这篇文章在国外知名的网站 medium 上面获得了一千多的赞,给出了很多建议,同时也备注了论文的来源,所以这么优质的文章,大家一定要多多宣传哈
训练深度神经网络是困难的。它需要知识和经验,以适当的训练和获得一个最优模型。在这篇文章中,我想分享我在训练深度神经网络时学到的东西。以下提示和技巧可能对你的研究有益,并可以帮助你加速网络架构或参数搜索。
现在,让我们开始吧……
整理自:https://towardsdatascience.com/a-bunch-of-tips-and-tricks-for-training-deep-neural-networks-3ca24c31ddc8
在你开始建立你的网络体系结构,你需要做的第一件事是验证输入到网络的数据,确保输入(x)对应于一个标签(y)。在预测的情况下,确保真实标签(y)正确编码标签索引(或者one-hot-encoding)。否则,训练就不起作用。
决定是选择使用预模型还是从头开始训练你的网络?
如果问题域中的数据集类似于ImageNet数据集,则对该数据集使用预训练模型。使用最广泛的预训练模型有VGG net、ResNet、DenseNet或Xception等。有许多层架构,例如,VGG(19和16层),ResNet(152, 101, 50层或更少),DenseNet(201, 169和121层)。注意:不要尝试通过使用更多的层网来搜索超参数(例如VGG-19, ResNet-152或densen -201层网络,因为它在计算量很大),而是使用较少的层网(例如VGG-16, ResNet-50或densen -121层)。选择一个预先训练过的模型,你认为它可以用你的超参数提供最好的性能(比如ResNet-50层)。在你获得最佳超参数后,只需选择相同但更多的层网(如ResNet-101或ResNet-152层),以提高准确性。
ImageNet:http://www.image-net.org/challenges/LSVRC/2012/
VGG net :https://arxiv.org/abs/1409.1556
ResNet:https://arxiv.org/abs/1512.03385
DenseNet:https://arxiv.org/abs/1608.06993
Xception :https://arxiv.org/abs/1610.02357
微调几层,或者如果你有一个小的数据集,只训练分类器,你也可以尝试在你要微调的卷积层之后插入Dropout层,因为它可以帮助对抗网络中的过拟合。
Dropout:http://jmlr.org/papers/v15/srivastava14a.html
如果你的数据集与ImageNet数据集不相似,你可以考虑从头构建并训练你的网络。
在你的网络中始终使用归一化层(normalization layers)。如果你使用较大的批处理大小(比如10个或更多)来训练网络,请使用批标准化层(BatchNormalization)。否则,如果你使用较小的批大小(比如1)进行训练,则使用InstanceNormalization层。请注意,大部分作者发现,如果增加批处理大小,那么批处理规范化会提高性能,而当批处理大小较小时,则会降低性能。但是,如果使用较小的批处理大小,InstanceNormalization会略微提高性能。或者你也可以尝试组规范化(GroupNormalization)。
BatchNormalization:https://arxiv.org/abs/1502.03167
InstanceNormalization:https://arxiv.org/abs/1607.08022
GroupNormalization:https://arxiv.org/abs/1803.08494
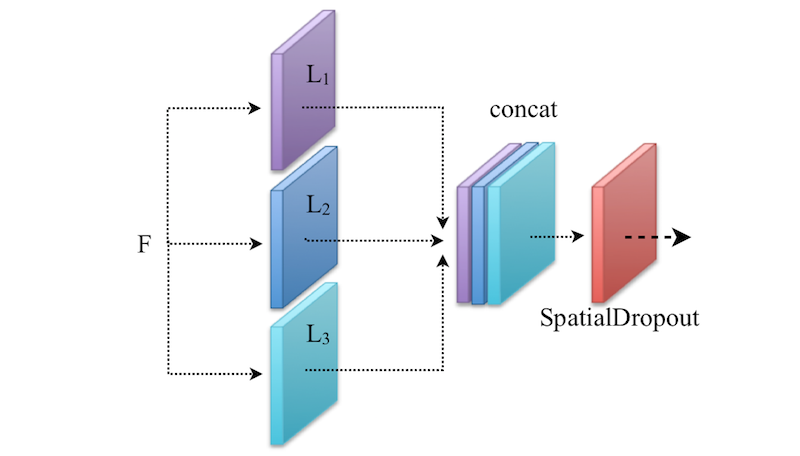
如果你有两个或更多的卷积层(比如Li)对相同的输入(比如F)进行操作(参考下面的示意图理解),那么在特征连接后使用SpatialDropout。由于这些卷积层是在相同的输入上操作的,因此输出特征很可能是相关的。因此,SpatialDropout删除了那些相关的特征,并防止网络中的过拟合。
注意: 它主要用于较低的层而不是较高的层。
SpatialDropout:https://arxiv.org/abs/1411.4280
为了确定你的网络容量,尝试用一小部分训练例子来超载你的网络(andrej karpathy的提示)。如果它没有超载,增加你的网络容量。在过拟合后,使用正则化技巧如L1、L2、Dropout或其他技术来对抗过拟合。
L1:https://keras.io/regularizers/
L2:https://keras.io/regularizers/
Dropout:http://jmlr.org/papers/v15/srivastava14a.html
另一种正则化技术是约束或限制你的网络权值。这也有助于防止网络中的梯度爆炸问题,因为权值总是有界的。与L2正则化相反,在你的损失函数中惩罚高权重,这个约束直接正则化你的权重。你可以在Keras中轻松设置权重约束:
from keras.constraints import max_norm# add to Dense layersmodel.add(Dense(64, kernel_constraint=max_norm(2.)))# or add to Conv layersmodel.add(Conv2D(64, kernel_constraint=max_norm(2.)))
对数据进行均值减法有时会产生非常糟糕的效果,特别是对灰度图像进行减法(我个人在前景分割领域就遇到过这个问题)。
在训练前和训练期间,确保打乱训练数据,以防你不能从时序数据中获取有用信息。这可能有助于提高您的网络性能。
如果你的问题域与稠密预测(dense prediction)相关(如语义分割),我建议你使用膨胀残差网络作为预训练模型,因为它最适合稠密预测。
Dilated Residual Networks:https://arxiv.org/abs/1705.09914
要捕获对象周围的上下文信息,可以使用多尺度特性的池化模块。该思想成功地应用于语义分割或前景分割中。
semantic segmentation:https://arxiv.org/abs/1802.02611
foreground segmentation:https://arxiv.org/abs/1808.01477
Opt-out void labels(或模糊区域)从您的损失或精度计算,如果有。这可以帮助你的网络在预测时更有信心。
如果你有高度不平衡的数据问题,在训练期间应用类别加权操作。换句话说,给稀少的类更多的权重,但给主要类更少的权重。使用sklearn可以很容易地计算类权重。或者尝试使用过采样和欠采样技术重新采样你的训练集。这也可以帮助提高预测的准确性。
sklearn:http://scikit-learn.org/stable/modules/generated/sklearn.utils.class_weight.compute_class_weight.html
OverSampling and UnderSampling techniques:https://en.wikipedia.org/wiki/Oversampling_and_undersampling_in_data_analysis
选择一个正确的优化器。有许多流行的自适应优化器,如Adam, Adagrad, Adadelta,或RMSprop等。SGD+动量被广泛应用于各种问题领域。有两件事需要考虑:第一,如果你关心快速收敛,使用自适应优化器,如Adam,但它可能会陷入局部极小,提供了糟糕的泛化(下图)。第二,SGD+momentum可以实现找到全局最小值,但它依赖于鲁棒初始化,而且可能比其他自适应优化器需要更长的时间来收敛(下图)。我建议你使用SGD+动量,因为它能达到更好的最佳效果。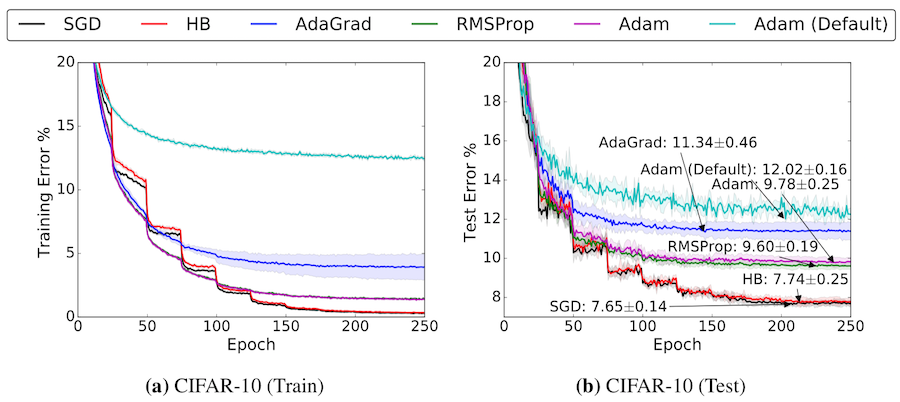
有三个学习率起点(即1e- 1,1e -3和1e-6)。如果您对预训练模型进行微调,请考虑小于1e-3(比如1e-4)的低学习率。如果您从头开始训练您的网络,请考虑一个大于或等于1e-3的学习率。您可以尝试这些起点,并调整它们,看看哪个是最好的,选择那个。还有一件事,您可以考虑通过使用 Learning Rate Schedulers来降低训练过程中的学习率。这也可以帮助提高网络性能。
Learning Rate Schedulers:https://keras.io/callbacks/#learningratescheduler
除了Learning Rate Schedule 外,即在一定的次数后降低学习率,还有另一种方式,我们可以由一些因素减少学习率,如果验证损loss在某些epoch(比如5)停止改善,减小学习率和如果验证损失停止改善在某些epoch(比如10),停止训练过程。这可以通过在Keras中使用early stop的ReduceLROnPlateau很容易做到。
ReduceLROnPlateau:https://keras.io/callbacks/#reducelronplateau
EarlyStopping:https://keras.io/callbacks/#earlystopping
如果您在dense prediction领域工作,如前景分割或语义分割,您应该使用跳过连接,因为对象边界或有用的信息会由于最大池化操作或strided convolutions而丢失。这也可以帮助您的网络轻松地学习特征空间到图像空间的特征映射,有助于缓解网络中的消失梯度问题。
skip connections:https://arxiv.org/abs/1505.04597
数据越多越好!总是使用数据增强,如水平翻转,旋转,缩放裁剪等。这可以帮助大幅度提高精确度。
你必须要有一个高速的GPU来进行训练,但是这有点昂贵。如果你想使用免费的云GPU,我推荐使用谷歌Colab。如果你不知道从哪里开始,看看我之前的文章或者尝试各种云GPU平台,如Floydhub或Paperspace等。
Google Colab:https://colab.research.google.com/notebooks/welcome.ipynb#recent=true
使用教程:https://towardsdatascience.com/a-comprehensive-guide-on-how-to-fine-tune-deep-neural-networks-using-keras-on-google-colab-free-daaaa0aced8f
Floydhub:https://www.floydhub.com
Paperspace:https://www.paperspace.com
在ReLU之前使用最大池化来节省一些计算。由于ReLU阈值的值为0:f(x)=max(0,x)和最大池化只有max激活:f(x)=max(x1,x2,…,xi),使用Conv > MaxPool > ReLU 而不是Conv > ReLU > MaxPool。
例如,假设我们有两个从Conv来的激活值(即0.5和-0.5):
因此MaxPool > ReLU = max(0, max(0.5,-0.5)) = 0.5
和ReLU > MaxPool = max(max(0,0.5), max(0,-0.5)) = 0.5
看到了吗?这两个操作的输出仍然是0.5。在这种情况下,使用MaxPool > ReLU可以节省一个max 操作。
考虑采用深度可分离卷积运算,与常规的卷积运算相比,该运算速度快,且参数数量大大减少。
Depthwise Separable Convolution:https://arxiv.org/abs/1610.02357
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)







