLE_DEVICES=0,1 python startup.py -a
可选参数包括:
-a (或--all-webui),
--all-api,
--llm-api,
-c (或--controller),
--openai-api, -m (或--model-worker),
--api,
--webui,其中:
--all-webui 为一键启动 WebUI 所有依赖服务;
--all-api 为一键启动 API 所有依赖服务;
--llm-api 为一键启动 Fastchat 所有依赖的 LLM 服务;
--openai-api 为仅启动 FastChat 的 controller 和 openai-api-server 服务;
其他为单独服务启动选项。
若想指定非默认模型,需要用 --model-name 选项,示例:
$ python startup.py --all-webui --model-name Qwen-7B-Chat
# 更多信息可通过 python startup.py -h 查看。
Web UI 对话界面: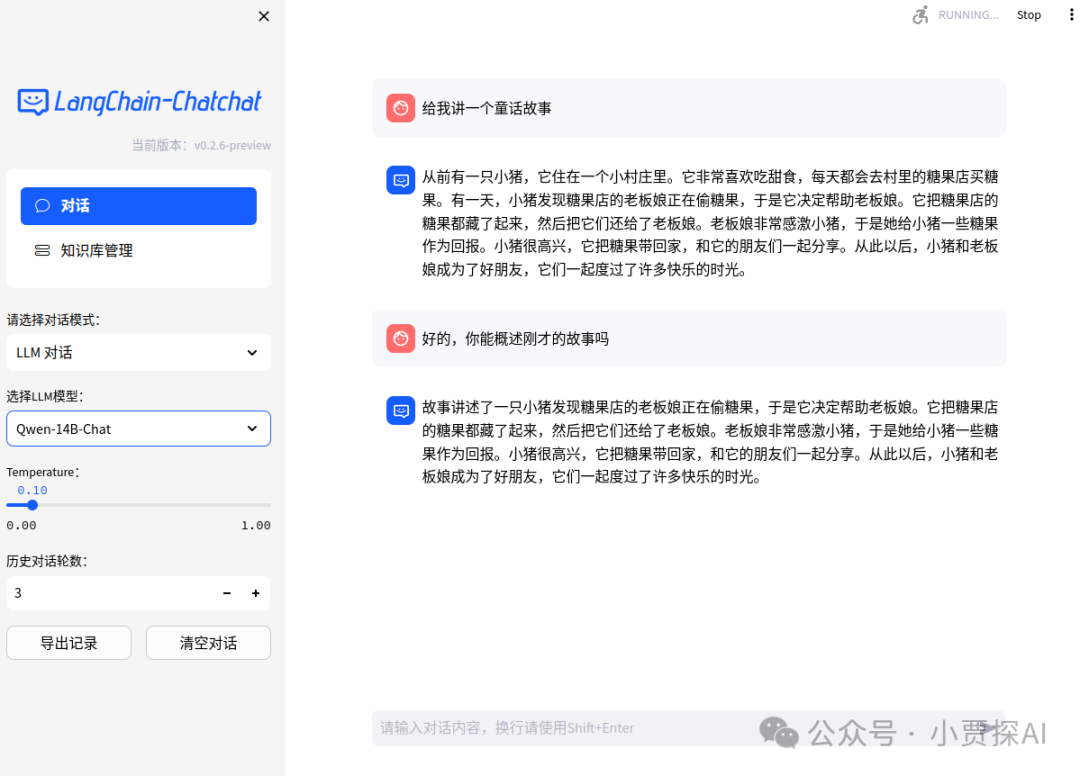
Web UI 知识库管理页面: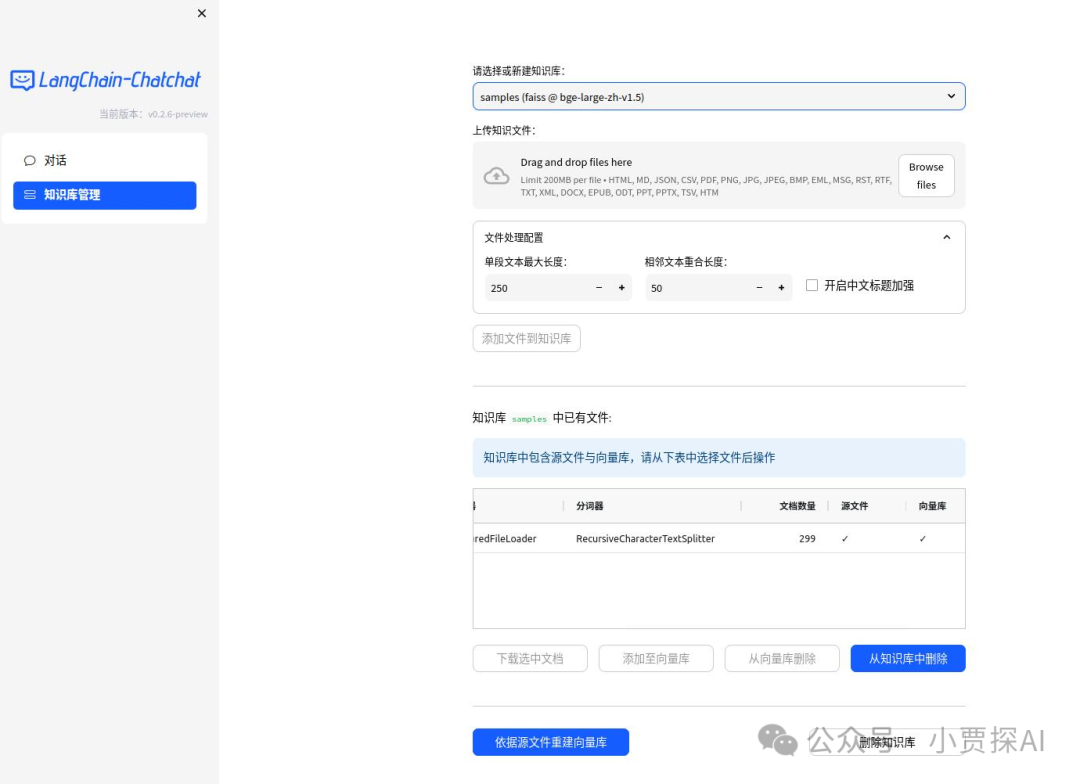
注意: 以上方式只是为了快速上手,如果需要更多的功能和自定义启动方式 ,请参考详细文档。
引用
- https://github.com/chatchat-space/Langchain-Chatchat
关于我
欢迎关注,一起进步一起成长