Python 提供了多种数据容器,比如最流行的列表、元组,他们本质上是一个对象接一个对象存储在数据容器中的序列;通过索引访问容器中的特定对象。

如果要序列中获取子序列就是切片(Slicing)操作了。切片(Slicing)可以序列(如字符串、列表、元组,也包括Numpy 数组、pandas dataframe)中提取子序列。通过切片,你可以指定要提取的元素的起始和结束位置,并且可以指定步长。
切片(Slicing)的基本语法
切片(Slicing)的基本语法如下:
sequence[start:stop:step]
start:切片的起始索引(包括)。
stop:切片的结束索引(不包括)。
step:切片的步长(默认为1)。
基本切片(Slicing)
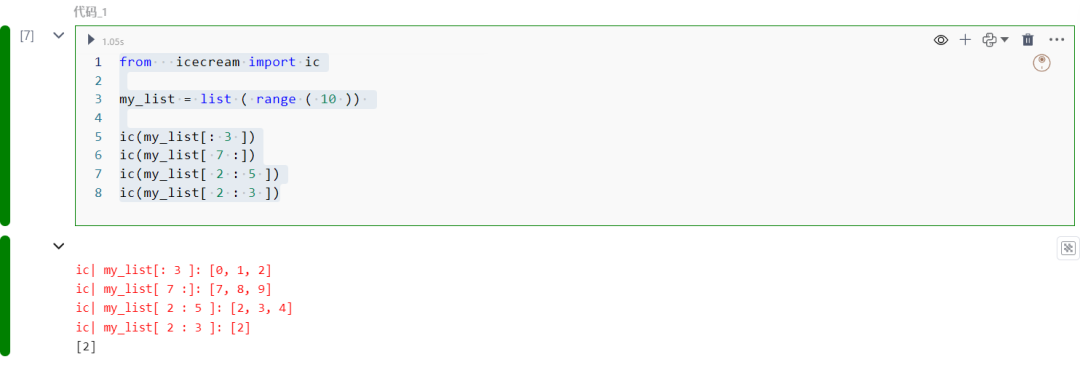
from icecream import ic
my_list = list ( range ( 10 ))
ic(my_list[: 3 ])ic(my_list[ 7 :])ic(my_list[ 2 : 5 ])ic(my_list[ 2 : 3 ])
负索引切片(Slicing)
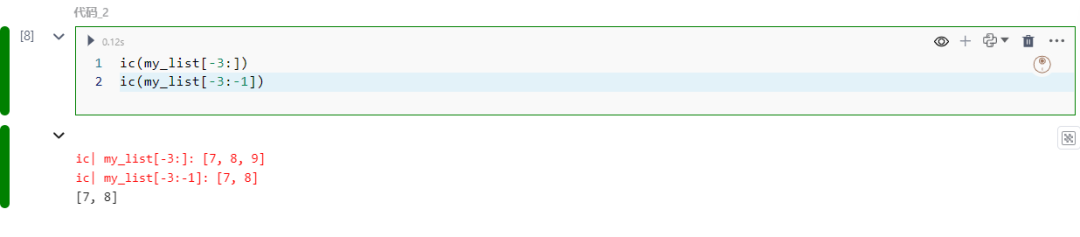
负索引切片允许你从列表末尾开始访问元素,非常适合在不知道列表长度的情况下进行操作。
ic(my_list[-3:])ic(my_list[-3:-1])
带步长的切片(Slicing)

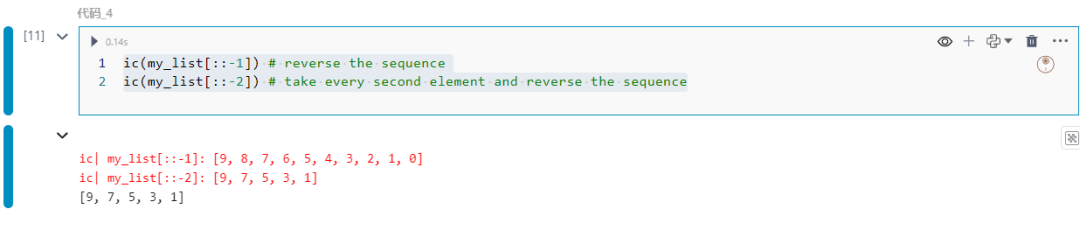
步长的负值意味着反转顺序:
ic(my_list[::-1]) ic(my_list[::-2])
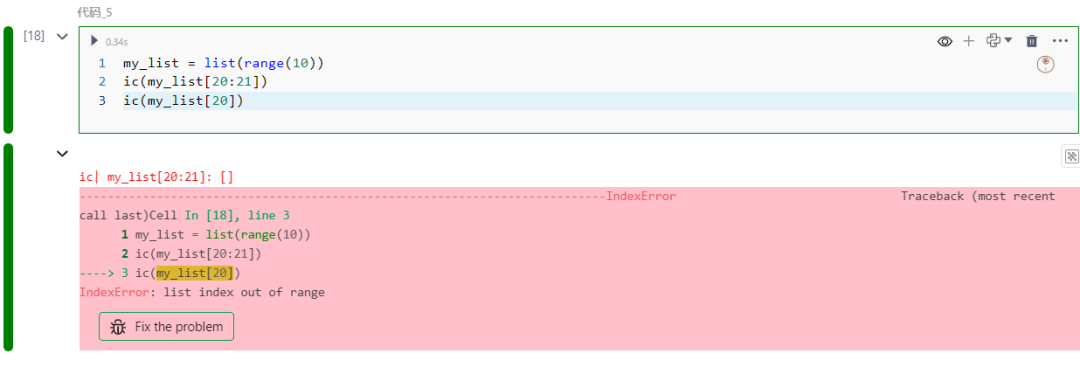
请注意,当在索引时使用不存在的索引时,Python 会抛出错误;但是,可以在范围/切片中使用不存在的元素:
使用切片(slice)对象
当您使用 sequence[start:stop:step] 时,Python 实际上调用了 sequence.__getitem__(slice(start, stop, step))。如您所见,范围被转换成了所谓的切片对象。您也可以自己这样做,这意味着您可以用 sequence[slice(start, stop, step)] 来代替 sequence[start:stop:step]。
切片对象提供了一种不同的切片技术。它使您能够保留如何切片数据序列的信息——这是您使用范围时无法做到的。您可以使用内置的 slice 类来创建切片对象,该类接受 start、stop 和 step 参数。它们的含义与我们上面使用的范围的对应元素相同。当需要在代码中重复使用或传递切片参数时,切片对象特别有用。
当需要在代码中重复使用或传递切片参数时,切片对象特别有用。
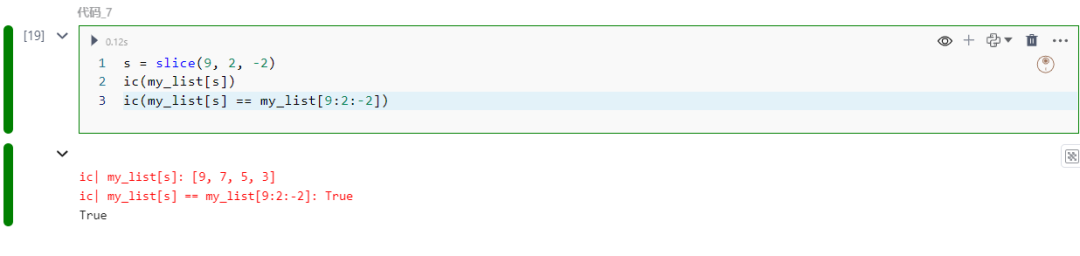
s = slice(9, 2, -2)ic(my_list[s])ic(my_list[s] == my_list[9:2:-2])
合并切片对象
切片对象本身不支持加法或连接,因为它们代表的是序列的特定切片,而不是序列本身。
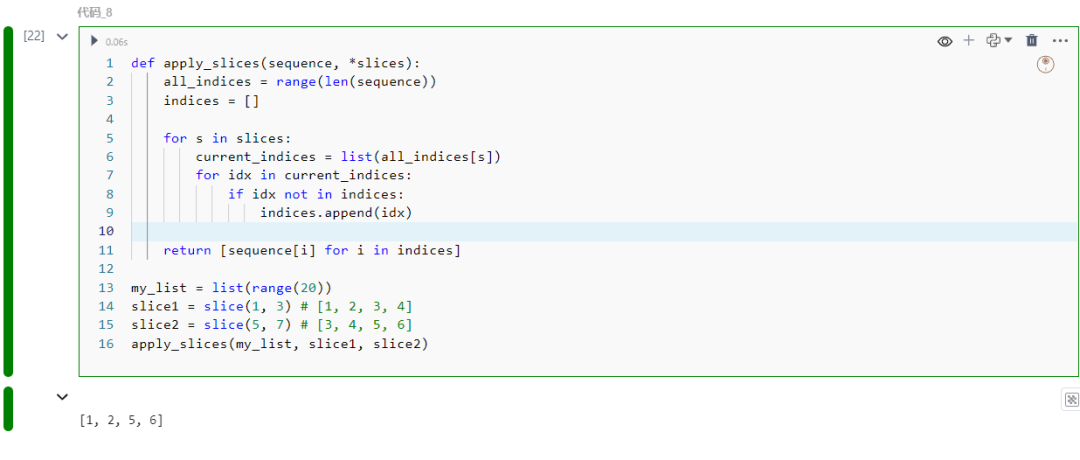
如果您想使用两个或多个切片简单地获取序列中的所有元素,只需对每个切片使用它们并合并所得的序列。但是,如果您不想重复相同的元素(如果切片部分或完全重叠),这种方法将不起作用。我们需要一个自定义函数,以下是该函数:
def apply_slices(sequence, *slices): all_indices = range(len(sequence)) indices = [] for s in slices: current_indices = list(all_indices[s]) for idx in current_indices: if idx not in indices: indices.append(idx) return [sequence[i] for i in indices]
my_list = list(range(20))slice1 = slice(1, 3) slice2 = slice(5, 7) apply_slices(my_list, slice1, slice2)
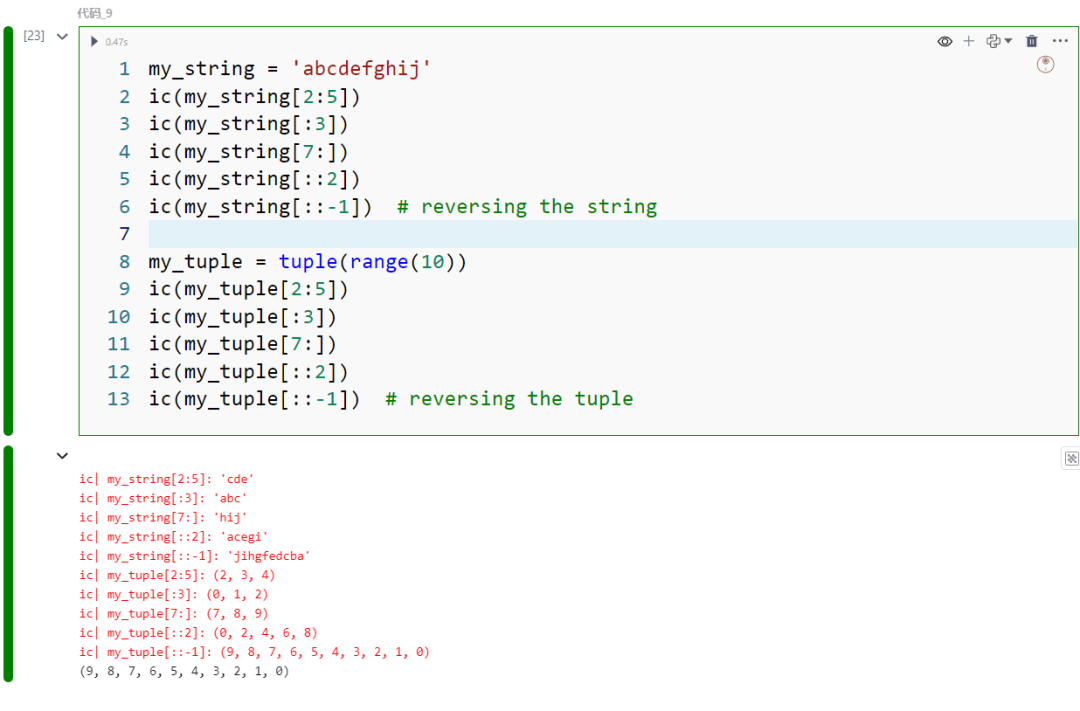
上述在list上切片的操作同样适用于元组(tuple)和字符串:
my_string = 'abcdefghij'ic(my_string[2:5])ic(my_string[:3])ic(my_string[7:])ic(my_string[::2])ic(my_string[::-1]) # reversing the string
my_tuple = tuple(range(10))ic(my_tuple[2:5])ic(my_tuple[:3])ic(my_tuple[7:])ic(my_tuple[::2])ic(my_tuple[::-1]) # reversing the tuple
切片 NumPy 数组
NumPy 数组是用于数据科学中的一种强大数据结构,专门用于在 Python 中进行数值计算。您可以创建一维和多维数组,而后者的索引可能会相当复杂。NumPy 数组支持高级切片技术。从本质上讲,它们与切片 Python 列表类似,但在多维数组的情况下,切片可能变得相当复杂。
切片一维 NumPy 数组类似于切片 Python 列表,所以让我们使用之前的相同示例。
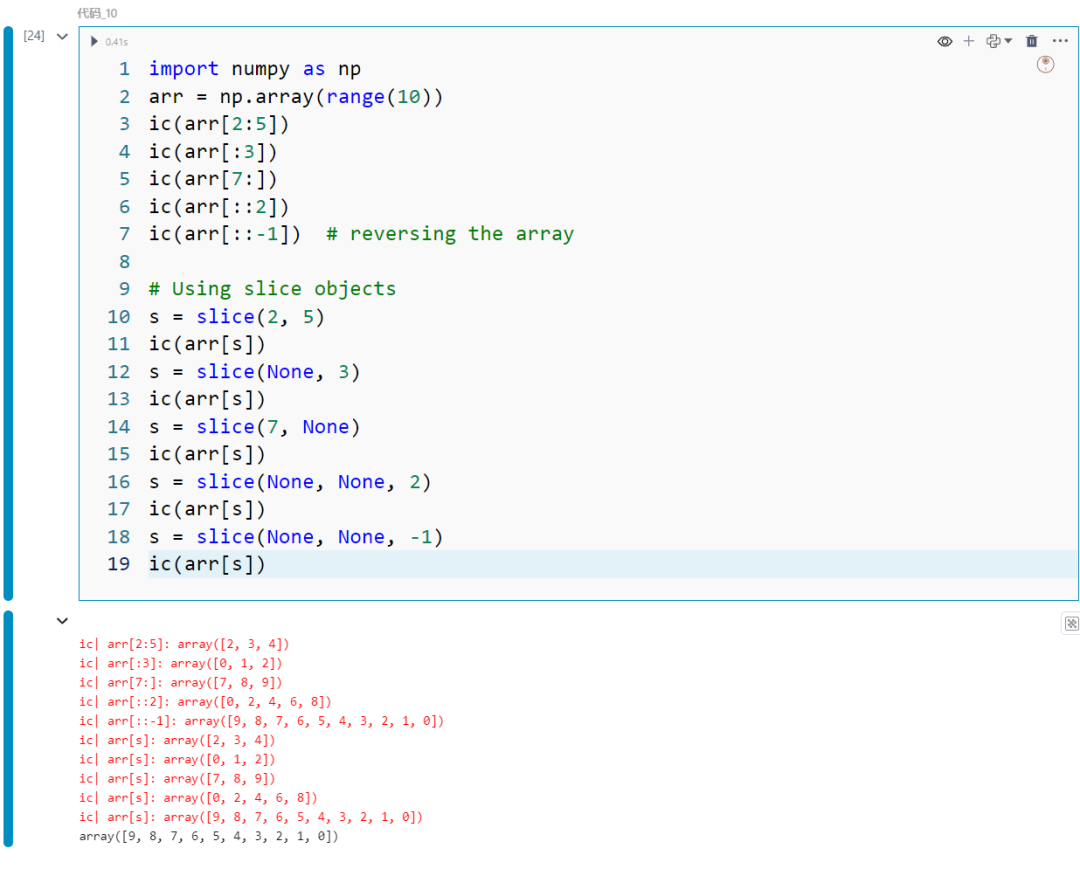
import numpy as nparr = np.array(range(10))ic(arr[2:5])ic(arr[:3])ic(arr[7:])ic(arr[::2])ic(arr[::-1]) # reversing the array
s = slice(2, 5)ic(arr[s])s = slice(None, 3)ic(arr[s])s = slice(7, None)ic(arr[s])s = slice(None, None, 2)ic(arr[s])s = slice(None, None, -1)ic(arr[s])
对于多维 NumPy 数组,您可以通过用逗号分隔的切片来对每个维度进行切片。让我们从二维数组开始:
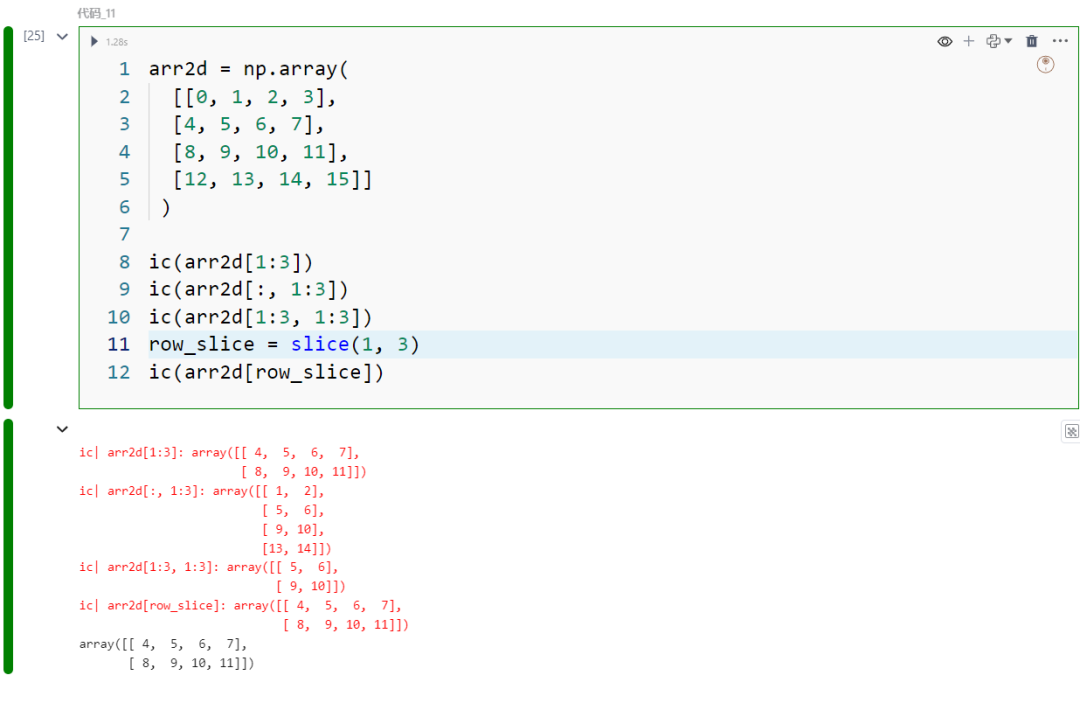
arr2d = np.array( [[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14, 15]] )
ic(arr2d[1:3])ic(arr2d[:, 1:3])
ic(arr2d[1:3, 1:3])row_slice = slice(1, 3)ic(arr2d[row_slice])
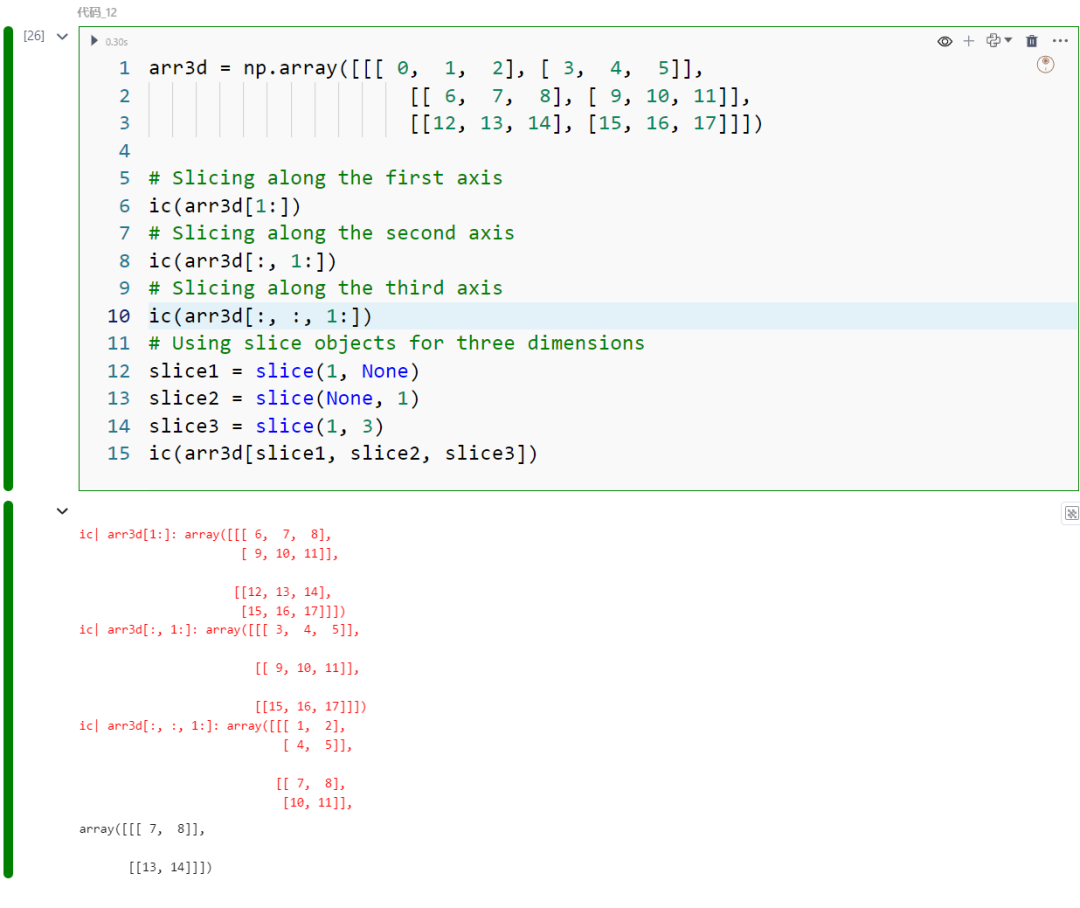
切片三维数组当然会更复杂一些:
arr3d = np.array([[[ 0, 1, 2], [ 3, 4, 5]], [[ 6, 7, 8], [ 9, 10, 11]], [[12, 13, 14], [15, 16, 17]]])
ic(arr3d[1:])ic(arr3d[:, 1:])
ic(arr3d[:, :, 1:])
slice1 = slice(1, None)slice2 = slice(None, 1)slice3 = slice(1, 3)ic(arr3d[slice1, slice2, slice3])
切片 Pandas 数据框
Pandas 中最重要的数据结构是数据框(pd.DataFrame)。它以可读性强且易于理解的形式表示表格数据。数据框允许进行灵活的索引和切片操作。与 NumPy 数组一样,我们将考虑切片 Pandas 数据框的行和列。我们还将探索使用 .loc 和 .iloc 索引器进行切片,前者是基于标签的索引器,后者是基于位置的索引器。
示例如下:
import pandas as pddata = { 'A': range(5), 'B': range(5, 10), 'C': range(10, 15), 'D': range(15, 20)}labels = ['a', 'b', 'c', 'd', 'e']df = pd.DataFrame(data, index=labels)ic(df)
ic(df.iloc[2:5])row_slice = slice(2, 5)ic(df.iloc[row_slice])
ic(df.loc['c':'e'])row_slice = slice('c', 'e')ic(df.loc[row_slice])

使用索引位置切片行和列,通过使用标签范围来切片行和列:
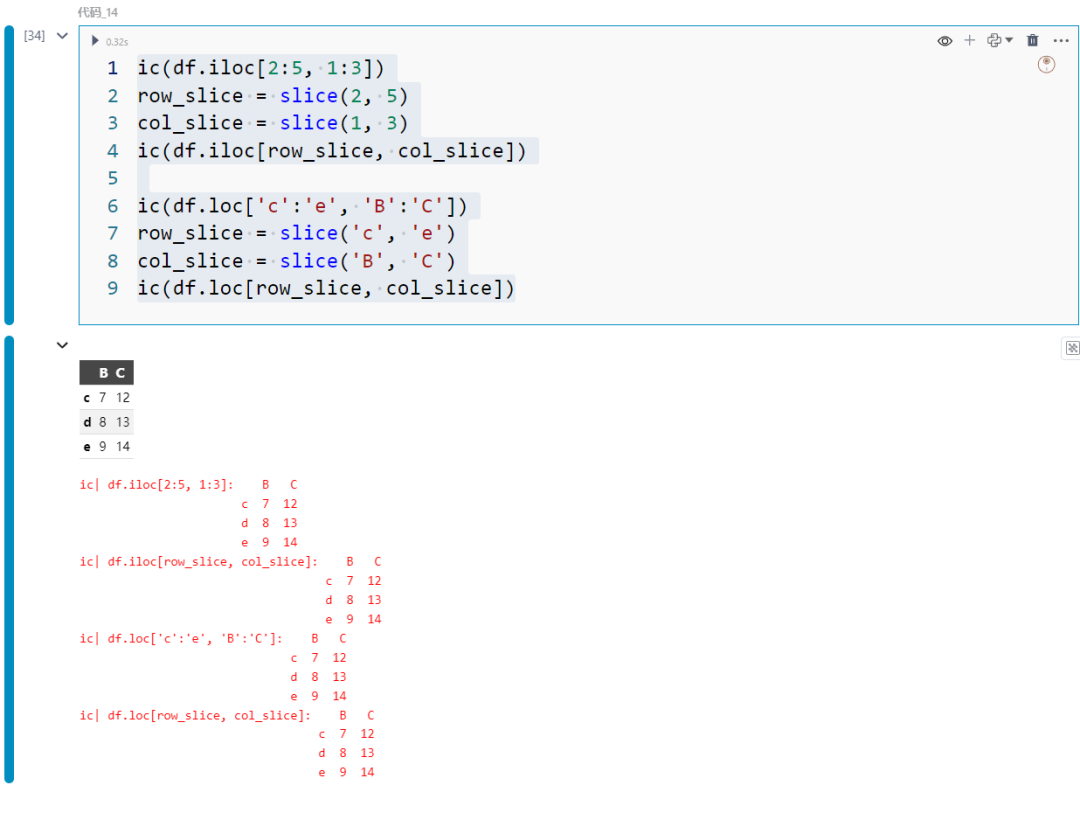
ic(df.iloc[2:5, 1:3])row_slice = slice(2, 5)col_slice = slice(1, 3)ic(df.iloc[row_slice, col_slice])
ic(df.loc['c':'e', 'B':'C'])row_slice = slice('c', 'e')col_slice = slice('B', 'C')ic(df.loc[row_slice, col_slice])
探索了 Python 中各种数据结构的切片技术,从基本的列表和元组到更复杂的 NumPy 数组和 Pandas 数据框。我们已经看到切片是多么强大和灵活,可以实现高效和直观的数据操作。









