本文来自微信公众号:新智元 (ID:AI_era),作者:新智元,编辑:乔杨,原文标题:《ChatGPT真能记住你的话吗?DeepMind与开源大佬揭示LLM记忆之谜》,题图来自:视觉中国
Django框架的创始人之一、著名开发者Simon Willison最近发表了一篇博客文章,核心观点是——虽然很多LLM看起来有记忆,但本质上是无状态函数。

Mozilla和FireFox的联合创始人、JavaScript发明者Brendan Eich也在推特上称赞这篇博客。
似乎有记忆的LLM
从计算机科学的角度来看,最好将LLM的推理过程视为无状态函数调用——给定输入文本,它会输出接下来应该做什么。
然而使用过ChatGPT或者Gemini的人会明显感觉到,LLM似乎可以记住之前的对话内容,好像模型有记忆能力。
然而这并不能归功于模型本身。
事实上,用户每次提出一个问题时,模型收到的提示都会包含之前所有的对话内容,这些提示就是我们经常说的“上下文”。

如果不提供上下文,LLM将完全不知道之前讨论的内容。
所以,重新打开一个对话界面对LLM而言,就是一个“从头再来”的全新文本序列,完全独立于你或其他用户在之前与其发生的对话。
从另一个角度看,这种“失忆”也有好处。比如,模型开始胡说八道,或者拒绝回答你的合理问题时,就可以试试重置对话窗口。也许在新的对话中,模型的输出就能回到正轨。
这也是为什么LLM的上下文长度是一个重要的指标。如果对话过长、超出了上下文窗口,最早的那部分对话就会从提示中移除,看起来像是模型的“遗忘”。
Andrej Karpathy将上下文窗口准确地形容为“LLM工作记忆的有限宝贵资源”。
但是,有很多方法可以为LLM外置记忆能力,来满足产品使用的需求。
将之前的对话作为提示,和当前问题一起输入给LLM是最直接的方法,但这依旧是“短期记忆”,而且扩展模型上下文长度的成本很高。
GPT-4o免费版支持8k上下文,付费版可以达到128k,已经比之前的32k提升了3倍,但仍然无法保存单个网页的原始HTML。

也可以递归地总结之前的对话内容,将历史对话摘要当作LLM提示。虽然可能会丢失细节,但相比直接截断的方法,能在更高程度上保留内容的完整性。
另一种方法是外接矢量数据库,为LLM添加“长期记忆”。
在进行对话时,先从数据库中检索相关内容,再将其添加进上下文窗口,也就是检索增强生成(RAG)。
但如果数据库内容过多,检索过程很可能增加模型的响应延迟。
实际开发中,检索、摘要这两种手段常常搭配使用,以求在成本和性能、长期和短期记忆之间取得平衡。
推理无法记忆,但训练可以
LLM的推理过程虽然等效于“无状态函数”,但训练过程并不是这样,否则它也无法从语料中学习到任何知识。
但我们对于LLM记忆的分歧之处在于,它到底是用“机械”的方式复制了训练数据,还是更像人类的学习过程,用理解、概括的方式将数据内容集成在参数中?
DeepMind近期发表的一篇论文或许可以从另一个角度揭示这个问题。

他们使用与训练语料相似的prompt攻击LLM,看它能否逐字逐句地输出训练数据。
但Falcon、Llama、Mistral这种常用的半开放LLM,以及GPT系列都没有公开训练数据,要怎么判断模型的输出是否包括在训练集中?
论文使用了一种巧妙的方法进行判断:首先,从RefinedWeb、RedPajama、Pile等常用的LLM预训练数据集中选取了9TB的文本作为辅助数据集。
如果模型输出的文本序列足够长、信息熵又足够大,而且还和辅助数据集内容重合,那么基本可以断定模型在训练时见过这条数据。
这样的判断方法会存在假阴性,因为辅助数据集不可能涵盖所有模型的训练数据,但几乎没有假阳性,因此得到的结果可以作为模型“复现”训练内容的比例下界。
结果发现,所有的模型都能逐字逐句地输出训练数据,只是概率有所差异。
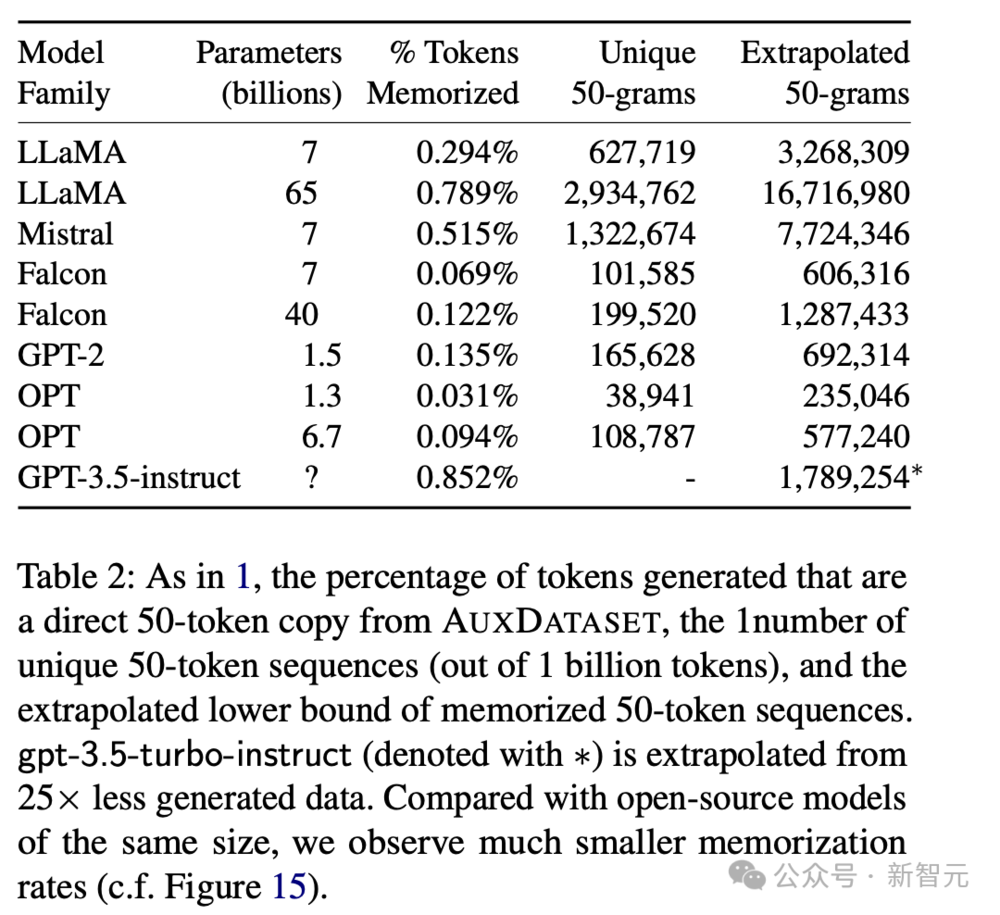
从结果中可以发现,参数量越大的模型似乎记住的内容越多,越有可能在输出中让训练数据回流。
不同系列的模型之间的差异比较显著。比如7B参数的Mistral相比Falcon,有将近10倍的概率会原样吐出训练数据。
但可能的原因有很多,既能解释为模型记忆能力的差距,也能归因于辅助数据集的偏差。
有趣的是,如果prompt的要求是一直持续输出某个单词,有些单词更有可能触发模型吐出训练数据。

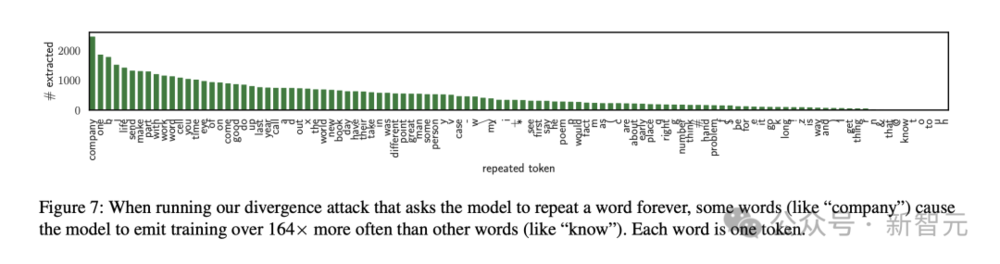
最有效的一个单词是“company”
作者指出,从安全的角度来看,这说明对齐过程没有完全模糊模型的记忆,这些可提取的训练数据会带来版权纠纷与隐私泄露问题。
但从另一个角度来看,这证明了有一定比例的训练数据被无损压缩且被存储在了模型参数中。模型的记忆方式,果然是有些“机械化”的成分。
更进一步思考,如果改进LLM的记忆方式,让训练数据以更概括、更抽象的方式存储在参数中,能否带来模型能力的持续提升?
参考资料:
https://simonwillison.net/2024/May/29/training-not-chatting/
https://medium.com/@iankelk/how-chatgpt-fools-us-into-thinking-were-having-a-conversation-fe3764bd5da1
本文来自微信公众号:新智元 (ID:AI_era),作者:新智元,编辑:乔杨
本内容为作者独立观点,不代表虎嗅立场。未经允许不得转载,授权事宜请联系hezuo@huxiu.com
如对本稿件有异议或投诉,请联系tougao@huxiu.com
End







