国内大模型的Token又降价了,或许Prompt的长度可以忽略价格因素,但Prompt上行的时间却是绕不过去的坎。在未来很长一段时间,开发各种AI应用的过程中,Prompt压缩始终是一件你终将要面对的事情。
图片由xiumaodalle生成
现有的压缩冗长提示的尝试导致了在压缩提示的可读性和可解释性方面明显低于标准的结果,对提示实用性具有不利影响。为了解决这个问题,沙特的阿卜杜拉国王科技大学和华南理工、蚂蚁集团、澳门大学、南开大学的研究者提出了PROMPT-SAW(PROMPT compresSion via Relation AWare graphs):利用可感知图进行文本提示压缩,这是一个有效的策略,同样的数据集在压缩率为33.0和56.7的情况下,性能优于基线模型12.3和13.7。
论文并没有给出Github或者任何代码,我尝试用论文给出的算法,用Python复现了结果,虽然有些不同,用同样的数据取得了大致类似的结果。
PROMPT-SAW的核心思想是利用图结构来表示提示词中的文本信息,这有助于分析提示词的关键方面。
通过图结构精炼信息,可以生成一个压缩后的提示词,在保持语义一致性的同时不会扭曲提示的最终性能或效用。具体来说,PROMPT-SAW首先使用一个内置学习提示来提示语言模型从原始提示文本构建图。对于任务相关场景,PROMPT-SAW遍历图以仅保留与任务相关的信息作为任务特定子图。对于任务无关场景,PROMPT-SAW使用图中连续信息元素之间的相似性分数来识别和删除冗余元素以获得所需的子图。
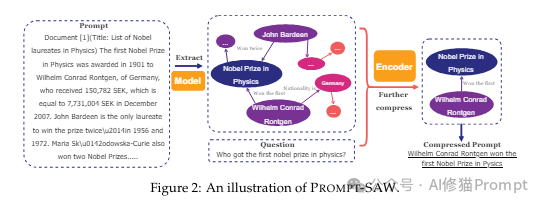
从论文中可以看出,PROMPT-SAW主要通过以下几个步骤实现对提示词的压缩
1. 提取(Extract):从原始的提示文本中提取出其中包含的实体(如人名、地名、组织机构名等)和实体间的关系,构建知识图谱。
2. 构建图模型(Model):将提取出的实体和关系组织成图模型的形式,图中的节点表示实体,边表示实体间的关系。
3. 根据具体场景进行图压缩:
(1)对于任务相关(Task-aware)的场景,遍历图模型,只保留与任务相关的信息作为任务特定子图。
(2)对于任务无关(Task-agnostic)的场景,计算图中相邻信息单元的相似度,去除冗余元素,得到所需子图。这里使用了二分搜索算法来寻找合适的相似度阈值。
4. 编码(Encoder):将压缩后的子图中包含的实体和关系进行自然语言编码,生成最终的压缩提示。
与LLMlingua等基于token级别压缩的方法相比,PROMPT-SAW通过将提示文本转化为知识图谱的形式进行分析和压缩,不仅可以在更高的语义层面上把握提示的关键信息,而且生成的压缩提示在可读性和解释性方面也更胜一筹。这从论文给出的案例对比中可以明显看出。
例如,对于"Who got the first nobel prize in physics"这个问题,LLMlingua的压缩提示是:"ITitle:List of Nobelates in The first PrizelWilhelmrad, ofwho receiveds2in en prize:won twoes forg01 theate women prizeertMayer(1963). As of 2017, the prize has been awarded",可读性很差,关键信息被掩盖。而PROMPT-SAW的压缩提示是:"Wilhelm Conrad Röntgen awarded first Nobel Prize in Physics 1901.William Lawrence Bragg won Nobel Prize in Physics 1915.Maria Goeppert-Mayer won Nobel Prize in Physics 1963",清晰地保留了问题答案所需的关键信息。
PROMPT-SAW利用知识图谱结构推断提示的关键信息,通过自适应的图压缩策略,在大幅提高压缩率的同时,很好地保证了压缩提示的可读性和实用性,是提示压缩技术的重要进展。其巧妙的设计思路和优异的性能,非常值得从事prompt工程和AI产品开发的研究者学习借鉴。我还有篇文章介绍提示词压缩Prompt压缩神器PCToolkit成新宠,简单高效、用起来棒棒哒,一键部署不复杂
为了全面评估PROMPT-SAW在任务无关提示词上的性能,研究团队还提出了GSM8K-AUG数据集,这是现有GSM8k基准的扩展版本。在任务相关数据集方面,他们使用了NATURALQUESTIONS数据集进行评估。
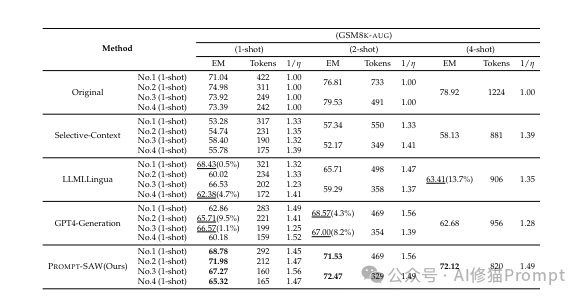
实验结果表明,与最优基线模型相比,PROMPT-SAW在任务相关和任务无关设置下的性能分别提高了14.3%和13.7%,同时将原始提示词文本压缩了33.0%和56.7%。更重要的是,PROMPT-SAW压缩的提示词在可读性方面也优于基线模型。
从上图我们可以看到,在GSM8K-AUG上,相比最优基线,PROMPT-SAW在1-shot、2-shot和4-shot设置下EM值分别提高了9.5%、8.2%和13.7%,相应的提示大小减少了31.8%、33.0%和33.0%。在NaturalQuestions上,PROMPT-SAW在目标压缩率分别为0.5、0.3和0.1时,Span Accuracy比GPT-4(最优基线)分别提高了14.30%、10.62%和6.52%,相应的提示大小减少了56.7%、74.0%和93.7%。
研究人员还比较了PROMPT-SAW压缩提示词和LLMLingua压缩提示词的可读性。结果发现,PROMPT-SAW压缩的提示词表现出更好的可读性和可解释性。这可能是因为LLMLingua等基线模型忽略了压缩提示词中标记之间的内在语义关系,导致可解释性的丧失。
我们可以看到,PROMPT-SAW通过利用图结构推断提示中的关键信息,大大提高了提示压缩的性能,同时保证了压缩提示的可读性和实用性。这一创新方法有望显著降低LLMs在实际应用中的计算成本和推理延迟,为LLMs的进一步发展和应用铺平道路。对于正在开发AI产品的Prompt工程师来说,PROMPT-SAW无疑是一个值得借鉴和学习的优秀案例。
论文的实验结果充分证明了PROMPT-SAW的有效性和优越性。在任务无关和任务相关的设置下,PROMPT-SAW的性能都显著优于现有的最优基线模型。更重要的是,PROMPT-SAW生成的压缩提示词在可读性和可解释性方面也远胜于基线模型。这意味着PROMPT-SAW在大幅提高提示压缩性能的同时,也保证了压缩提示词的人类友好性和实用性。
PROMPT-SAW的核心创新在于利用知识图谱结构来表示和分析提示词中的文本信息。通过将提示词转化为由实体和关系构成的图结构,PROMPT-SAW可以更好地推断提示词的关键信息元素,从而实现更加精准和高效的提示压缩。这一方法不仅在理论上具有创新性,在实践中也展现出了卓越的性能。
提示词压缩属于自然语言处理(Natural Language Processing, NLP)和信息提取(Information Extraction, IE)领域的问题,大家熟悉的吴恩达教授就是这个NLP和机器学习领域的知名学者。吴恩达强烈推荐研究微软的Medprompt,微调VS提示工程究竟哪个更有效,我也用最前沿的DSPy技术实现了Medprompt用DSPy将MedPrompt的智慧注入你的问答系统:一份即插即用的代码实现 。
在介绍我的代码实现之前,首先要给您介绍两个概念,一个是TF-RDF这个要在compress_graph函数中用到,另一个是大家经常看到却不一定熟悉的余弦相似度cosine_similarity。在这里我只是抛砖引玉,如果您有兴趣可以更深入的研究。
TF-RDF
使用TF-IDF向量化器将节点文本转换为TF-IDF矩阵是文本处理中的一个关键步骤,用于表示文本数据的特征。以下是详细解释:
TF-IDF的概念
TF(Term Frequency,词频):衡量某个词在一个文档中出现的频率。公式:TF = 某词在文档中的出现次数 / 文档中的总词数。
IDF(Inverse Document Frequency,逆文档频率):衡量一个词的重要性,考虑到它在整个语料库中的稀有程度。公式:IDF = log(语料库中的文档总数 / 包含该词的文档数 + 1)。
TF-IDF:
TF和IDF的乘积,用于衡量词在文档中的重要性。公式:TF-IDF = TF * IDF。
余弦相似度cosine_similarity
余弦相似度匹配是一种度量两个向量之间相似度的常见方法,特别适用于高维向量的比较。它通过计算两个向量之间夹角的余弦值来判断它们的相似性。余弦相似性范围在 -1 到 1 之间,1 表示两个向量完全相同,0 表示两者正交,-1 表示两个向量方向完全相反。
公式(和你中学学过的sine\cosine是亲戚)
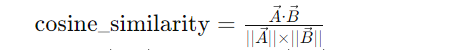
余弦相似性匹配是一种度量两个向量之间相似度的常见方法,特别适用于高维向量的比较。它通过计算两个向量之间夹角的余弦值来判断它们的相似性。余弦相似性范围在 -1 到 1 之间,1 表示两个向量完全相同,0 表示两者正交,-1 表示两个向量方向完全相反。
让我们通过一个简单的文本处理示例来说明余弦相似性在向量查询中的应用。
假设我们有以下三段文本:
1. "我喜欢读书,尤其是科幻小说。"
2. "科幻电影让我着迷,我常常去电影院。"
3. "我喜欢户外活动,尤其是远足和野营。"
我们的目标是找到与查询句子“我最近在读一本很棒的科幻小说”最相似的文本。
1)将这些文本转换为向量。
这通常通过词袋模型、TF-IDF、Word2Vec或其他NLP技术来完成。在这个例子中,我们简化这个过程,假设每个文本都已经被转换为一个向量。
2)查询向量化
将查询句子“我最近在读一本很棒的科幻小说”也转换为向量:
3)计算余弦相似性
用上面的公式计算查询向量与每个文本向量的余弦相似性。
4)选择最相似文本
计算这些值后,我们发现与查询句子最相似的是第一个文本,因为其余弦值最高。这表明第一段文本在主题和内容上与查询句子最为接近。
余弦相似度有什么用?
在实际应用中,余弦相似性匹配经常用于以下几种情况:
1. 信息检索:在海量文档中查找与查询最相似的文档,将文本表示为向量。
2.推荐系统:计算用户和项目之间的相似性,以提供个性化推荐。
3. 聚类分析:确定不同数据点之间的相似性,从而进行数据分类或聚类。
为什么能解决向量查询?
余弦相似性匹配可以解决向量查询的问题,因为它专注于比较向量的方向,而不在意向量的规模。这意味着即使两个向量代表不同量级的数据,只要方向一致,就能被识别为相似。此外,在高维空间中,余弦相似性计算相对简单,计算效率高,适用于在大量数据上进行快速匹配。
有了以上基础,我们用Graph的方式实现起来,其实主体也就四步:
1、提取实体标签
def
extract_entities_relations(text):
# 提取实体及其标签
entities = [(e.text, e.label_) for e in doc.ents]
relations = []
for sent in doc.sents:
for tok in sent:
if tok.dep_ == "ROOT":
relation = (tok.text, tok.lemma_, tok.dep_)
relations.append((sent.text, relation))
return entities, relations
2、构建图graph添加节点、边
def build_graph(entities, relations):
# 创建一个无向图
g = nx.Graph()
# 遍历所有实体,将它们作为节点添加到图中,节点的属性包括实体的标签
for ent, label in entities:
g.add_node(ent, label=label)
# 遍历所有关系,将它们作为边添加到图中
for sent, (word, lemma, dep) in relations:
rel_parts = sent.split() # 将句子拆分为单词列表
if len(rel_parts) > 1:
subj = rel_parts[0] # 取第一个词作为主语
obj = rel_parts[-1] # 取最后一个词作为宾语
if subj in g.nodes() and obj in g.nodes():
# 如果主语和宾语都在图的节点中,则在它们之间添加一条边
g.add_edge(subj, obj, relation=lemma) # 边的属性是关系的词干
return g
3、压缩图
def compress_graph(graph, ratio=0.5):
nodes = list(graph.nodes()) # 获取图中所有节点的列表
num_nodes_to_remove = int(len(nodes) * (1 - ratio)) # 计算需要删除的节点数量
vectorizer = TfidfVectorizer() # 初始化TF-IDF向量化器
node_texts = [str(node) for node in graph.nodes()] # 将节点转换为文本
tfidf_matrix = vectorizer.fit_transform(node_texts) # 生成TF-IDF矩阵
4、计算余弦相似度删除相似最高的节点实现压缩
# 计算每个节点的余弦相似度,选择相似度最高的节点删除
for i, node in enumerate(nodes):
if graph.has_node(node):
similarities = cosine_similarity(tfidf_matrix[i:i+1], tfidf_matrix)[0]
avg_similarity = sum(similarities) / len(similarities)
# 删除选定的节点
if node_to_remove:
graph.remove_node(node_to_remove)
nodes.remove(node_to_remove)
return graph
以上是实现Prompt-SAW的部分代码示例,和论文中的算法有一些差距,我没能实现原文的自然语言编码(Encoder)部分。结果还是用deepseek跑的,为什么选择这个API?只有你实际用了别家的才会体会到参数在传递和生成时的作用,真知来自实践。
PROMPT-SAW是一种先进的提示压缩方法,它巧妙地利用知识图谱结构来推断提示词的关键信息,并通过自适应的压缩策略实现了高效精准的提示压缩。实验结果充分证明了PROMPT-SAW在提高压缩性能和保证可读性方面的卓越表现。对于正在开发AI产品的Prompt工程师来说,PROMPT-SAW提供了一种全新的思路和方法,值得深入研究和学习。如果需要完整代码,请在加赞赏群后向我索要。
另外,群里为你准备了开群以来近五十份资料,包括开群以来本公众号文章的Prompt模板、模块和一些DSPy的代码文件完整示例,还有部署一些应用的Dockerfile,等你来一起讨论!另外,如果你有更多关于论文里Prompt的问题也可以到群里来,我会耐心解答你的问题。
这份指南还包含8500条复杂Prompt,以及管理工具和方法(包含system提示词)










