我们翻译整理最新论文:大型语言模型时代的图机器学习综述,文末有论文连接。
图在表示各种领域中的复杂关系方面扮演着重要角色,如社交网络、知识图谱和分子发现。随着深度学习的出现,图神经网络(GNNs)已成为图机器学习(Graph ML)的基石。最近,LLMs 在语言任务中展示了前所未有的能力,并广泛应用于计算机视觉和推荐系统等多种应用。这一显著的成功也引起了将 LLMs 应用于图领域的兴趣。图,特别是知识图谱,富含可靠的事实知识,可以利用这些知识来增强 LLMs 的推理能力,并可能缓解它们的局限性,如幻觉和缺乏可解释性。鉴于这一研究方向的快速发展,有必要进行系统性的回顾,总结 LLMs 时代图 ML 的最新进展,为研究人员和从业者提供深入的理解。因此,在这项调查中,我们首先回顾了图 ML 的最新发展。然后,我们探讨了 LLMs 如何被用来增强图特征的质量,减少对标记数据的依赖,并解决图异质性和分布外(OOD)泛化等挑战。之后,我们深入探讨了图如何增强 LLMs,突出了它们在增强 LLM 预训练和推理方面的能力。此外,我们调查了各种应用并讨论了这一有前途领域的潜在未来方向。
 张长旺,旺知识
张长旺,旺知识
关键词:图机器学习,图基础模型,图学习,大型语言模型(LLMs),预训练和微调,提示,表示学习。
1 引言
图数据在许多实际应用中无处不在,包括社交图、知识图和推荐系统。通常,图由节点和边组成,例如在社交图中,节点代表用户,边代表关系。除了拓扑结构,图往往具有各种节点特征,如文本描述,这些特征提供了有关节点的有价值的上下文和语义信息。为了有效地建模图,图机器学习(Graph ML)已经引起了显著的关注。随着深度学习(DL)的出现,图神经网络(GNNs)由于其消息传递机制而成为图 ML 中的关键技术。这种机制允许每个节点通过递归地接收和聚合来自相邻节点的消息来获得其表示,从而捕获图结构内的高阶关系和依赖性。为了减轻对监督数据的依赖,许多研究集中在开发自监督的图 ML 方法上,以推进 GNNs 捕获可转移的图模式,增强它们在各种任务中的泛化能力。鉴于图数据应用的指数级增长,研究人员正在积极开发更强大的图 ML 方法。最近,大型语言模型(LLMs)开启了人工智能的新趋势,并在自然语言处理(NLP)中展示了显著的能力。随着这些模型的发展,LLMs 不仅被应用于语言任务,还展示了在计算机视觉(CV)和推荐系统等各种应用中的巨大潜力。LLMs 在复杂任务中的有效性归因于它们在架构和数据集规模方面的广泛规模。例如,具有 175 亿参数的 GPT-3 通过生成类似人类的文本、回答复杂问题和编码展示了令人兴奋的能力。此外,LLMs 能够把握广泛的一般知识和复杂的推理,这归功于它们庞大的训练数据集。因此,它们在语言语义和知识推理方面的能力使它们能够学习语义信息。此外,LLMs 表现出出现能力,在有限或没有特定训练的情况下,在新任务和领域中表现出色。这一属性有望在不同下游数据集和任务中提供高泛化能力,即使在少量样本或零样本情况下也是如此。因此,利用 LLMs 在图机器学习(Graph ML)中的能力越来越受到关注,并有望增强 Graph ML 向图基础模型(GFMs)的方向发展。
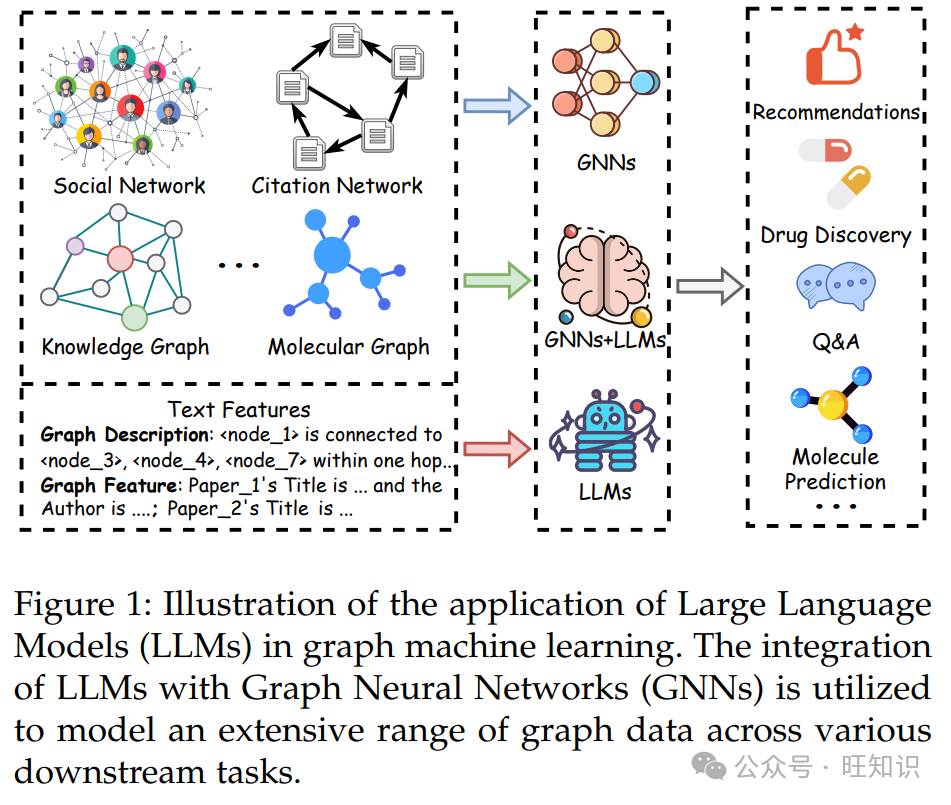
GFMs 通常在大量数据上进行训练,并可以适应广泛的下游任务。通过利用 LLMs 的能力,预计可以增强图 ML 泛化各种任务的能力,从而促进 GFMs。目前,研究人员已经做出了一些初步的努力,探索 LLMs 在推进 Graph ML 向 GFMs 方向的潜力。图 1 展示了一个集成 LLMs 和 GNNs 用于各种图任务的示例。首先,一些方法利用 LLMs 来减轻传统图 ML 对标记数据的依赖,它们根据隐式和显式的图结构信息进行推断。例如,InstructGLM [20] 通过将图数据序列化为标记并编码有关图的结构信息来微调模型,如 LlaMA [23] 和 T5 [24],以解决图任务。其次,为了克服特征质量问题,一些方法进一步利用 LLMs 来增强图特征的质量。例如,SimTeG [25] 在文本图数据集上微调 LLMs 以获得文本属性嵌入,然后将其用于增强 GNN 进行各种下游任务。此外,一些研究探索使用 LLMs 来解决图的异质性和 OOD(分布外)泛化等挑战。
另一方面,尽管 LLM 在各个领域取得了巨大成功,但它仍然面临几个挑战,包括幻觉、实际意识和缺乏可解释性。图,特别是知识图,以结构化格式捕获了大量高质量和可靠的事实知识。因此,将图结构纳入 LLMs 可以提高 LLMs 的推理能力,并可能缓解这些局限性。为此,已经做出了努力,探索图在增强 LLMs 的可解释性 [32]、[33] 和减少幻觉 [34]、[35] 方面的潜力。鉴于这一领域的快速发展和重大潜力,迫切需要对 LLMs 时代图应用和图 ML 的最新进展进行全面回顾。
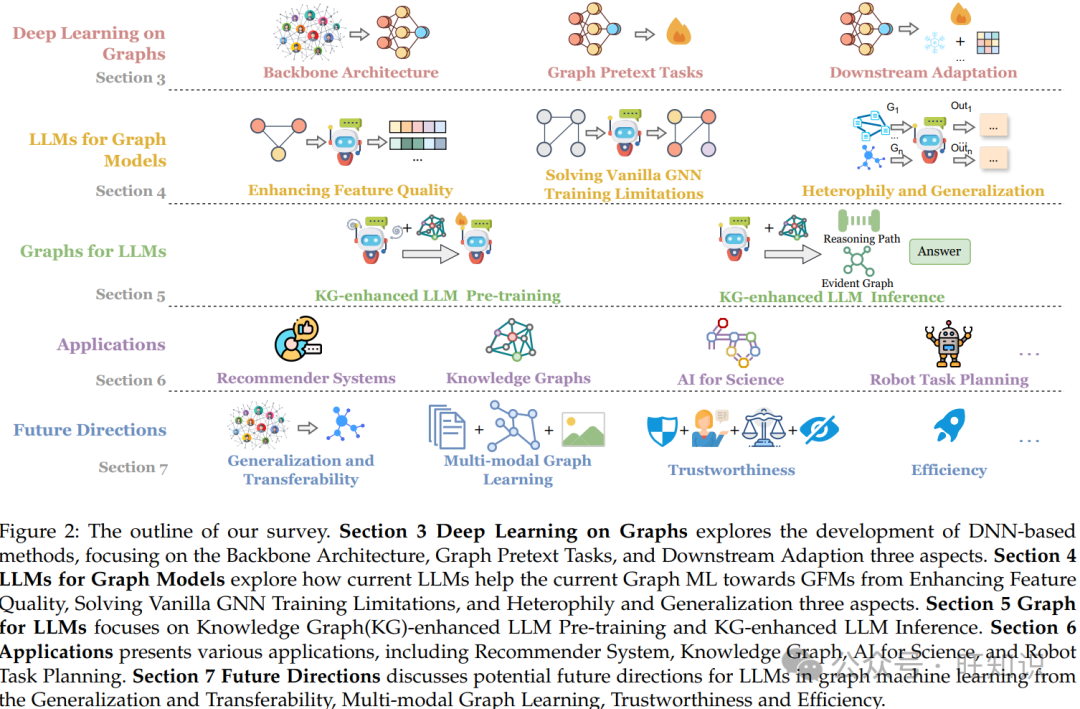
因此,在这项调查中,我们的目标是提供 LLMs 时代图机器学习的综合回顾。调查的大纲如图 2 所示:第 2 节回顾了与图机器学习和基础模型技术相关的工作。第 3 节介绍了图上的深度学习方法,重点关注各种 GNN 模型和自监督方法。随后,调查深入探讨了 LLMs 如何在第 4 节中增强 Graph ML,以及图如何在第 5 节中被采用来增强 LLMs。最后,第 6 节和第 7 节分别讨论了各种应用和图 ML 在 LLMs 时代潜在的未来方向。我们的主要贡献可以总结如下:
我们详细描述了从早期图学习方法到 LLMs 时代最新 GFMs 的演变;
我们提供了对当前 LLMs 增强 Graph ML 方法的全面分析,突出了它们的优势和局限性,并提供了系统的分类;
我们彻底调查了图结构解决 LLMs 局限性的潜力;
我们探讨了 LLMs 时代图 ML 的应用和潜在的未来方向,并讨论了各个领域中的研究和实际应用。
与我们的调查同时,Wei 等人 [36] 回顾了图学习的发展。Zhang 等人 [37] 提供了对大型图模型的前瞻性回顾。Jin 等人 [38] 和 Li 等人 [39] 分别回顾了在图上预训练语言模型(特别是 LLMs)的不同技术和应用到不同类型的图。Liu 等人 [40] 根据流程回顾了图基础模型。Mao 等人 [18] 专注于基本原理,并讨论了 GFMs 的潜力。与这些同期调查不同,我们的调查提供了更全面回顾,并具有以下区别:(1) 我们对图机器学习的发展进行了更系统的回顾,并进一步探索了 LLMs 对 Graph ML 向 GFMs 的影响;(2) 我们对 LLMs 时代图 ML 的最新进展进行了更全面和细粒度的分类;(3) 我们深入研究了图 ML 的局限性,并从 LLM 的角度提供了如何克服这些局限性的见解;(4) 我们进一步探索了图如何增强 LLMs;以及 (5) 我们更全面地总结了广泛的应用,并就挑战和未来方向进行了更前瞻性的讨论。
2 相关工作
在本节中,我们简要回顾了图机器学习和基础模型技术领域的一些相关工作。
2.1 图机器学习
作为人工智能中最活跃的领域之一,图学习因其能够对表示为图的数据中的复杂关系和结构进行建模而受到广泛关注。如今,它已广泛应用于社交网络分析、蛋白质检测、推荐系统等各个应用中。图学习的初始阶段通常使用随机游走,这是探索图结构的基础方法。这种技术涉及在图中从一个节点移动到另一个节点的随机过程,对于理解网络中的节点连通性和影响力至关重要。在随机游走的基础上,图嵌入方法旨在将节点(或边)表示为保留图拓扑和节点关系的低维向量。代表性方法如 LINE [46]、DeepWalk [47] 和 Node2Vec [48] 利用随机游走学习节点表示,有效地捕获局部结构和社区信息。由于其出色的表示学习和建模能力,由深度学习支持的图神经网络(GNNs)在图学习中带来了显著的进步。例如,GCNs [49] 引入了卷积操作到图数据中,使每个节点能够有效地聚合邻居信息,从而增强节点表示学习。GraphSAGE [50] 学习一个函数来聚合来自节点局部邻域的信息,在归纳设置中,允许为未见过的节点高效地生成嵌入。GAT [51] 通过整合注意力机制进一步推进了 GNNs,为邻域中的节点分配不同的权重,从而提高模型关注重要节点的能力。受到变换器 [52] 在 NLP 和 CV 中成功的启发,几项研究 [53]–[57] 采用自注意力机制到图数据中,提供了对图结构和交互的更全局视角。最近的工作 [58]–[62] 进一步利用变换器架构来增强图数据建模。例如,GraphFormer [58] 在变换器的每一层中整合 GNN,使文本和图信息得以同时考虑。变换器在 LLMs 中的进步催生了图学习。最近的工作 [20]、[21]、[26]、[63] 应用了这些先进的语言模型技术,如 LLaMA [23] 或 ChatGPT 到图数据中,从而产生了能够以类似于自然语言处理的方式理解和处理图结构的模型。一种典型的方法,GraphGPT [22],将图数据标记化以插入 LLMs(即 Vicuna [64] 和 LLaMA [23]),从而提供了强大的泛化能力。GLEM [65] 进一步将图模型和 LLMs,特别是 DeBERTa [66],集成到变分期望最大化(EM)框架中。它在 E 步和 M 步中交替更新 LLM 和 GNN,从而在下游任务中高效地扩展并提高效果。
2.2 基础模型 (FMs)
基础模型 (FMs) 代表了人工智能领域的一个重大突破,其特点是能够在大规模数据集上进行广泛的预训练,并适应各种下游任务。这些模型以其在大规模数据集上的广泛预训练和对广泛下游任务的适应性而著称。值得注意的是,FMs 不局限于单一领域,而是可以在自然语言 [14]、[15]、视觉 [67]、[68] 和图领域 [18]、[40] 中找到,是一个有希望的研究方向。在视觉领域,视觉基础模型 (VFMs) 取得了显著的成功,对图像识别、目标检测和场景理解等领域产生了重大影响。具体来说,VFMs 得益于在广泛和多样化的图像数据集上的预训练,使它们能够学习复杂的模式和特征。例如,DALL-E [69] 和 CLIP [67] 等模型利用自监督学习来理解和基于文本描述生成图像,展示了显著的跨模态理解能力。最近的视觉 ChatGPT [68] 将 ChatGPT 与一系列视觉基础模型 (VFMs) 集成,使其能够执行各种复杂的视觉任务。这些 VFMs 允许模型从更广泛的视觉数据中学习,从而提高它们的泛化能力和鲁棒性。在自然语言处理(NLP)领域,大型语言模型(LLMs)如 ChatGPT 和 LLaMA 也彻底改变了该领域 [70]。由于其庞大的规模,LLMs 在使用大量文本数据集训练数十亿参数时表现出色,使它们在理解和生成自然语言方面表现出色。预训练语言模型的格局是多样化的,例如 GPT(Generative Pre-trained Transformer)[14]、BERT(Bidirectional Encoder Representations from Transformers)[15] 和 T5(Text-To-Text Transfer Transformer)[24]。这些模型大致可以分为三类:仅编码器、仅解码器和编码器-解码器模型。仅编码器模型,如 BERT,专门用于理解和解释语言。相比之下,像 GPT 这样的仅解码器模型在生成连贯且与上下文相关的文本方面表现出色。像 T5 这样的编码器-解码器模型结合了这两种能力,有效地执行各种 NLP 任务,从翻译到摘要。作为一个仅编码器模型,BERT 通过其创新的双向注意力机制在 NLP 中引入了一种范式,该机制同时从两个方向分析文本,与其前身(如仅单向处理文本的变换器)不同,无论是从左到右还是从右到左。这一特性使 BERT 能够获得全面上下文理解,显著提高了其对语言细微差别的理解。另一方面,像 GPT 这样的仅解码器模型,包括 ChatGPT 等变体,使用单向自注意力机制。这种设计使它们在预测序列中的后续单词方面特别有效,因此在文本完成、创意写作和代码生成等任务中表现出色。此外,作为一个编码器-解码器模型,T5 独特地将各种 NLP 任务转化为文本生成问题。例如,它将情感分析从分类任务重新框架化为文本生成任务,其中输入如“情感:今天是晴天”会促使 T5 生成一个输出,如“正面”。这种文本到文本的方法强调了 T5 在不同语言任务中的多功能性和适应性。LLMs 的发展见证了像 GPT-3 [92]、LaMDA [93]、PaLM [94] 和 Vicuna [64] 这样的先进模型的出现。这些模型代表了 NLP 中的重大进步,以其在理解和生成复杂、精细语言方面的增强能力而著称。它们的训练方法通常更加复杂,涉及更大的数据集和更强大的计算资源。这种扩展导致了前所未有的语言理解和生成能力,表现出诸如上下文学习(ICL)、适应性和灵活性等涌现属性。此外,最近的进展表明 LLMs 与其他模型的成功整合,如推荐系统 [17]、强化学习(RL)[95]、GNNs [25]、[96]–[98]。这种整合使 LLMs 能够应对传统和新的挑战,为应用提出了潜在的途径。LLMs 在化学 [99]、[100]、教育 [101]、[102] 和金融 [103]、[104] 等不同领域中找到了应用,它们从数据分析到个性化学习等各种任务做出了贡献。特别是,LLMs 在图任务,如图分类和链接预测中表现出色,展示了它们的多功能性和广泛的适用性。具体来说,Simteg [25]、GraD [97]、Graph-Toolformer [96] 和 Graphologue [98] 等几项研究显著推进了图学习。这些模型利用 LLMs 进行文本图学习、图感知蒸馏和图推理,展示了 LLMs 在增强对复杂图结构的理解和交互方面的潜力。尽管 FMs 革新了视觉和 NLP 领域,但图基础模型(GFMs)的发展仍处于初期阶段。鉴于该领域的快速发展和重大潜力,有必要继续探索和发展先进技术,进一步推动图 ML 向 GFMs 的发展。
3 图上的深度学习
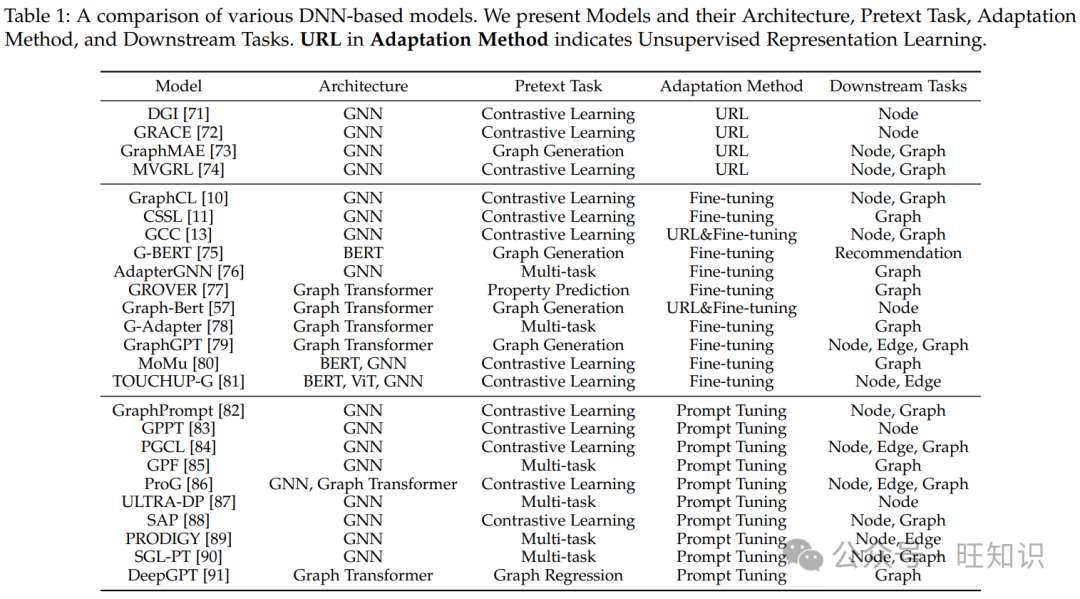
随着深度神经网络(DNNs)的快速发展,用于表示学习的图结构和节点属性建模的 GNN 技术已被广泛探索,并成为图 ML 的关键技术之一。虽然传统的 GNN 在各种图任务中表现出熟练,但它们仍遇到几个挑战,如可扩展性、对未见数据的泛化以及在捕获复杂图结构方面的有限能力。为了克服这些限制,许多人努力通过自监督范式改进 GNN。因此,为了全面回顾这些方法,在本节中,我们首先介绍骨干架构,包括基于 GNN 的模型和基于图变换器的模型。之后,我们将探讨自监督图 ML 模型的两个重要方面:图预训练任务和下游适应。请注意,这些方法的全面总结在表 1 中呈现。
3.1 骨干架构
作为人工智能(AI)社区中最活跃的领域之一,已经提出了各种 GNN 方法来解决各种任务。这些模型的强大能力在很大程度上依赖于其骨干架构的发展。因此,在本小节中,我们关注两种广泛使用的架构:基于邻域聚合的模型和基于图变换器的模型。
3.1.1 基于邻域聚合的模型
基于邻域聚合的模型是最流行的图学习架构,已被广泛研究并应用于各种下游任务。这些模型基于消息传递机制运行,通过聚合邻居节点的特征以及它自己的特征来更新节点的表示。正式地,这个过程可以表示为:
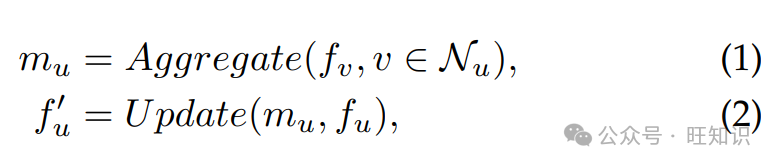
其中,对于每个节点 u,通过从其邻居节点的聚合函数生成消息 mu。随后,图信号 f 用消息更新。GCN 是一种典型的方法,旨在利用图结构和节点属性。该架构通过聚合邻居特征与节点自身的特征来更新节点表示。随着网络层数的增加,每一层都捕获越来越大的邻域。由于其效率和性能,GCN [49] 已被多种方法广泛应用,如 CSSL [11] 和 PRO DIGY [89]。GraphSAGE [50] 是另一个著名的基于邻域聚合的模型。由于其归纳范式,GraphSAGE 可以轻松推广到未见过的节点或图,使其被多项研究如 PinSage [106] 用于归纳学习。此外,几项研究 [73]、[86]、[89] 将图注意力网络(GATs)[51] 作为骨干架构。GATs 将注意力机制整合到 GNNs 中,为邻域中的节点分配可变权重,从而专注于输入图的最重要部分,以改进节点表示。作为 GNNs 家族中的另一个重要模型,图同构网络(GIN)[107] 也因其强大的表示能力而被广泛使用 [10]、[13]、[82]、[90],由于其独特的架构保证了与 Weisfeiler Lehman 同构测试等价的表达能力,使其成为许多结构密集型任务的首选骨干模型。尽管这些模型被广泛采用来解决图任务,但它们仍然存在一些固有的局限性,例如过度平滑和缺乏泛化能力。此外,参数数量较少也限制了作为骨干模型的建模能力,以服务于多个数据集和任务。
3.1.2 基于图变换器的模型
尽管基于邻域聚合的 GNN 模型在处理图结构数据方面表现出色,但它们存在一些局限性。这些模型面临的一个重大挑战是,由于依赖于局部邻域信息,以及在捕获图中的长距离依赖方面的有限能力,因此难以处理大型图 [61]、[108]、[109]。为了克服这些问题,受到变换器模型在各种 NLP 任务中成功的启发,提出了基于图变换器的模型 [54]、[59]、[61]。这些模型利用自注意力机制来适应性地捕获局部和全局图结构,允许模型在不过度平滑的情况下堆叠多层。由于较低的归纳偏差,基于图变换器的模型可以从数据中学习结构模式,而不是仅依赖于图结构。此外,变换器在 CV 和 NLP 中展示了出色的扩展行为,表明随着更多的数据和参数,它们的性能可以不断提高。基于图变换器的模型已被广泛应用于各种任务的骨干架构 [57]、[77]、[78]、[91]、[110]。例如,Graph-Bert [57] 使用变换器在图数据集上进行预训练,进行特征和边重建任务,然后微调以进行各种下游任务。同样,GROVER [77] 引入了一个专为大规模分子数据设计的自监督基于图变换器的模型。它在广泛的分子数据集上进行预训练,然后微调以进行特定下游任务。GraphGPT [79] 使用(半)欧拉路径将图转换为令牌序列,然后将序列输入变换器。具体来说,它构建了一个数据集特定的词汇表,使得每个节点都可以对应一个唯一的节点 ID。尽管基于图变换器的模型可以在某种程度上解决传统 GNNs 的局限性,但它们也面临几个挑战。其中一个挑战是由自注意力引起的二次复杂度,这对于大型图特别成问题。此外,在将图序列化时,还可能丢失有关原始图结构的一些信息。
3.2 图上的自监督学习
为了使 GNNs 适应各种图任务,提出并广泛研究了许多自监督学习方法。这些方法使 GNNs 能够从预训练任务中学习图表示,并将它们转移到各种下游任务中,如节点分类、图分类和链接预测。因此,在本小节中,我们将从预训练任务和下游适应两个方面介绍图自监督学习方法。
3.2.1 图预训练任务
图对比学习旨在通过对比相似和不相似的图数据对来学习增强表示,有效地识别细微的关系和结构模式。我们可以从两个角度回顾图对比学习:图增强和对比的规模。通常,图增强可以分为两种类型:1)特征扰动和 2)拓扑扰动。它们假设在特征或结构空间中的微小变化不会改变语义。特征扰动涉及扰动图中节点的特征。例如,GRACE [72] 随机掩盖节点特征以学习更鲁棒的表示。另一方面,拓扑扰动主要涉及修改图的结构。一个典型的例子是 CSSL [11],它采用如边扰动或节点删除等策略来采用图-图级别的对比,从而增强表示的鲁棒性。关于对比的规模,方法可以分为节点级别和图级别。例如,GRACE [72] 计算节点级别嵌入之间的相似性以学习区分节点表示。GCC [13] 也在节点级别工作,但通过采样节点的邻居来获得子图(正对)并将其与随机选择的非上下文子图(负对)进行对比,从而学习局部结构模式。相比之下,DGI [71] 对比节点级别嵌入和图级别嵌入以捕获全局图结构。GraphCL [10] 采取了不同的方法,通过实现图到图级别的对比,从而学习鲁棒的表示。用于预训练的规模对下游性能有巨大影响。当采用对比学习作为预训练任务时,一个关键挑战是如何设计目标,使学习到的嵌入能够适应不同规模的下游任务。图生成方法旨在学习图数据的分布,以实现图的生成或重建。与在 CV 中预测掩蔽图像块的模型不同,在 NLP 中预测序列中的下一个标记,图数据由于其相互连接的特性而呈现出独特的挑战。因此,图生成方法通常在特征或结构空间上工作。特征生成方法专注于掩盖一个或一组节点的特征,然后训练模型恢复被掩盖的特征。例如,GraphMAE [73] 利用掩蔽自编码器框架来基于它们的上下文重建被掩盖的图部分,有效地捕获底层节点语义及其连接模式。或者,结构生成方法集中在训练模型恢复图结构上。方法 GraphGPT [79] 将图编码为令牌序列,然后使用变换器解码器预测序列中的下一个令牌以恢复图的连通性。此外,Graph-Bert [57] 在训练时使用节点属性恢复和图结构恢复任务,以确保模型在捕获局部节点属性信息的同时保持对图结构的全局视图。图属性预测方法从图中固有的节点级、边级和图级属性中获得指导,这些属性在图中自然存在。这些方法遵循与监督学习类似的训练方法,因为两者都使用“样本-标签”对进行训练。关键区别在于标签的来源:在监督学习中,标签由人类专家手动注释,这在实际情况中可能成本高昂,而在基于属性的学习中,标签是从图使用某些启发式或算法自动生成的。例如,GROVER [77] 利用专业软件提取图模式的信息作为分类的标签。类似地,[111] 利用图的统计属性进行图自监督学习。
3.2.2 下游适应
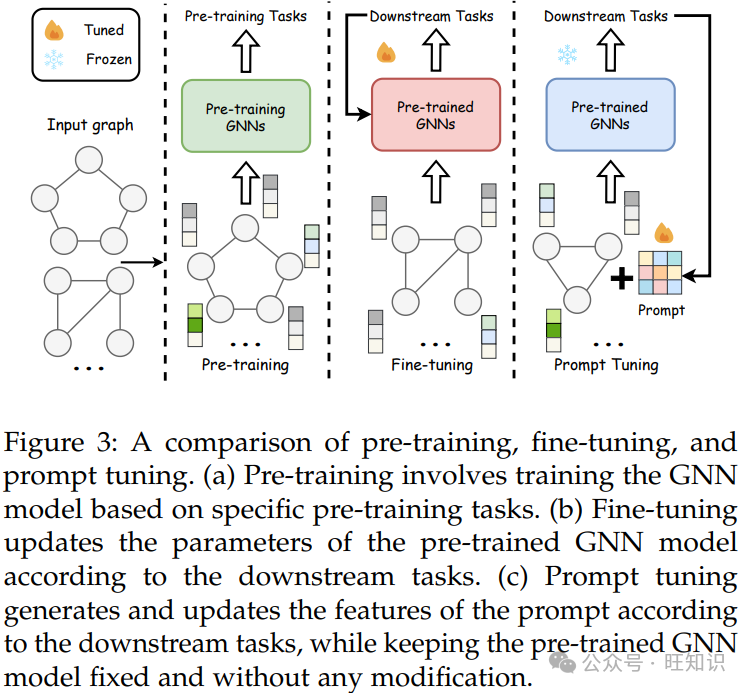
无监督表示学习(URL)是一种常见的方法,因为现实世界中标记数据的稀缺性 [71]–[74]。在 URL 中,预训练的图编码器被冻结,只有在下游调整期间学习特定任务层。然后,学习到的表示直接输入到解码器中。这种模式允许 URL 高效地应用于下游任务。例如,DGI [71] 训练一个编码器模型来学习图结构内的节点表示。然后,这些节点表示可以用于下游任务。然而,由于预训练任务和下游任务之间的差距,URL 也可能导致次优性能。微调是适应预训练模型到某个下游任务的默认方法。如图 3 所示,它在预训练模型的顶部添加一个随机初始化的任务头(例如,分类器),在微调期间,背景模型和头部共同训练 [10]、[11]、[57]。与 URL 相比,微调提供了更多的灵活性,因为它允许在背景参数中进行更改,并且可以选择要调整的层,同时保持其他层不变。此外,最近的研究 [10]、[76]、[78] 进一步探索了超越简单微调的先进图微调方法。例如,AdapterGNN [76] 在消息传递前后并行引入两个可训练的适配器。它在微调期间冻结 GNN 模型,只调整适配器,实现了参数高效的微调,对下游性能的影响最小。提示调整:“预训练 & 微调” 在适应预训练模型到特定下游任务时很普遍,但它忽略了预训练和下游任务之间的差距,可能限制了泛化能力。此外,为不同任务进行微调也会导致显著的时间和计算成本。受到 NLP 中最近进展的启发,几种方法 [82]–[88]、[90]、[91] 提出了引入提示以将预训练模型适应特定任务的潜力,如图 3 所示。具体来说,提示调整首先将下游任务与预训练任务统一为同一范式,然后引入可学习的提示进行调整。例如,GPPT [83] 首先将节点分类重新框架化为链接预测。GraphPrompt [82] 进一步将图分类扩展为链接预测。另一方面,Prog [86] 将所有下游任务统一为子图分类。插入的提示包括向量 [82]、[83]、[85]、节点 [90] 和子图 [86]。通过插入这些提示,可以以更贴近下游任务需求的方式利用预训练参数。
4 LLMs 用于图模型
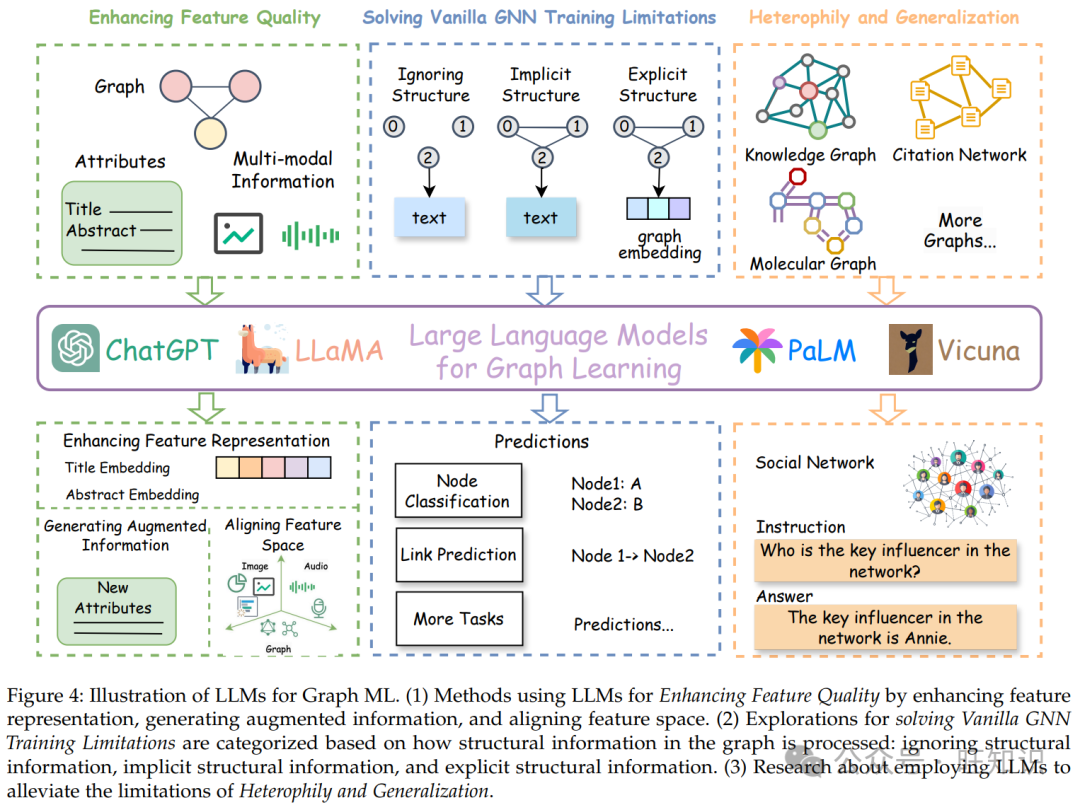
尽管基于 GNNs 的图 ML 具有巨大潜力,但它也存在固有的局限性。首先,传统的 GNN 模型通常需要标记数据进行监督,而获取这些注释在时间和成本上可能非常耗费资源。其次,现实世界的图经常包含丰富的文本信息,这些信息对于下游任务至关重要。然而,GNNs 通常依赖于浅层文本嵌入进行语义提取,从而限制了它们捕获复杂语义和文本特征的能力。此外,图的多样性为 GNN 模型在不同领域和任务中的泛化提出了挑战。最近,LLMs 在处理自然语言方面取得了显著的成功,具有以下特点:(1) 进行零次/少次预测,(2) 提供统一的特征空间。这些能力为解决图 ML 和 GFMs 面临的上述挑战提供了潜在的解决方案。因此,本节旨在研究当前 LLMs 如何有助于推动图 ML 向 GFMs 的进展,同时检查它们当前的局限性,如图 4 所示。
4.1 提高特征质量
图包含多样化的属性信息,涵盖文本、图像、音频和其他多模态模式。这些属性的语义在一系列下游任务中起着至关重要的作用。与早期的预训练模型相比,LLMs 因其庞大的参数量和在广泛数据集上的训练而脱颖而出,赋予了它们丰富的开放世界知识。因此,研究人员正在探索利用 LLMs 来改善特征质量和对齐特征空间的可能性。本节深入研究旨在利用 LLMs 实现这些目标的研究努力。
4.1.1 提高特征表示
研究人员利用 LLMs 强大的语言理解能力,为文本属性生成比传统浅层文本嵌入更好的表示 [26]、[112]、[113]。例如,Chen 等人 [26] 将 LLMs 作为文本编码器,GNN 模型作为预测器,验证了 LLMs 作为节点分类任务增强器的有效性。在 LKPNR [112] 中,LK-Aug 新闻编码器通过将新闻文本中的 LLM 嵌入与实体嵌入连接起来,增强了新闻推荐系统,以获得丰富的新闻表示。一些研究人员探索微调 LLMs 以获得更适合下游图任务的文本表示。SimTeG [25] 将节点分类和链接预测任务视为文本分类和文本相似性任务,使用 LoRA [146] 在 TAG 数据集上对 PLMs 进行微调。然后,使用微调后的 PLMs 为文本属性生成嵌入,随后进行 GNN 训练以进行下游任务。
4.1.2 生成增强信息
几项研究调查了利用 LLMs 的生成能力和通用知识从原始文本属性生成增强信息的可能性。TAPE [114] 首先利用 LLM 生成潜在的节点标签和解释,将文本属性(如标题和摘要)作为输入。这些由 LLM 生成的标签和解释被视为增强属性。随后,这些增强属性由微调的语言模型(LM)编码,并由 GNN 模型处理,该模型整合了图结构以进行最终预测。
与 TAPE 相反,KEA [26] 并不直接使用 LLM 预测节点标签。相反,LLM 提取文本属性中提到的术语并提供这些术语的详细描述。在分子属性预测领域,LLM4Mol [63] 和 GPT-MolBERTa [118] 采用了类似的方法,其中 LLMs 为输入的简化分子输入线性条目系统(SMILES)表示生成解释作为增强属性。在推荐系统领域,几种方法利用 LLMs 增强用户和项目文本属性。LLM-Rec [117] 使 LLMs 能够通过在提示中明确说明推荐意图来产生更详细的项目描述。RLMRec [115] 探索使用 LLM 增强用户偏好。具体来说,LLM 接收用户和项目信息作为输入,生成用户偏好、项目可能吸引的潜在用户类型以及推理过程。LLMRec [116] 采用类似的方法来增强推荐系统中的项目和用户属性。例如,基于历史行为信息,LLM 输出用户配置文件,如年龄、性别、国家、语言以及喜欢或不喜欢的类型。对于项目属性,以电影信息(如标题)作为输入,LLM 生成输出,如电影导演、国家和语言。
除了生成增强的文本属性外,研究人员还利用 LLMs 通过生成或完善节点和边来增强图拓扑结构。在 ENG [119] 中,LLM 被用来为每个节点类别生成新节点及其相应的文本属性。为了将生成的节点整合到原始图中,作者训练了一个边缘预测器,使用原始数据集中的关系作为监督信号。Sun 等人 [120] 利用 LLMs 完善图结构。具体来说,他们让 LLMs 通过预测节点属性之间的语义相似性来删除不可靠的边缘。此外,他们利用 LLMs 生成的伪标签帮助 GNN 学习适当的边缘权重。
4.1.3 对齐特征空间
在现实世界场景中,不同领域中的图的文本属性表现出相当的多样性。此外,除了文本模态属性外,图可能包含各种其他模态属性。直接使用预训练模型(PMs)对跨领域和多模态特征进行编码可能不会产生令人满意的结果。因此,利用 LLMs 对齐特征空间并提供更好的表示。TouchUp-G [81] 引入了一种以图为中心的微调策略,旨在增强与图相关任务的多模态特征。首先,他们提出了一种新颖的特征同亲度量,用于量化节点特征与图结构之间的一致性。在此基础上,作者设计了一个结构感知损失函数,通过最小化特征与图之间的差异来优化 PM。文献[121]介绍了用于不同领域图分类任务的统一框架 OFA。OFA 收集了涵盖不同领域的九个文本属性图数据集,并用自然语言表示节点和关系。然后采用 LLM 将这些跨域图信息嵌入到同一个嵌入空间中。此外,OFA 还提出了一种图提示范式,即在原始输入图中加入包含下游任务信息的提示图,使 GNN 模型能够根据提示图自适应地执行不同的任务。
4.2 解决传统 GNN 训练限制
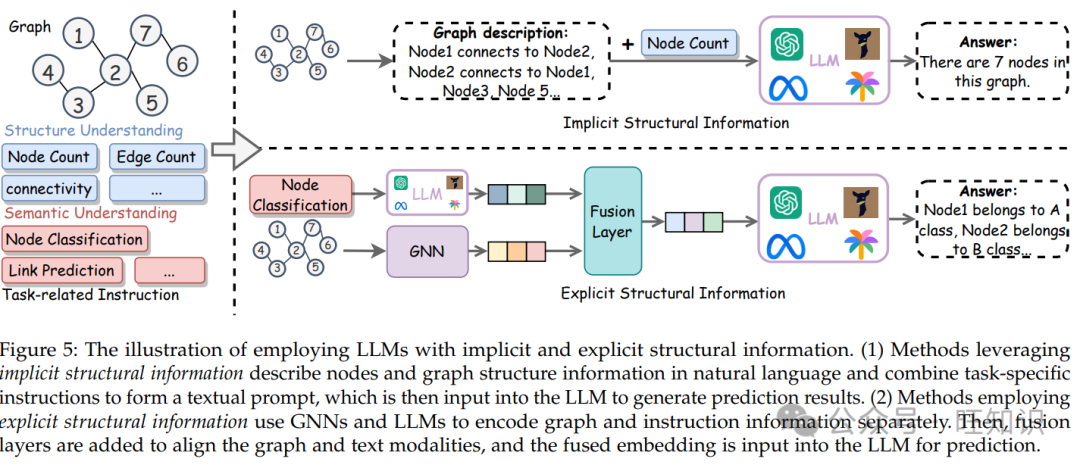
传统的 GNN 训练依赖于标记数据。然而,获取高质量的标记数据往往伴随着大量的时间和成本。与 GNN 相比,LLMs 展示了强大的零样本/少样本能力,并拥有广泛的开放世界知识。这一独特的特性使 LLMs 能够直接利用节点信息进行预测,而不依赖于大量的标注数据。因此,研究人员探索使用 LLMs 生成注释或预测,减轻了图机器学习中对人类监督信号的依赖。根据图数据中结构信息的处理方式,我们将这些方法分为以下三类:
忽略结构信息:仅使用节点属性构建文本提示,忽略邻接标签和关系。
隐式结构信息:用自然语言描述邻接信息和图拓扑结构;
显式结构信息:使用 GNN 模型对图结构进行编码。
4.2.1 忽略结构信息 在文献 [122] 中探索了 LLMs 在不使用结构信息的情况下解决图任务的有效性。在引文网络中,他们使用文章的标题和摘要构建提示,并指导 LLM 预测文章的类别。由于这种范式没有结合图的结构信息,LLM 实际执行的任务是文本分类而不是与图相关的任务。
4.2.2 隐式结构信息 研究人员通过用自然语言描述图结构来隐式地利用结构信息以解决图任务。例如,Hu 等人 [122] 提出了两种使用结构信息的方法。第一种方法涉及将所有相邻节点的数据直接输入 LLM,而第二种方法使用基于检索的提示引导 LLM 仅关注相关的邻居数据。类似地,Huang 等人 [129] 使用 LLM 为相邻节点分配分数,然后选择高分节点作为结构信息。NLGraph [123] 引入了一种构建图的提示策略,以提高 LLM 对图结构的理解。该策略涉及在提供图数据描述后附加“让我们首先用节点和边构建一个图。” [20] 提出了 InstructGLM,它使用自然语言进行图描述,并通过指令调整对 FlanT5 进行微调。他们通过组合四个配置参数生成了一组 31 个提示:任务类型、包含节点特征、最大跳数和使用节点连接。值得注意的是,最大跳数和节点连接隐式地向 LLM 传达了图结构信息。GraphEdit [133] 利用 LLM 理解图结构,并通过删除噪声边和揭示隐式节点连接来完善它。具体来说,它使用边缘预测器为每个节点识别前 k 个候选边缘,然后将这些候选边缘和图的原始边缘一起输入 LLM。LLM 被提示决定哪些边缘应该整合到最终的图结构中。除了使用自然语言表达,一些研究人员还利用结构化语言来描述图。例如,GPT4Graph [21] 使用图形建模语言 [147] 和图形标记语言 [148] 以 XML 格式表示图结构。GraphText [28] 为每个图构建了一个图语法树,包含节点属性和关系信息。通过遍历这棵树,可以生成结构化的图-文本序列。GraphText 的优势在于能够通过构建各种图语法树来整合 GNNs 的典型归纳偏差。
4.2.3 显式结构信息 尽管用自然语言隐式描述结构已经取得了初步成功,但这些方法仍然面临某些局限性。首先,由于输入长度的限制,LLMs 只能获得局部结构信息,冗长的内容可能会削弱它们的推理 [149] 和指令遵循能力 [26]。其次,对于不同的任务和数据集,通常需要大量的提示工程工作。在一个数据集上表现良好的提示可能无法有效地推广到其他数据集,导致缺乏鲁棒性。因此,研究人员调查了如何明确表示图结构,通常包括三个基本模块:编码模块、融合模块和 LLM 模块。更具体地说,编码模块的目标是处理图结构和文本信息,生成图嵌入和文本嵌入。然后,融合模块将这两个嵌入作为输入,产生一个模态融合嵌入。最后,包含图信息和指令信息的模态融合嵌入被输入到 LLM 中以获得最终答案。鉴于研究重点是 LLM 如何显式利用图结构信息,我们将详细探讨各种研究的编码和融合模块,而不是主要关注 LLM 模型本身。
编码模块。编码模块负责图和文本编码,我们将分别为每个模块提供总结。
图编码。预训练的 GNN 模型通常用于图编码。例如,GIT-Mol [139] 采用预训练的 MoMu 模型 [80] 中的 GIN 模型来编码分子图。KoPA [137] 使用预训练的 RotateE 模型来获取知识图中实体和关系嵌入。此外,GIMLET [138] 提出了一个统一的图-文本模型,无需额外的图编码模块。特别是,GIMLET 提出了一种基于距离的联合位置嵌入方法,利用最短图距离来表示图节点之间的相对位置,使变换器编码器能够编码图和文本。GraphToken [144] 评估了一系列 GNN 模型作为图编码器,包括 GCN、MPNN [105]、GIN、Graph Transformer、HGT [56] 等。
文本编码。由于 LLMs 在理解文本信息方面的巨大能力,大多数现有方法,如 ProteinChat [141] 和 DrugChat [136],直接将 LLMs 用作文本编码器。在 GraphLLM [134] 中,利用 LLM 的分词器和冻结的嵌入表来获取节点文本属性的表示,与下游冻结的 LLM 对齐。
融合模块。融合模块的目标是将图和文本模态对齐,生成一个融合嵌入作为 LLM 的输入。为了实现这一目标,一个直接的解决方案是设计一个线性投影层,将 GNN 生成的图表示直接转换为 LLM 兼容的软提示向量 [136]、[137]、[140]。此外,受到 BLIP2 的 Q-Former [150]、[139] 的启发,提出了 GIT-Former,它使用自注意力和交叉注意力机制将图、图像和文本与目标文本模态对齐。除了上述方法,G-Retriever 被提出来整合显式和隐式的结构信息 [143]。具体来说,GAT 被用来编码图结构,同时通过文本提示来表示节点和关系细节。为了适应具有更大规模的真实世界图,G-Retriever 引入了一个专门设计的 RAG 模块,用于检索与用户查询相关的子图。
4.3 异质性和泛化
尽管图神经网络(GNNs)在图任务中取得了令人瞩目的成绩,但它们也存在一些不足之处。一个显著的缺陷是邻居信息聚合机制的不足,尤其是在处理异构图时。当相邻节点缺乏相似性时,GNN的性能会显著下降。此外,GNN在面对分布外(OOD)泛化时也面临挑战,导致模型在训练数据之外的分布上的性能下降。这一挑战在实际应用中尤为突出,主要原因在于,包含所有可能的图结构在有限的训练数据中是非常困难的。因此,当GNN对未见过的图结构进行推断时,它们的性能可能会大幅下降。这种泛化能力的降低使得GNN在面对现实世界场景中不断演变的图数据时变得相对脆弱。例如,GNN可能在处理社交网络中新出现的社会关系时遇到困难。LLMs已被用来缓解上述限制。特别是,GraphText [28]通过将节点属性和关系封装在图语法树中,有效地解耦了深度和广度,与GNN基线相比,在异构图上取得了更好的结果。Chen等人[26]研究了LLM处理OOD泛化场景的能力。他们使用GOOD[151]基准作为标准,结果表明LLM在解决OOD泛化问题上表现出色。OpenGraph[145]旨在解决跨不同领域的零样本图任务。在这个模型中,LLMs被用来在数据稀缺情况下生成合成图,从而增强OpenGraph的预训练过程。
5 图对 LLMs 的增强
LLMs 在各种领域中展示了令人印象深刻的语言生成和理解能力。然而,它们仍然面临几个紧迫的挑战,包括事实意识、幻觉、推理过程中的有限可解释性等。为了缓解这些问题,一种潜在的方法是利用知识图谱(KGs),它们以结构化格式存储高质量、人工策划的事实知识 [5]。最近的综述 [152]–[154] 总结了利用 KGs 增强 LLMs 的研究。Hu 等人 [152] 回顾了知识增强预训练语言模型在自然语言理解和自然语言生成中的研究。Agrawal 等人 [153] 系统地回顾了通过利用 KGs 在三个维度上减轻 LLMs 中的幻觉的研究:推理过程、学习算法和答案验证。Pan 等人 [154] 提供了 KGs 和 LLMs 整合的全面总结,从三个不同的角度:KG 增强的 LLMs、LLM 增强的 KGs 和相互加强的 LLMs 和 KGs,其中 LLMs 和 KGs 相互加强。在本节中,我们将深入探讨相关研究,探索使用 KGs 实现知识增强的语言模型预训练,减轻幻觉,并提高推理的可解释性。
5.1 KG 增强的 LLM 预训练
虽然 LLMs 在文本理解和生成方面表现出色,但它们仍可能产生语法正确但事实上错误的信息。在 LLM 预训练期间明确整合 KG 中的知识,有望增强 LLM 的学习能力和事实意识 [155]–[157]。在本小节中,我们将概述 KG 增强预训练语言模型(PLMs)的研究进展。虽然针对 LLMs 的 KG 增强预训练的工作有限,但关于 KG 增强 PLMs 的研究可以为 LLM 预训练提供见解。现有的 KG 增强预训练方法可以分为三个主要类别:修改输入数据、修改模型结构和修改预训练任务。
5.1.1 修改输入数据
一些研究人员通过修改输入数据来整合 KG 知识,同时保持模型架构不变。例如,Moiseev 等人 [158] 直接在由 KG 的事实三元组和自然语言文本组成的混合语料库上训练 PLMs。E-BERT [159] 将实体向量与 BERT 的词片向量空间对齐,保持结构并避免额外的预训练任务。KALM [160] 使用实体名称字典来识别句子中的实体,并使用实体标记器对它们进行标记。变换器的输入由原始词嵌入和实体嵌入组成。此外,K-BERT [161] 通过构建句子树将原始句子与相关三元组整合在一起,其中树干代表原始句子,分支代表三元组。为了将句子树转换为模型输入,K-BERT 在嵌入层中引入了硬位置索引和软位置索引,以区分原始标记和三元组标记。
5.1.2 修改模型结构
一些研究设计了知识特定的编码器或融合模块,以更好地将知识注入 PLMs。ERNIE [162] 引入了一个 K-Encoder 来注入知识到表示中。这涉及将标记嵌入和标记嵌入与实体嵌入的连接输入到融合层,以生成新的标记嵌入和实体嵌入。相比之下,CokeBERT [163] 通过在预训练期间整合来自 KGs 的关系信息来扩展这种方法。它引入了一个语义驱动的 GNN 模型,根据给定的文本为关系和实体分配相关分数。最后,它使用与 ERNIE 类似的 K-Encoder 将选定的关系和实体与文本融合。KLMO [164] 提出了一个知识聚合器,在预训练期间融合文本模态和知识图谱模态。为了在知识图谱嵌入中整合结构信息,KLMO 利用知识图谱注意力机制,该机制通过将可见性矩阵与常规注意力机制相结合,促进知识图谱中相邻实体和关系之间的交互。随后,令牌嵌入和上下文知识图谱嵌入通过实体级交叉知识图谱注意力进行聚合。一些研究避免修改语言模型的整体结构,而是引入额外的适配器来注入知识。为了保留 PLMs 中的原始知识,Wang 等人 [165] 提出了 KAdapter 作为一个可插拔模块来利用知识图谱知识。在预训练期间,K-Adapter 的参数被更新,而 PLMs 的参数保持冻结。KALA [166] 引入了一个知识条件特征调制层,其功能类似于适配器模块,通过使用检索到的知识表示来缩放和平移 PLMs 的中间隐藏表示。为了进一步控制适配器的激活水平,DAKI [167] 引入了一个基于注意力的知识控制器模块,这是一个带有额外线性层的适配器模块。
5.1.3 修改预训练任务
为了明确模拟文本和知识图谱知识之间的交互,提出了各种预训练任务。这方面的三条主要工作线包括实体中心任务 [162]、[168]–[171]、关系中心任务 [155],以及除此之外的任务。对于实体中心任务,ERNIE [162] 随机掩盖一些标记-实体对齐,并要求模型根据对齐的标记预测所有相应的实体。LUKE [168] 使用 Wikipedia 文章作为训练语料库,并将其中超链接视为实体注释,训练模型预测随机掩盖的实体。KILM [169] 也使用 Wikipedia 文章中的超链接作为实体。然而,它在相应实体后插入实体描述,任务是重建被掩盖的描述标记,而不是直接掩盖实体。除了预测掩盖的实体之外,GLM [170] 进一步引入了一个抑制干扰排名任务。该任务利用知识图谱中的负面实体样本作为干扰项,增强模型区分各种实体的能力。关系中心任务也通常在知识图谱增强的 PLMs 中使用。例如,JAKET [172] 提出了关系预测和实体类别预测任务,以增强知识建模。Dragon [173] 在知识图谱链接预测任务中进行预训练。给定一对文本-知识图谱,模型需要预测知识图谱中被掩盖的关系和句子中被掩盖的标记。ERICA [174] 引入了一种关系鉴别任务,旨在语义上区分两个关系之间的接近性。具体来说,它采用对比学习方法,鼓励属于相同关系的实体对的关系表示更接近。此外,还有一些创新的预训练任务用于知识图谱增强的预训练。KEPLER [175] 提出了一个知识嵌入任务,以增强 PLMs 的知识意识。具体来说,它使用 PLMs 来编码实体描述作为实体嵌入,并在同一个 PLM 上共同训练知识嵌入和掩蔽语言建模任务。ERNIE 2.0 [176] 从词、结构和语义角度构建了一系列连续的预训练任务。
5.2 KG 增强的 LLM 推理
知识图谱中的知识可以动态更新,而更新 LLMs 中的知识通常需要调整模型参数,这需要大量的计算资源和时间。因此,许多研究选择在 LLMs 的推理阶段使用知识图谱。LLMs 的“黑箱”特性在理解模型如何做出特定预测或生成特定文本方面带来了重大挑战。此外,LLMs 经常因生成虚假、错误或误导性内容而受到批评,通常称为幻觉 [29]、[30]、[177]。鉴于知识图谱的结构化和基于事实的特性,将其集成在推理阶段可以增强 LLM 答案的可解释性,从而相应减少幻觉。虽然有几种方法根据用户查询从知识图谱中提取相关三元组,并在提示中以自然语言描述这些三元组 [178]、[179],但这些方法忽略了知识图谱中固有的结构信息,仍然未能阐明 LLMs 如何得出其答案。因此,广泛的研究利用知识图谱来辅助 LLMs 进行推理,并生成中间信息,如关系路径、证据子图和理由,形成解释 LLM 决策过程和检查幻觉的基础 [32]、[34]、[35]、[180]–[182]。一些研究人员调查使 LLMs 能够直接在知识图谱上进行推理并生成关系路径以解释 LLM 的答案。每个步骤中的关系路径有助于提高答案的可解释性和推理过程的透明度。通过观察每个步骤所做的推理决策,可以识别和解决 LLMs 推理中产生的幻觉。RoG [32]、Knowledge Solver [181] 和 Keqing [33] 都使用关系路径作为 LLM 响应的解释。具体来说,给定知识图谱模式和用户查询,RoG [32] 引导 LLMs 使用文本提示如“请生成有助于回答问题的关系路径”来预测多个关系路径。随后,LLMs 根据有效关系路径的检索结果生成最终答案。与 RoG 方法不同,Knowledge Solver 方法 [181] 使 LLMs 能够逐步生成关系路径。Keqing [33] 最初将复杂问题分解为几个子问题,每个子问题都可以通过知识图谱上预定义的逻辑链来解决,然后 LLMs 将根据子问题的答案生成带有关系路径的最终答案。Mindmap [180] 使用明显的子图来解释 LLM 生成的答案,其中引入了基于路径和基于邻居的方法来获取几个明显的子图。Mindmap 中的 LLM 被提示合并这些明显的子图,使用合并的图生成最终答案。与之前的方法不同,这些方法涉及逐步检索知识并获得答案,KGR [34] 采取了不同的方法。最初,LLM 直接生成一个草稿答案。随后,它从这个答案中提取需要验证的声明,并检索知识图谱的信息来纠正带有幻觉的声明。基于修正后的声明,LLM 调整草稿答案以获得最终答案。上述研究使用关系路径或明显的图作为解释 LLM 决策过程和检查幻觉的基础。相比之下,一些研究探索使用固有可解释的模型而不是 LLMs 来进行最终预测。ChatGraph [183] 提出了一种创新方法,增强了 ChatGPT 的文本分类能力和可解释性。它利用 ChatGPT 从非结构化文本中提取三元组,随后基于这些三元组构建知识图谱。为了确保分类结果的可解释性,ChatGraph 避免直接使用 LLMs 进行预测。相反,它利用一个没有非线性激活函数的图模型,并在文本图上训练该模型以获得预测。给定一个问题和一系列可能的答案,XplainLLM [184] 提出了一个解释器模型来解释 LLMs 选择特定答案的原因,同时拒绝其他答案。具体来说,该方法涉及基于问题和候选答案中出现的实体构建一个元素图。随后,使用 GCN 模型为元素图中的每个节点分配注意力分数。显示出高注意力分数的节点被识别为原因元素,然后 LLMs 被提示基于这些选定的原因元素提供解释。
为了评估 LLMs 的透明度和可解释性,提出了各种基准。例如,Li 等人 [35] 引入了一项名为知识感知语言模型归因(KaLMA)的新任务,并开发了相应的基准数据集。该基准评估 LLM 从知识图谱派生引用信息以支持其答案的能力。KaLMA 还提供了一个自动评估,涵盖文本质量、引用质量和文本-引用对齐的答案方面。此外,XplainLLM [184] 引入了一个数据集,更好地理解 LLMs 从“为什么选择”和“为什么不选择”的角度做出决策。
6 应用
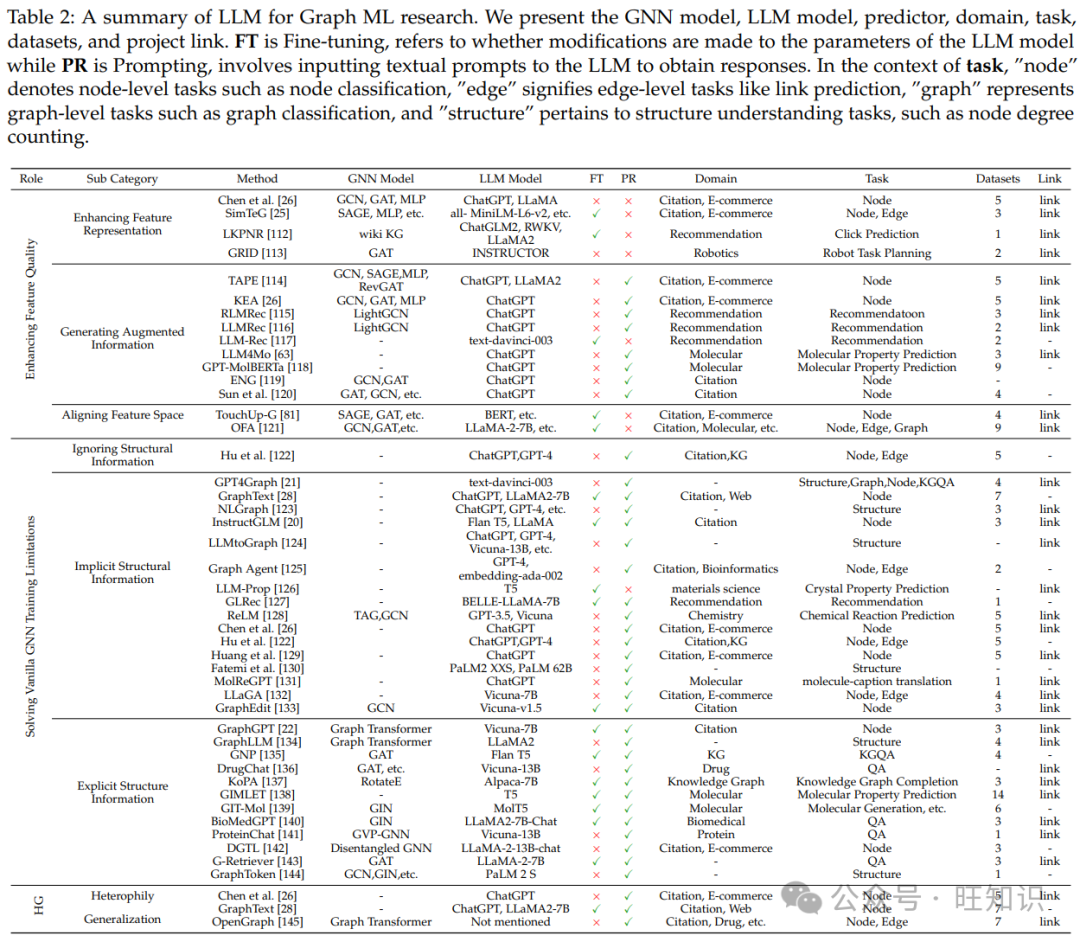
在本节中,我们将介绍实际应用,展示了 GFMs 和 LLMs 的潜力和价值。如表 2 所示,推荐系统、知识图谱、科学领域的 AI 和机器人任务规划成为最常见的领域。我们将全面总结每个应用。
6.1 推荐系统
推荐系统利用用户的历史行为来预测用户可能喜欢的项目 [185]–[187]。在推荐系统中,图扮演着至关重要的角色,其中项目可以被视为节点,协作行为如点击和购买可以被视为边。最近,越来越多的研究探索直接使用 LLMs 进行推荐 [188]–[191] 或利用 LLMs 增强图模型或数据集以进行推荐任务 [112]、[115]、[116]、[192]、[193]。对于直接使用 LLMs 作为推荐模型,liu 等人 [194] 构建特定任务的提示,评估 ChatGPT 在五个常见推荐任务上的表现,包括评分预测、序列推荐、直接推荐、解释生成和评论总结。Bao 等人 [195] 使用提示模板引导 LLM 根据用户的历史互动决定用户是否喜欢目标项目,并在LLM 上进行指令调整以提高其推荐能力。对于使用 LLMs 增强传统推荐方法或数据集,KAR [192] 利用 LLMs 生成项目的事实知识和用户偏好的推理依据;这些知识文本随后被编码为向量并整合到现有的推荐模型中。像 LLM-Rec [117]、RLMRec [115] 和 LLMRec [116] 这样的方法通过整合 LLM 生成的描述来丰富推荐数据集。相比之下,Wu 等人 [193] 利用 LLMs 来压缩推荐数据集,其中 LLMs 被用来为基于内容的推荐合成一个压缩数据集,旨在解决对大型数据集进行资源密集型训练的挑战。虽然前面讨论的方法探索了在某些推荐任务或领域中使用 LLMs,但一个新兴的研究方向旨在开发针对推荐的基金会模型。Tang 等人 [189] 提出了一个基于 LLM 的领域不可知的序列推荐框架。他们的方法整合了跨域的用户行为,利用 LLMs 基于多域历史互动和项目标题对用户行为进行建模。Hua 等人 [196] 试图解决由 LLM 偏见引入的推荐系统潜在的不公平性。他们提出了一种反事实公平提示方法,以开发一个无偏见的推荐基础模型。为了总结推荐基础模型领域的进展,Huang 等人 [197] 提供了现有方法的系统概述,将它们归类为三种主要类型:语言基础模型、个性化代理基础模型和多模态基础模型。
6.2 知识图谱
具有强大文本生成和语言理解能力的 LLMs 在知识图谱相关任务中找到了广泛的应用,包括知识图谱完成 [137]、[198]、[199]、知识图谱问答 [179]、[181]、[200]–[202]、知识图谱推理等。Meyer 等人 [204] 引入了 LLM-KGBench,这是一个框架,可以自动评估模型在知识图谱工程任务(如修复 Turtle 文件中的错误、事实提取和数据集生成)中的熟练程度。KGLLM [199] 提出以评估 LLMs 在知识图谱完成方面的性能,包括三元组分类、关系预测和链接预测任务。Kim 等人 [200] 提出 KG-GPT,使用 LLMs 进行知识图谱上的复杂推理任务。ChatKBQA [201] 为 LLMs 在知识库问答上引入了一个生成-检索框架。Wu 等人 [179] 提出了一个知识图谱增强的 LLM 框架,用于知识图谱问答,该框架涉及微调一个 LLM 以将结构化三元组转换为自由形式文本,增强 LLMs 对知识图谱数据的理解。LLMs 在知识图谱构建、完成和问答等任务中的成功应用为推进对知识图谱的理解和探索提供了有力支持。受到语言和视觉领域基础模型的启发,研究人员正在深入研究为知识图谱量身定制的基础模型。这些 GFMs 旨在概括知识图谱中的任何未见过的关联和实体。Galkin 等人 [205] 提出了 Ultra,通过利用关系之间的交互学习通用图表示。这项研究基于这样一个洞见:这些交互在不同数据集之间保持相似并且可以转移。
6.3 科学领域的 AI
AI 的快速发展导致越来越多的研究利用 AI 辅助科学研究 [206]、[207]。最近的研究已经应用 LLMs 和 GFMs 于科学目的,如药物发现、分子属性预测和材料设计。值得注意的是,这些应用包括涉及图结构数据的场景。分子图是一种表示分子的方式,其中节点代表原子,边代表原子之间的键。随着 LLMs 的出现,研究人员已经探索了它们在与分子图相关的任务中的性能。像 MolReGPT [131] 和 GPT-MolBERTa [118] 这样的方法采用了类似的将分子图转换为 SMILES 语言的文本描述的方法。他们基于 SMILES 数据创建提示,要求 LLM 提供有关官能团、形状、化学性质等的详细信息。然后将这些信息用于训练较小的 LM 进行分子属性预测。与直接使用 LLMs 进行预测的方法不同,ReLM [128] 首先使用 GNNs 预测高概率的候选产品,然后利用 LLMs 从这些候选中做出最终选择。除了上述研究,LLMs 还被进一步用于药物发现和材料设计。Bran 等人 [100] 提出了 ChemCrow,这是一个集成了 LLMs 和 18 个专业工具的化学代理,用于药物发现、材料设计和有机合成等多样化任务。InstructMol [208] 提出了一个两阶段框架,用于在药物发现中对齐语言和分子图模态。最初,该框架保持 LLM 和图编码器参数不变,专注于训练投影仪以对齐分子图表示。随后,在 LLM 上进行指令调整以解决药物发现任务。Zhao 等人 [209] 提出了 ChemDFM,这是化学领域的第一个对话基础模型。ChemDFM 在广泛的化学文献和一般数据上进行训练,表现出在各种化学任务(如分子识别、分子设计等)中的熟练程度。
6.4 机器人任务规划
机器人任务规划旨在将任务分解为一系列高级操作,由机器人逐步完成 [210]。在任务执行期间,机器人需要感知周围环境的信息,这些信息通常使用场景图表示。在场景图中,节点代表场景对象,如人和桌子,而边描述对象之间的空间或功能关系。使 LLMs 能够进行机器人任务规划的关键取决于如何以场景图的形式表示环境信息。许多研究探索了使用场景信息的文本描述,并为 LLMs 构建提示以生成任务计划。Chalvatzaki 等人 [211] 引入了 Graph2NL 映射表,使用相应的文本表达来表示具有不同数值范围的属性。例如,大于 5 的距离被表示为“远”,小于 3 的距离被表示为“可到达”。SayPlan [212] 将场景图以 JSON 形式描述为文本序列,迭代地调用 LLM 生成计划并允许自我纠正。Zhen 等人 [213] 提出了一个有效的提示模板,Think Net Prompt,以增强 LLM 在任务规划中的性能。与依赖于语言描述场景图信息的方法不同,GRID [113] 使用图变换器对场景图进行编码。它利用跨模态注意力对齐图模态和用户指令,最终通过解码器层输出动作标记。LLMs 的强大理解和推理能力在机器人任务规划中展示了巨大的潜力。然而,随着任务复杂性的增加,搜索空间急剧扩大,使用 LLMs 生成可行任务计划的效率面临着挑战。
7 未来方向
在本综述中,我们已经全面回顾了 LLMs 时代图应用和图 ML 的最新进展,这是一个图学习中的新兴领域。我们首先回顾了图 ML 的演变,然后深入探讨了 LLMs 增强图 ML 的各种方法。由于 LLMs 在各个领域都具有显著的能力,它们有很大的潜力将图 ML 增强为 GFMs。我们进一步探索了使用图增强 LLMs,突出了它们在增强 LLM 预训练和推理方面的能力。此外,我们展示了它们在分子发现、知识图谱和推荐系统等多样化应用中的潜力。尽管取得了成功,但这个领域仍在发展中,并为进一步的进展提供了许多机会。因此,我们进一步讨论了几个挑战和潜在的未来方向。总的来说,我们的综述旨在为研究人员和从业者提供系统和全面的回顾,激发这个有前途领域的未来探索。
8 结论
在本综述中,我们已经全面回顾了 LLMs 时代图应用和图 ML 的最新进展,这是一个图学习中的新兴领域。我们首先回顾了图 ML 的演变,然后深入探讨了 LLMs 增强图 ML 的各种方法。由于 LLMs 在各个领域都具有显著的能力,它们有很大的潜力将图 ML 增强为 GFMs。我们进一步探索了使用图增强 LLMs,突出了它们在增强 LLM 预训练和推理方面的能力。此外,我们展示了它们在分子发现、知识图谱和推荐系统等多样化应用中的潜力。尽管取得了成功,但这个领域仍在发展中,并为进一步的进展提供了许多机会。因此,我们进一步讨论了几个挑战和潜在的未来方向。总的来说,我们的综述旨在为研究人员和从业者提供系统和全面的回顾,激发这个有前途领域的未来探索。
参考资料
标题:Graph Machine Learning in the Era of Large Language Models (LLMs)
作者:Wenqi Fan, Shijie Wang, Jiani Huang, Zhikai Chen, Yu Song, Wenzhuo Tang, Haitao Mao, Hui Liu, Xiaorui Liu, Dawei Yin, Qing Li
单位:The Hong Kong Polytechnic University, Wuhan University, Michigan State University, North Carolina State University, Baidu Inc.
链接:https://arxiv.org/abs/2404.14928










