项目基本信息
项目名称:基于深度学习与动态规划的街景影像文本信息提取研究
项目负责人:刘菊华
依托单位:武汉大学
项目参与人:
苏海 武汉大学
袁媛 武汉大学
单武扬 武汉大学
杨慧芳 武汉大学
申春辉 武汉大学
丰立昱 武汉大学
周罗岚 武汉大学
摘要

街景影像作为摄影测量系统的基础数据之一,包含了许多重要的文本信息,这些具有明确语义的文本信息是描述与理解影像场景内容的关键线索,因此开展街景影像文本信息提取研究具有十分重要的意义。针对现有方法的不足,本研究拟提出“候选文本定位—候选文本增强—文本识别”的研究思路,发展基于深度学习与动态规划的街景影像文本信息提取方法,主要研究内容包括:1)研究基于自适应SLINK聚类的文本定位方法,为文本增强与识别提供候选文本;2)研究深度学习方法理论,构建基于深度学习的字符分类器,并在此基础上研究候选文本增强方法,为文本识别提供可靠的候选字符;3)研究基于动态规划的文本智能识别方法,利用动态规划算法,结合字符分类器与先验知识库的反馈信息对文本进行智能识别,提高文本识别精度。研究成果在图像检索、智能导航、智慧城市以及城市信息化等领域具有重要的实际应用价值。
项目结题成果报告
以下研究成果内容摘自项目结题成果报告。该项目报告共计27页,关注城市数据派微信公众号,在微信公众号对话框中输入 24815,即可获得报告全文PDF的下载方式:

(1)主要研究内容
本项目主要研究内容包括以下三个方面:
针对现有候选文本定位方法存在的问题,提出了两种候选文本定位方法。(1)针对现有候选字符提交方法进行改进,提出了一种结合MSCRS与MSERS的文本检测方法;(2)针对候选字符分类进行改进,提出了一种基于FASText与级联券积神经网络(Cascade ConyolutionalNeuralNetwork.C-CNN)的文本检测方法
针对街景影像文本通常会发生倾斜和透视变形的问题,提出一种基于图像特征变换的文本增强方法。该方法引入空间变换网络(SpatialTransfonmer NetworksSTN),该网络直接对文本检测结果区域对应的图像特征进行空间变换,而不是针对图像数据进行变换,这样既可以得到相当于文本处于水平并去除透视变形后的图像特征,同时还可以避免重复提取图像特征,提高网络模型效率,从而很好的解决文本存在旋转与透视变形问题,从而为文本识别提供可靠的候选文本。
针对街景影像背景复杂、文本结构、形状与颜色多变等特点,结合现有最新的目标检测与识别方法,提出了一种改进的 Mask R-CNN 的街景影像任意形状文本定位与识别方法研究。
本项目解决的关键技术问题有:
基于级联卷积神经网络的字符分类技术。高精度的字符分类是文本识别的关键,通过研究不同分辨率下的字符分类器,构建基于级联卷积神经网络的字符分类器,可以有效解决字符分类样本不平衡问题。
基于空间变换网络的候选文本增强技术。候选文本校正可以纠正文本存在的倾斜与透视变形等问题,是进行文本识别的关键。通过研究基于图像变换网络的文本增强方法可以为文本识别提供可靠输入,有效提高算法普适性。
基于改进 Mask R-CNN 的文本信息提取技术。以 Mask R-CNN 实例分割框架为基础,针对字符进行检测与识别的同时,增加一个用于文本识别的分支可以有效解决任意形状文本定位与识别问题,从而实现快速准确的街景影像文本信息提取。
本项目的主要创新包括:
提出基于深度学习的文本定位方法。利用基于级联卷积神经网络的深度学习理论,建立级联卷积神经网络的深度学习模型,可以快速准确的对候选字符进行分类,从而解决文本结构多变、背景复杂以及透视变形等因素导致难以提取候选字符过多且存在样本极度不平衡的问题。
提出基于端到端的文本信息提取方法。利用现有 Mask R-CNN 实例分割框架,针对文本与字符同进行检测,同时设计一个基于卷积循环神经网络文本识别子网络,可以有效提高文本定位与识别精度,能够有效解决任意形状文本定位与识别问题,从而实现街景影像文本快速准确提取。
(2)取得的主要研究进展、重要结果、关键数据等及其科学意义或应用前景
研究进展一: 快速准确的候选文本定位
针对现有候选字符提交方法进行改进,提出了一种结合MSCRS与MSERs的文本检测方法。传统基于最大稳定极值区域(MaximallyStable ExtremaRegions,MSERS)的候选字符提取通常将彩色RGB图像直接进行灰度化,或者是对其进行颜色空间转换后分通道进行候选字符提取,此方法并没有综合图像的颜色信息,而街景影像多为RGB 颜色模式,包含了丰富的颜色信息,直接丢弃颜色信息会导致候选字符提取召回率下降。为了解决这一问题,本研究将最大稳定颜色区域(Maximally Stable Color Regions,MSCRs)应用于候选字符提取,提出一种结合MSCRS与MSERS的文本检测方法,该方法同时使用MSCRS与MSERS算法提取候选字符区域,相对于使用单一的MSERS算法,可以提取出更多的真实字符区域,有效的提高了文本检测召回率。该研究方法流程如图1所示,其核心思想是:通过MSCRS与MSERS两种算法提取候选字符区域,并根据区域几何信息初步剔除部分背景区域;然后根据字符区域的纹理特征,训练字符分类器对候选字符区域进行分类,从而得到字符区域;最后利用区域彩色信息和几何邻接关系将字符进行合并,得到最终的文本区域。结合MSERS与MSCRs的自然场景图像文本定位分步效果示意图如图2所示。
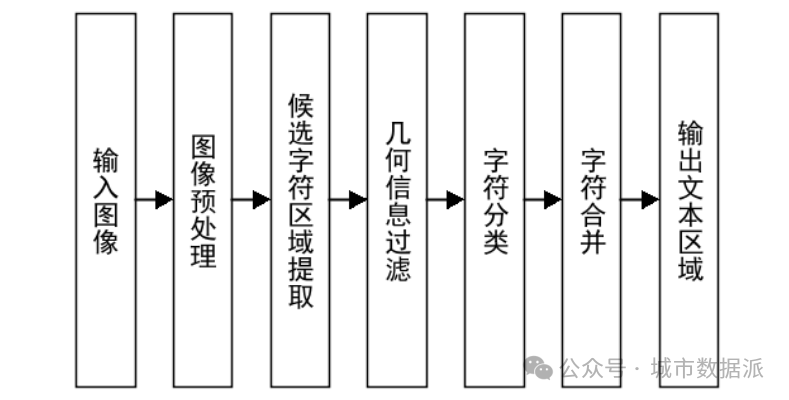
图1 结合MSERS与MSCRS的自然场景图像文本定位技术流程图

图2 结合MSERS与MSCRS的自然场景图像文本定位分步效果示意图
》针对候选字符分类进行改进,提出了一种基于FASText与级联卷积神经网络(Cascade Convolutional Neural Network,C-CNN)的文本检测方法。在进行候选字符提取时,无论是采用MSERS算法,还是MSCRS算法,亦或FASTex算法,其最终的候选字符总数依然会很大,并且由于街景影像中的文本结构与颜色等特征较为复杂,提取出来的候选字符不可避免地会包含非真实字符,且非真实字符数会远远大于真实字符数,因此训练字符二分类器时将面临严重的样本类别不均衡问题(class imbalance problem)。为了解决这一问题,本研究设计了两个不同分辨率的字符二分类器:16-net与32-net卷积神经网络分类器,将预训练的16-net与32-net卷积神经网络进行串联,组成一个级联卷积神经网络,并利用该级联卷积神经网络对候选字符进行分类,剔除候选字符中的非真实字符,得到最终的真实字符检测结果。其中16-net卷积神经网络的输入图像分辨率为16*16,利用16-net 网络可以快速剔除大部分的非真实字符,而32-net卷积神经网络的输入图像分辨率为32*32,该网络对经过16-net网络分类后,分类结果为字符的候选字符进行二次分类,从而得到最终的候选字符分类结果。该研究方法流程与其分步效果示意图分别如图3与图4所示。
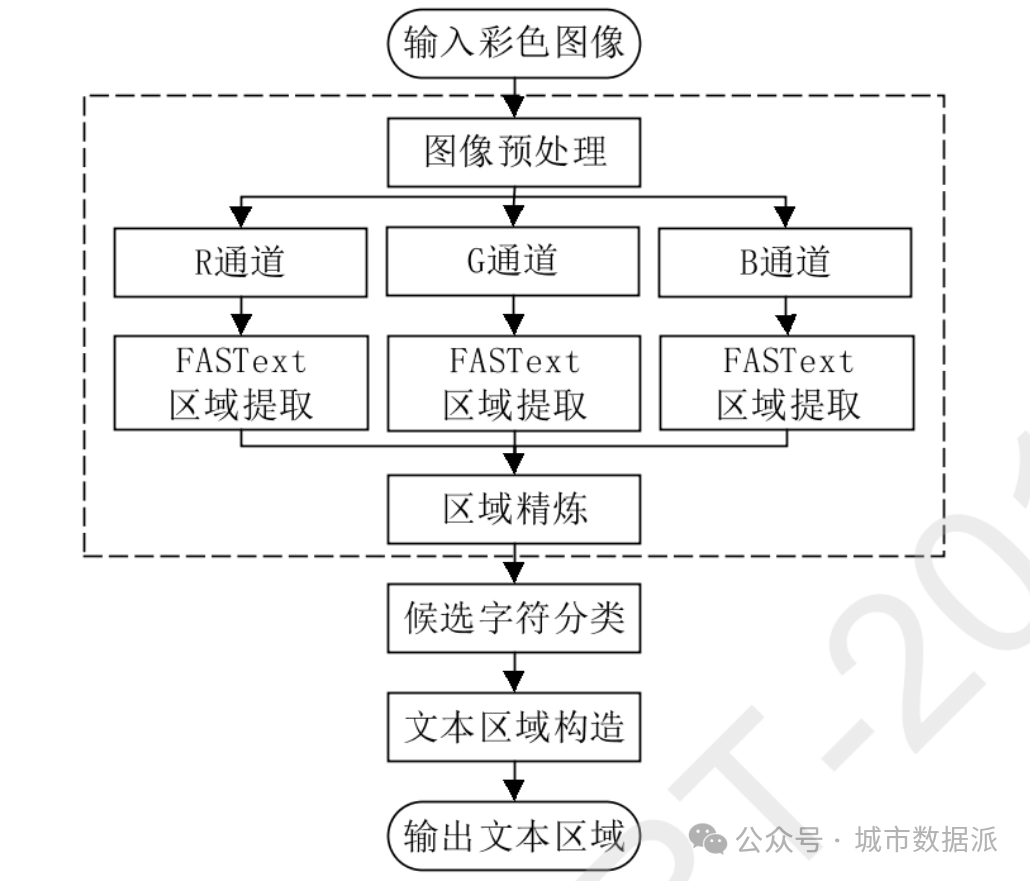
图3 基于FASText与级联卷积神经网络的街景影像文本定位方法流程图

图4 算法分步效果
针对现有文本检测方法存在的问题,提出了一种基于图像语义分割的多方向文本检测方法。无论是基于连通区域(ConnectedcomponentMethods),还是基于滑窗(Sliding-window Methods)的文本检测方法,都存在无法充分利用文本的结构与颜色特征,均会提取出大量的非字符区域作为候选字符,这会给后继的候选字符分类带来非常大的压力。为了解决这一问题,本研究先利用深度网络SegNet 网络对图像进行文本分割,通过图像分割可以去除图像大部分的背景区域,从而直接从图像中提取出文本块(textblock)的粗略位置,然后再采用传统基于连通区域的文本检测方法针对文本块进行文本检测。该方法的分步效果示意图以及语义分割网络如图5、图6所示。相关研究成果已形成论文,投稿至《Neurocomputing》,但是很不幸被拒稿。目前准备根据审稿意见对论文进行修改,修改稿计划投稿到《Information Processing& Management》。

图5 基于图像语义分割的多方向文本检测方法分步效果示意图
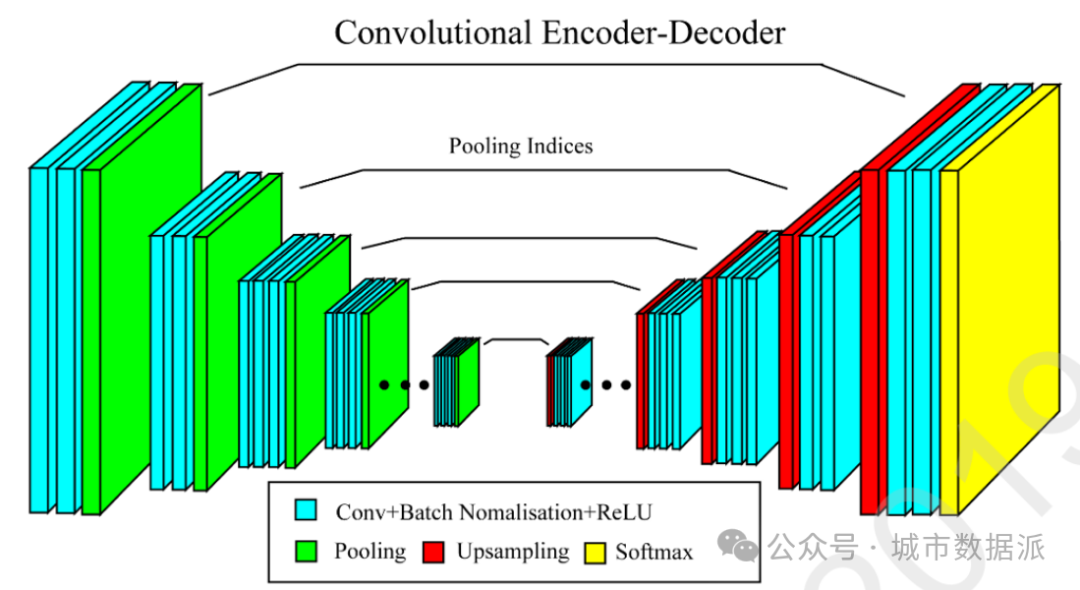
图6 图像语义分割网络
研究进展二: 基于图像特征变换的候选文本增强
针对街景影像文本通常会发生倾斜和透视变形的问题,提出一种基于图像特征变换的文本增强方法。传统文本图像增强方法通常是先获取文本图像的旋转角度,然后再对文本图像进行旋转使得文本处于水平方向,以便于后继的文本识别处理,但是该方法无法解决文本存在透视变形的问题。针对此问题,本研究引入空间变换网络(SpatialTransformer Networks,STN),该网络直接对文本检测结果区域对应的图像特征进行空间变换,而不是针对图像数据进行变换,这样既可以得到相当于文本处于水平并去除透视变形后的图像特征,同时还可以避免重复提取图像特征,提高网络模型效率,从而很好的解决文本存在旋转与透视变形问题。基于图像特征变换的候选文本增强示意图如图7所示,需要注意的是示意图显示的文本图像只是为了显示效果,在实际处理时是直接对图像特征进行处理。

图7 基于图像特征变换的候选文本增强示意图
研究进展三: 字符识别方法
与普通扫描文本图像相比,街景文本具有文本结构多变、背景复杂且经常存在透视变形等特点,直接将现有的光学字符识别技术(OpticalCharacte1Recognition,OCR)直接应用于街景影像文本识别的效果非常不理想。为此,本研究首先采用大津算法(Otsu)对文本块图像进行分块二值化,然后将二值化后的单个字符图像输入 TesseractOCR进行字符识别,最后结合文本图像的词典信息对识别结果进行修正,得到最终的文本识别结果。由于目前研究尚未利用深度学习模型训练字符识别器,而是直接采用Google开源Tesseract OCR 组件,因此字符识别结果并不理想,后继研究将设计并训练适用于街景图像的字符识别器。相关研究成果被《包装工程》接收(自然场景图像的字符识别方法研究,包装工程,2018年3月,第39卷第5期)。该方法的算法流程图与其效果示意图分别如图8、图9所示。
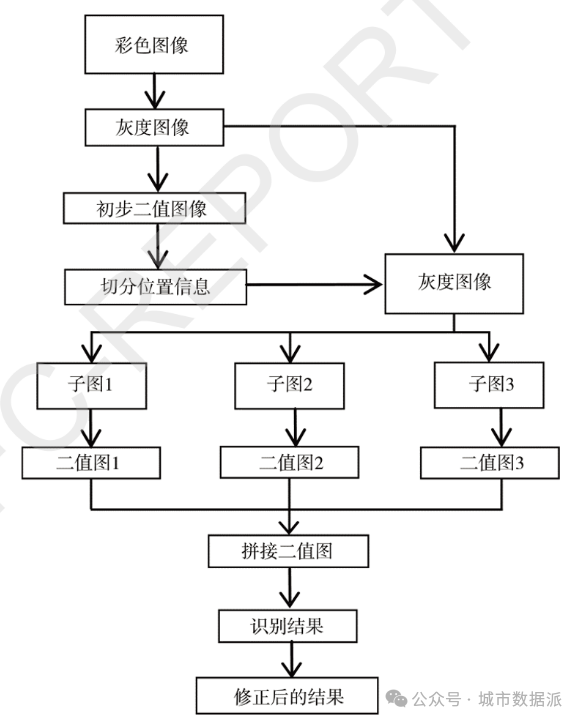
图8 文本识别算法流程图

图9 图像分割效果示意图
研究进展四: 端到端的任意形状文本信息提取
针对街景影像背景复杂、文本结构、形状与颜色多变等特点,结合现有最新的目标检测与识别方法,提出了一种改进的 Mask R-CNN 的街景影像任意形状文本定位与识别方法研究。该部分研究分为两个阶段:
......
还有更多成果内容,详见项目结题成果报告。该项目报告共计27页,关注城市数据派微信公众号,在微信公众号对话框中输入24815,即可获得报告全文PDF的下载方式。
最近有朋友问我们:为什么没有及时看到推文?因为微信改了推送规则,没有点“赞”或
“在看”,没有把我们“星标”,都有可能出现这种状况。加“星标”,不迷路!看完文章顺手点点“赞”或“在看”,就可以准时与我们见面了~









