pandas的可视化方法,分为图形可视化和表格可视化。
本次介绍完整的图形可视化使用方法,包括基础和高级两部分。
基础可视化
一种是针对series和dataframe的绘制方法,可以一行代码快速绘图。
dataframe.plot.func()
series.plot.func()
func()主要是日常比较基础的图形,如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('ggplot')
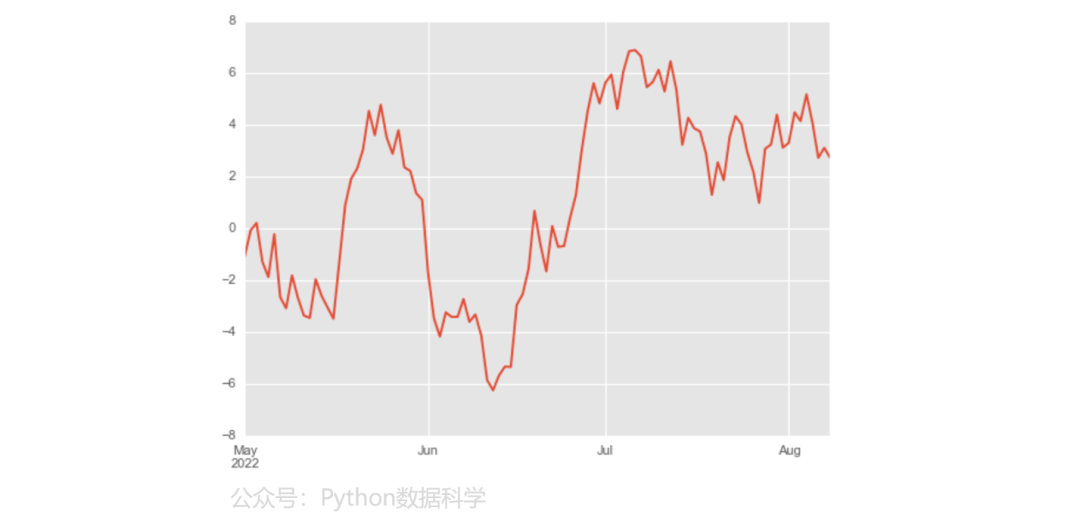
1)折线图
np.random.seed(123)
ts = pd.Series(np.random.randn(100), index=pd.date_range("5/1/2022", periods=100))
tsc = ts.cumsum()
tsc.plot(kind="line")
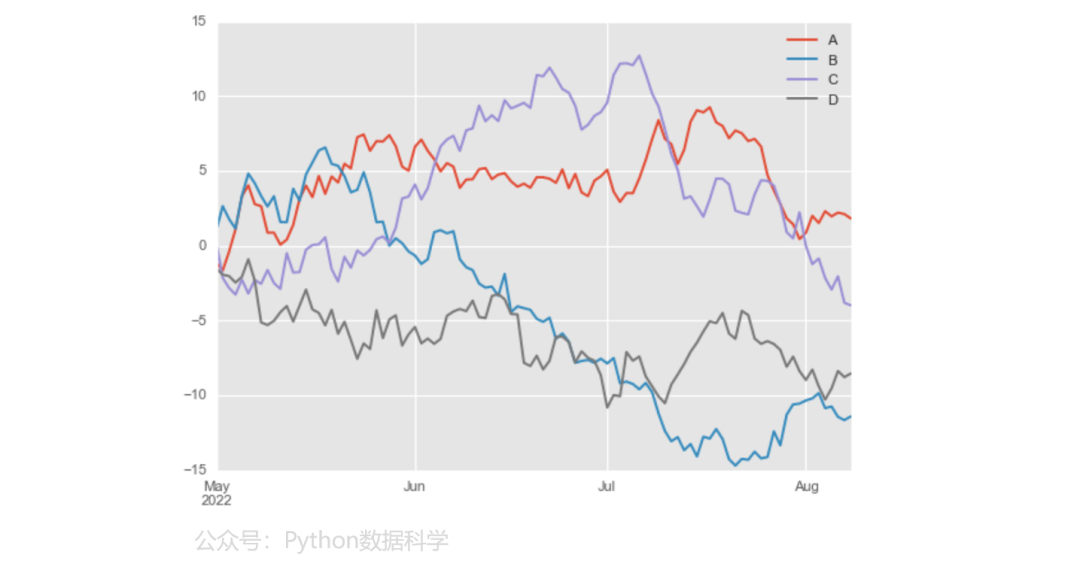
多组折线图
np.random.seed(123)
df = pd.DataFrame(np.random.randn(100, 4), index=ts.index, columns=list("ABCD"))
df = df.cumsum()
df.plot.line()
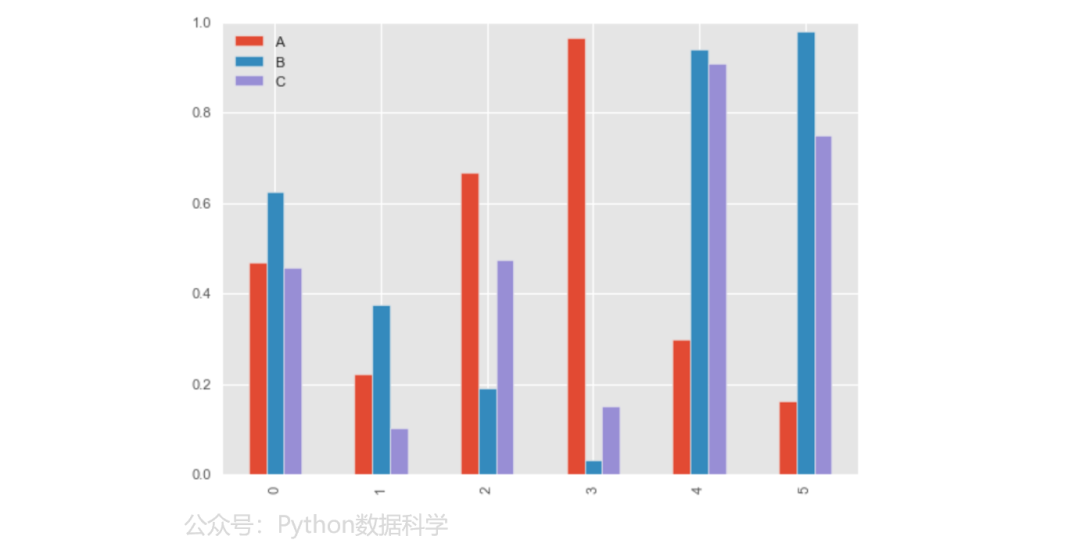
2)条形图
多组条形图
df = pd.DataFrame(np.random.rand(6, 3), columns=list('ABC'))
df.plot.bar()
堆积条形图
df.plot.bar(stacked=True)
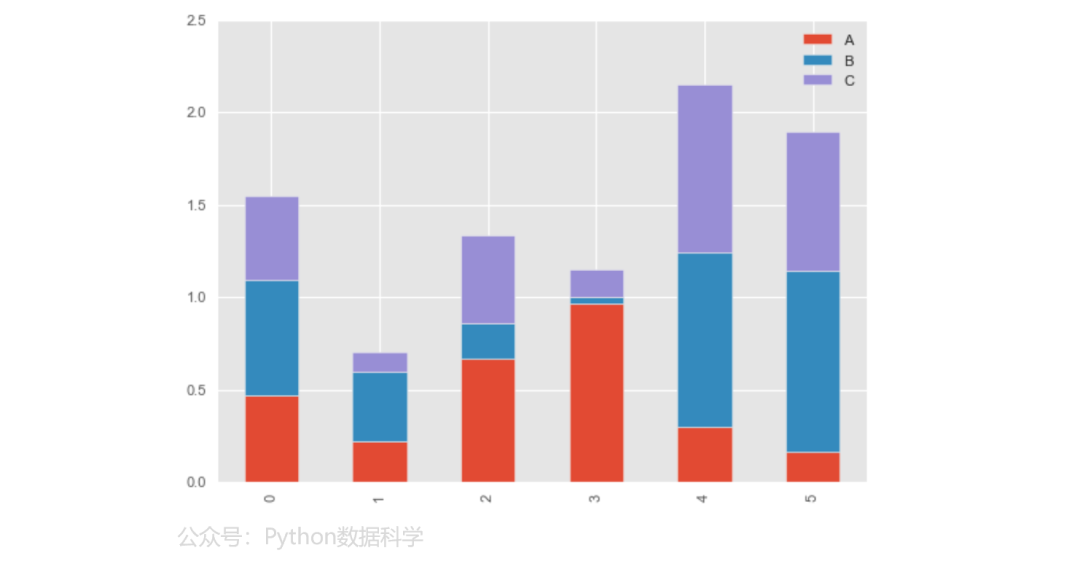
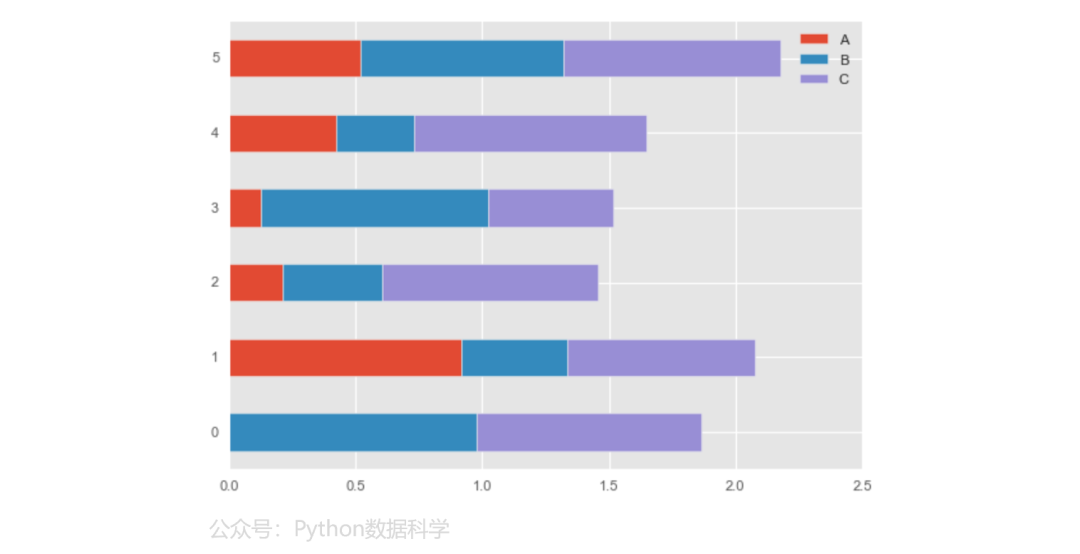
水平堆积条形图
df.plot.barh(stacked=True)
3)直方图
np.random.seed(123)
df = pd.DataFrame(
{
"A": np.random.randn(100) + 1,
"B": np.random.randn(100),
"C": np.random.randn(100) - 1,
},
columns=list('ABC')
)
df.plot.hist(alpha=0.8)
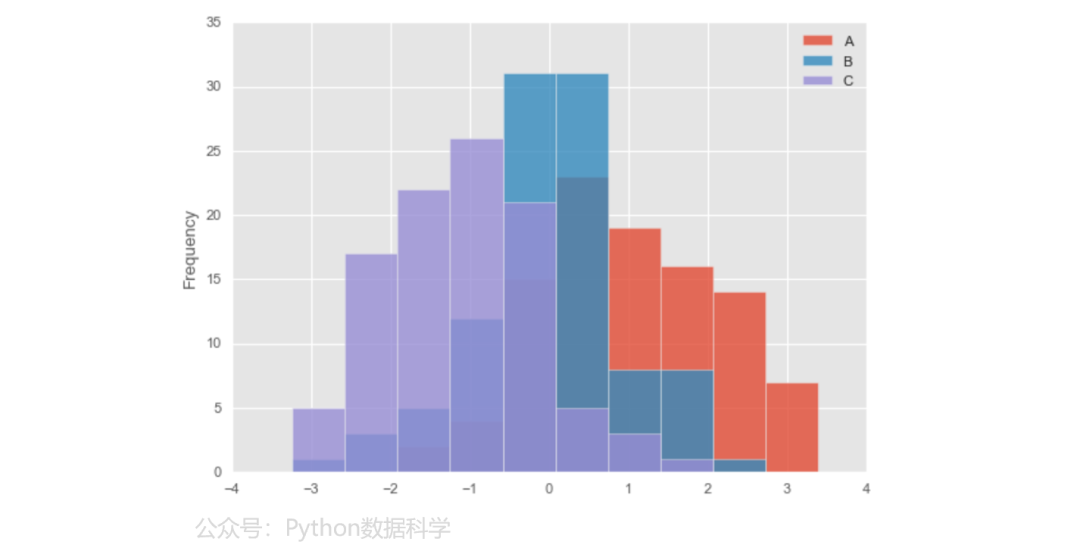
4)箱型图
np.random.seed(123)
df = pd.DataFrame(np.random.rand(20, 6), columns=list('ABCDEF'))
df.plot.box()
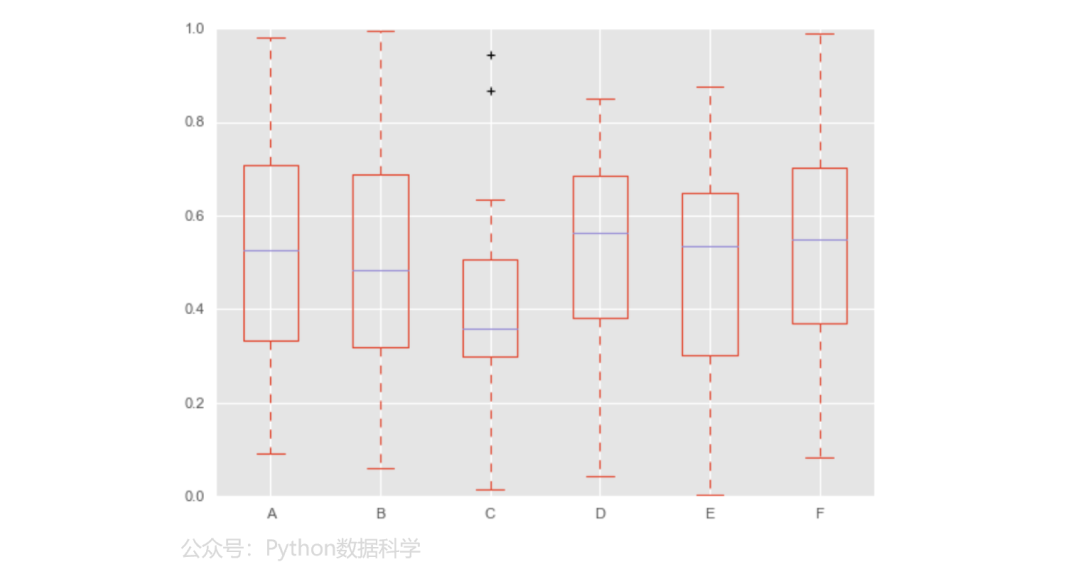
5)面积图
np.random.seed(123)
df = pd.DataFrame(np.random.rand(20, 6), columns=list('ABCDEF'))
df.plot.area()
6)散点图
ax = df.plot.scatter(x='A', y='B', color="r", label='S1',s=120)
df.plot.scatter(x='C', y='D', color="g", label='S2', ax=ax, s=100)
7)饼图
np.random.seed(123)
series = pd.Series(np.random.rand(5), index=list('ABCDE'), name='test')
series.plot.pie()
df = pd.DataFrame(
np.random.rand(5, 2), index=list('ABCDE'), columns=list('12')
)
df.plot.pie(subplots=True,figsize=(12,8))
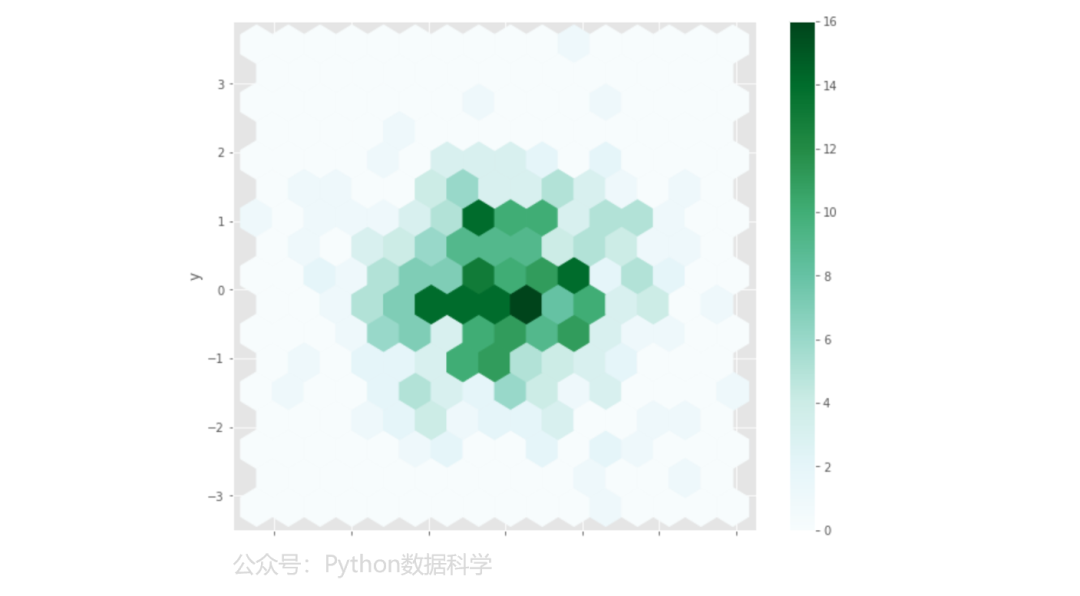
8)六边形分箱图
np.random.seed(123)
df = pd.DataFrame({'x': np.random.randn(500),
'y': np.random.randn(500)})
ax = df.plot.hexbin(x='x', y='y', gridsize=15, figsize=(10,8))
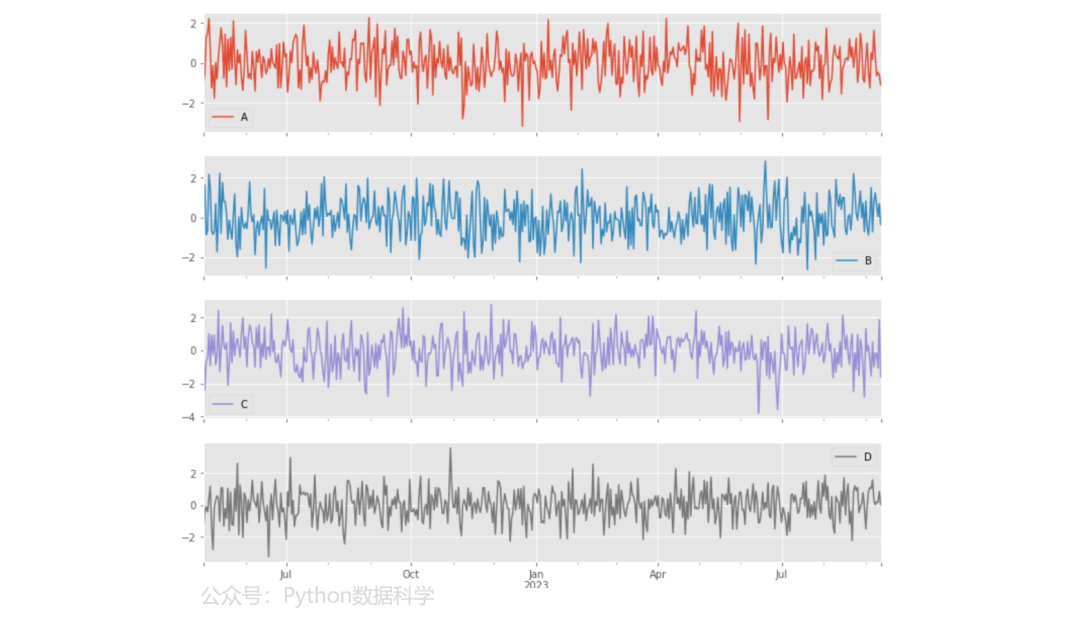
9)子图
plot()的参数设置subplots=True即可自动对dataframe数据生成子图的可视化图形。
np.random.seed(123)
index = pd.date_range("5/1/2022", periods=500)
df = pd.DataFrame(np.random.randn(500, 4), index=index, columns=list("ABCD"))
df.plot(subplots=True, figsize=(12, 10))
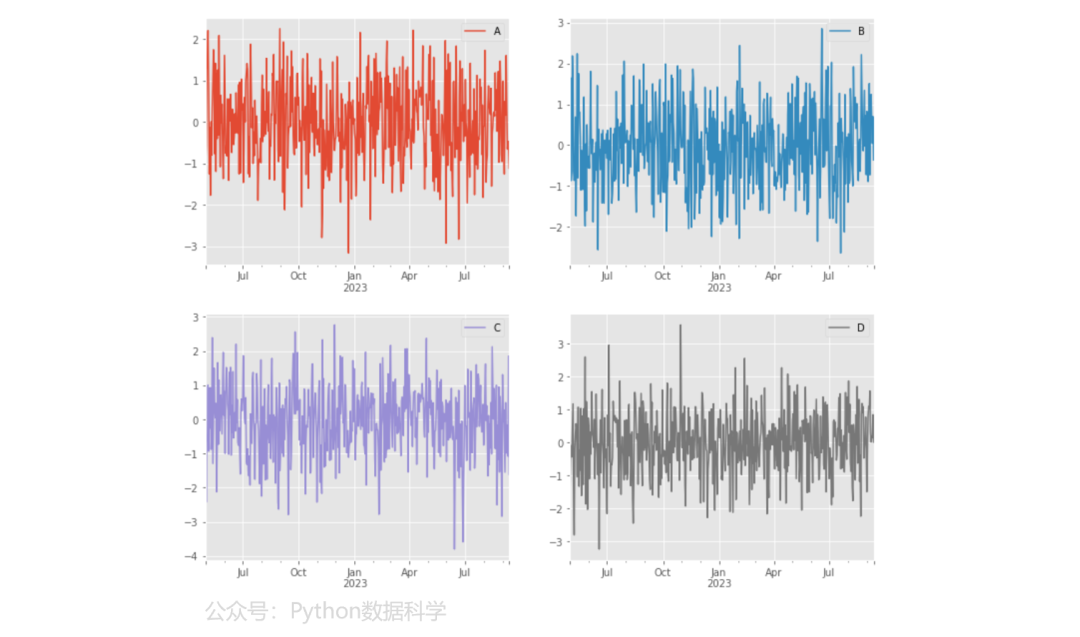
子图的布局可以通过layout设置,(2,2)代表行列数量都为2的可视化图。
df.plot(subplots=True, layout=(2, 2), figsize=(12, 10), sharex=False)
高级可视化
另一种是pandas的plotting模块,提供了更高级的绘制方法,如下:
- 平行坐标图(parallel_coordinates)
- 自相关图(autocorrelation_plot)
-
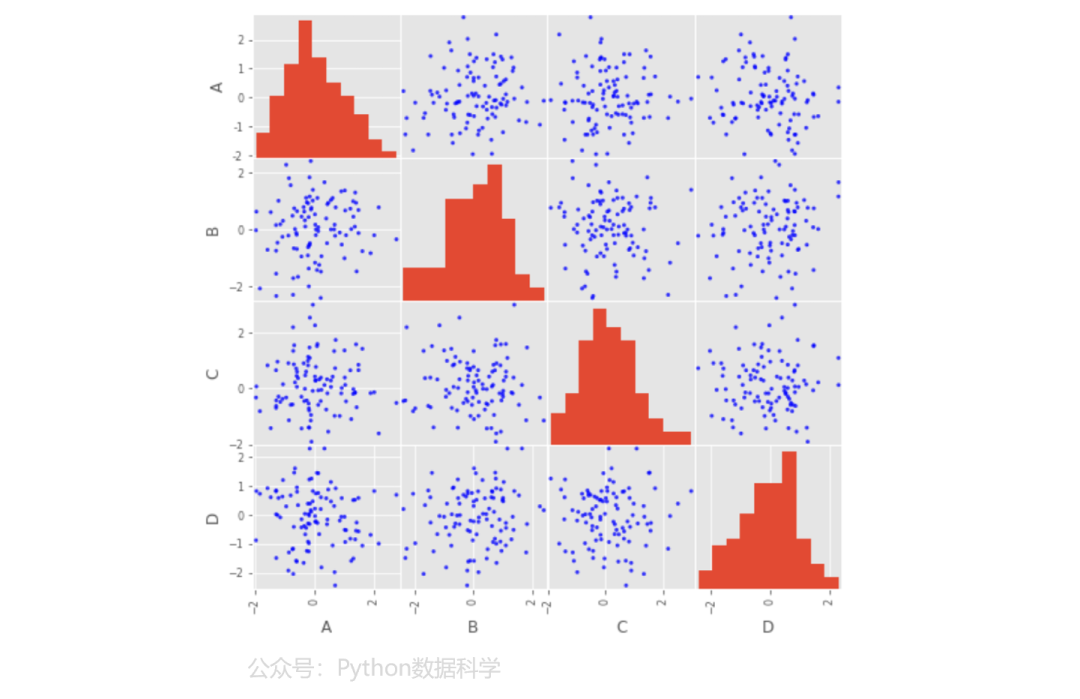
1)散点矩阵图
scatter_matrix可以直接生成特征间的散点矩阵图,以快速了解特征间的关系。对角线则默认为特征的直方图,也可以指定为kde的核密度分布曲线形式。
from pandas.plotting import scatter_matrix
df = pd.DataFrame(np.random.randn(100,4), columns=list('ABCD'))
scatter_matrix(df, c='b', alpha=0.8, figsize=(8,8))
plt.show()
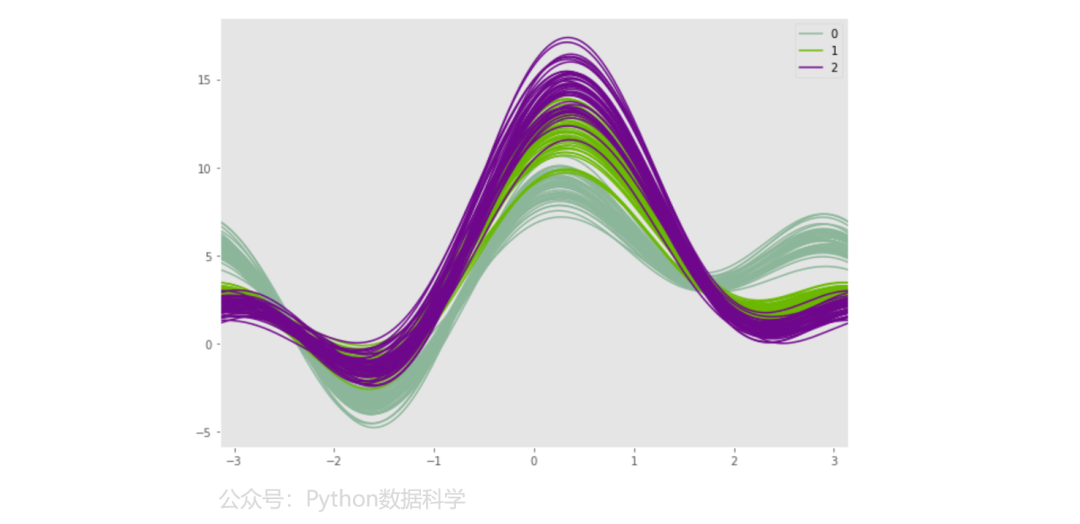
2)安德鲁斯曲线图
安德鲁斯曲线(andrews_curves)是一种针对多元数据的绘图方法,这些曲线是使用样本的属性作为傅里叶级数的系数创建的,通过为每个类对这些曲线进行不同的着色,可以可视化数据聚类。属于同一类别的样本的曲线通常会更靠近在一起并形成较大的结构。
from sklearn import datasets
df = pd.DataFrame(datasets.load_iris().data)
df['target'] = datasets.load_iris().target
plt.figure( figsize=(10,7))
pd.plotting.andrews_curves(df, class_column='target')
3)平行坐标图
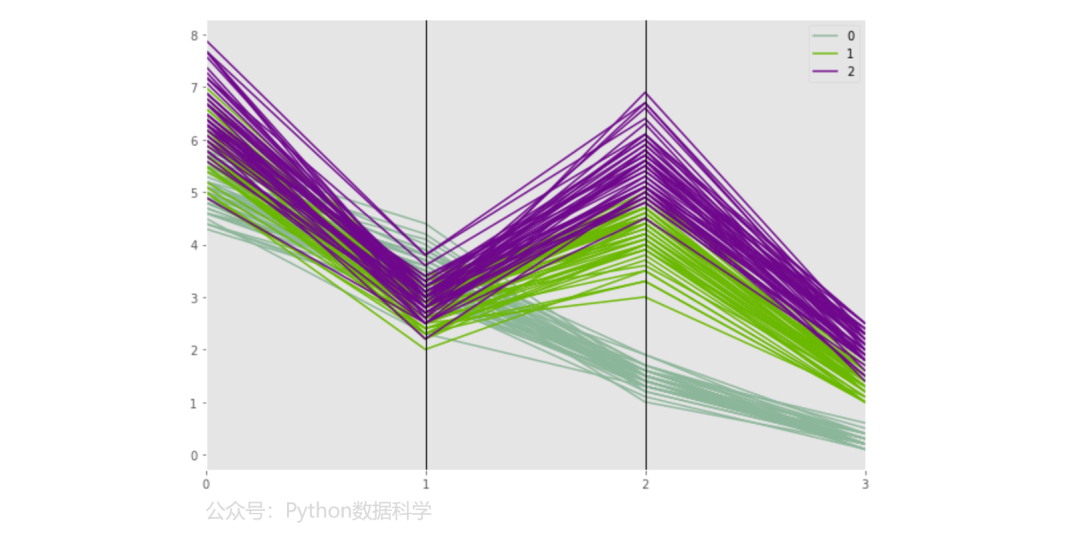
与安德鲁斯曲线图类似,平行坐标图(parallel_coordinates)也是一种用于绘制多元数据的绘图方法,通过平行坐标可以看到数据中的聚类,并直观地估计其他统计信息。
每条垂直线代表一个属性,各个属性值通过线段连接,连续的一组连接线段代表一个样本数据。每种颜色代表一种类别,线段趋势更加聚集。
from pandas.plotting import parallel_coordinates
plt.figure( figsize=(10,7))
parallel_coordinates(df, class_column='target')
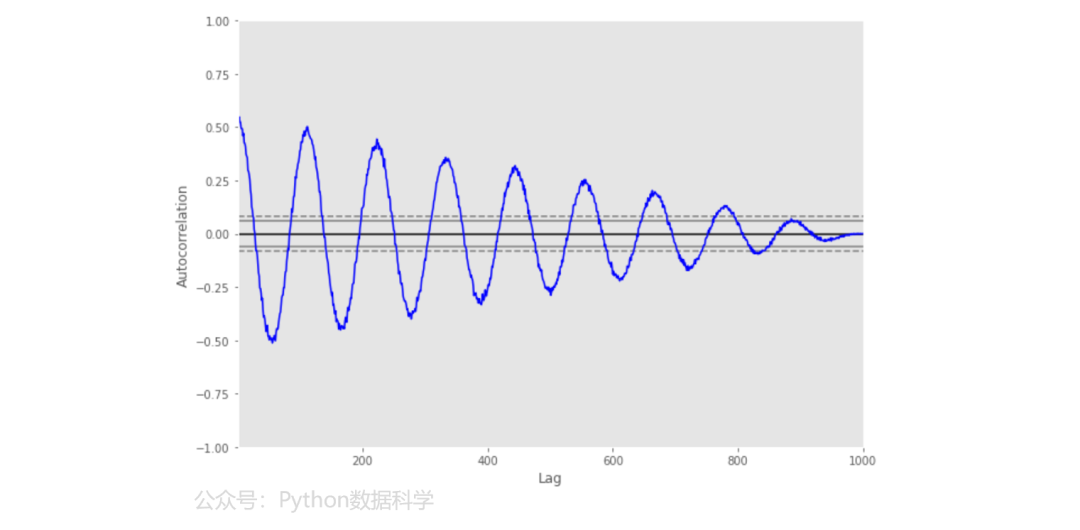
4)自相关图
自相关图(autocorrelation_plot)通常用于检查时间序列的特性,横坐标表示延迟阶数,纵坐标表示自相关系数。
from pandas.plotting import autocorrelation_plot
spacing = np.linspace(-9 * np.pi, 9 * np.pi, num=1000)
data = pd.Series(0.7 * np.random.rand(1000) + 0.3 * np.sin(spacing))
plt.figure( figsize=(10,7))
autocorrelation_plot(data, color='b')
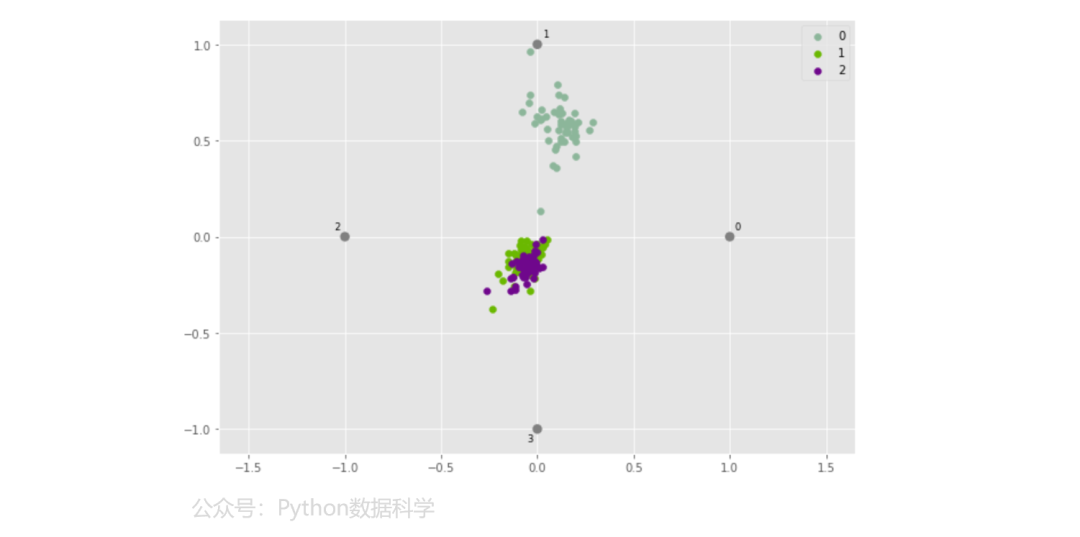
5)雷达图
RadViz雷达图是一种多变量数据的可视化算法,它围绕圆周均匀地分布每个特征,并且标准化了每个特征值,一般使用此方法来检测类之间的关联。
from pandas.plotting import radviz
plt.figure( figsize=(10,7))
radviz(df, class_column='target')
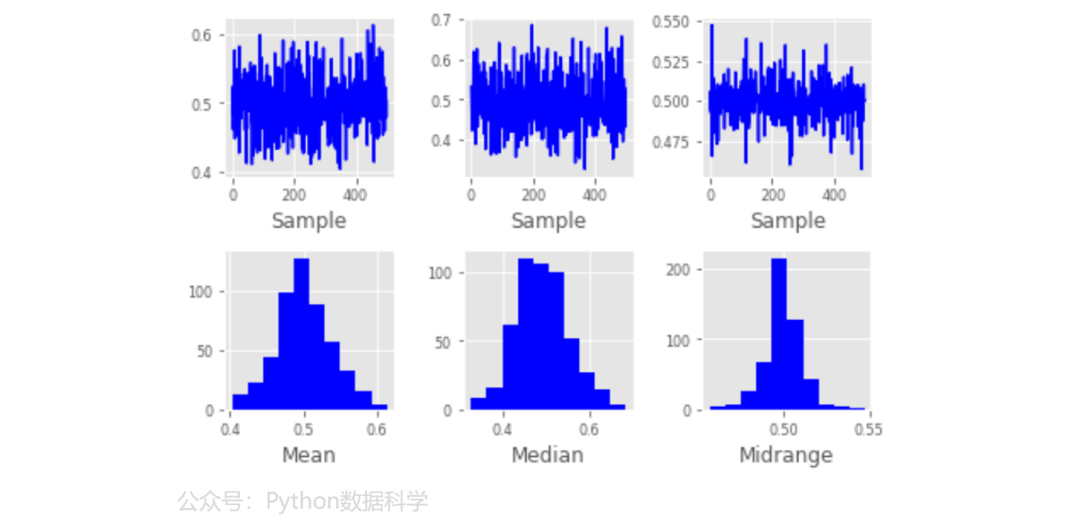
6)引导图
引导图(bootstrap plot)用于直观地评估统计数据的不确定性,例如均值、中位数、中间范围等。 从数据集中选择指定大小的随机子集,并为这些子集计算出相关的统计信息,指定重复的次数。
from pandas.plotting import bootstrap_plot
np.random.seed(123)
data = pd.Series(np.random.rand(1000))
bootstrap_plot(data, size=50, samples=500, color='b')
plt.show()
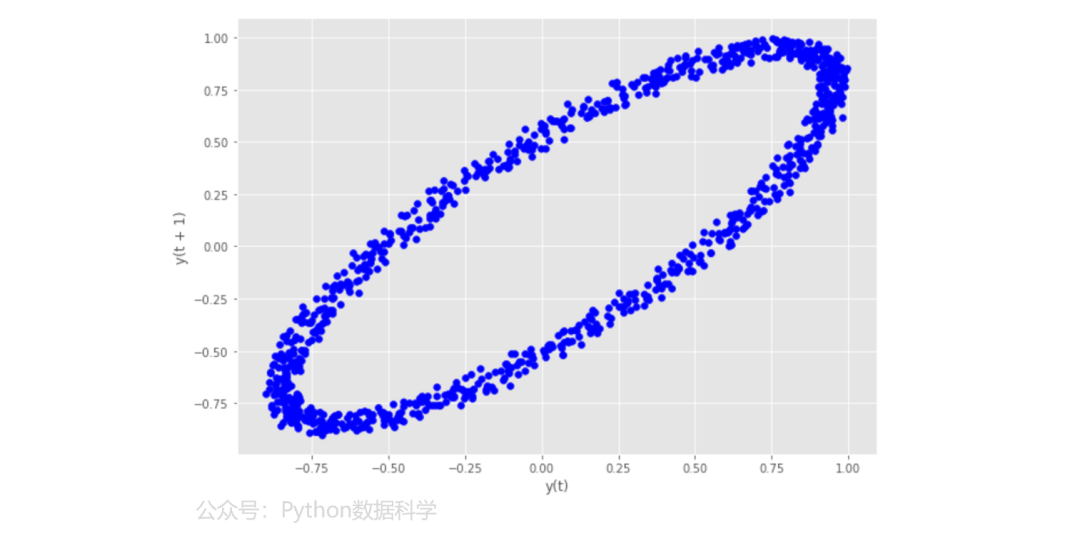
7)滞后图
滞后图(lag_plot)是用时间序列和相应的滞后阶数序列做出的散点图,可以用于观测自相关性。
from pandas.plotting import lag_plot
spacing = np.linspace(-99 * np.pi, 99 * np.pi, num=1000)
data = pd.Series(0.1 * np.random.rand(1000) + 0.9 * np.sin(spacing))
plt.figure( figsize=(10,7))
lag_plot(data, c='b')
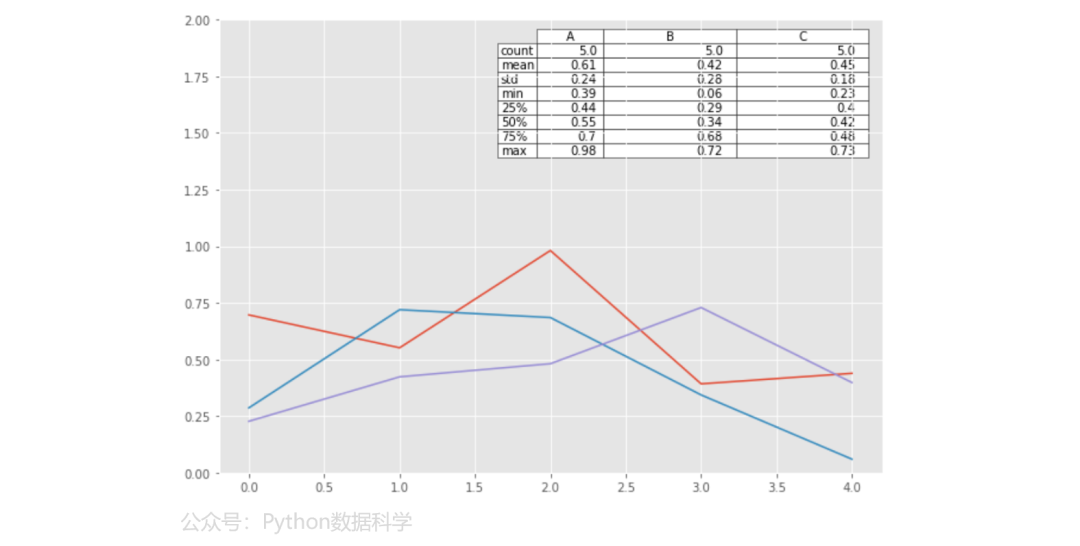
8)图中绘制表格
在可视化图中插入table表格,可以自定义表格的大小以及位置。
from pandas.plotting import table
fig, ax = plt.subplots(1, 1, figsize=(10, 7))
np.random.seed(123)
df = pd.DataFrame(np.random.rand(5, 3), columns=list('ABC'))
data = np.round(df.describe(),2)
table(ax, data, loc="upper right", colWidths=[0.1, 0.2, 0.2])
df.plot(ax=ax, ylim=(0, 2), legend=None)