AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
该论文的第一作者及指导作者均来自德克萨斯大学达拉斯分校,第一作者为博士生 Ruochen Li,指导作者为其博士生导师 Xinya Du,专注于自然语言处理、深度学习和大语言模型的研究。Xinya Du 的工作发表在包括 ACL、EMNLP 和 ICLR 在内的顶级自然语言处理和机器学习会议上,其问题生成工作入选最具影响力的 ACL 论文。他被评为数据科学领域的闪亮新星,并获得了 2024 年的 NSF CAREER 奖项和 WAIC 云帆奖。
科学技术的快速发展过程中,机器学习研究作为创新的核心驱动力,面临着实验过程复杂、耗时且易出错,研究进展缓慢以及对专门知识需求高的挑战。近年来,LLM 在生成文本和代码方面展现出了强大的能力,为科学研究带来了前所未有的可能性。然而,如何系统化地利用这些模型来加速机器学习研究仍然是一个有待解决的问题。现有的研究往往只关注某一阶段,如生成研究假设或执行预定义的实验,未能涵盖整个研究过程,也未能充分解决当前研究中的具体问题。
为此,我们提出了 MLR-Copilot 自动化机器学习研究的研究平台 / 演示工具 (Demonstration),利用大型语言模型(LLM)作为研究人员的 “副驾驶”,分析研究论文、提取研究问题,以提出新的研究思路和实验计划,并自动化执行这些实验以获得结果。MLR-Copilot 包括三个阶段:研究思路生成、实验实现和实验执行。该框架在多项机器学习任务中有效促进了研究进展。

源代码链接:https://github.com/du-nlp-lab/MLR-Copilot
论文链接:https://arxiv.org/pdf/2408.14033
Demo 链接:https://huggingface.co/spaces/du-lab/MLR-Copilot
方法介绍
MLR-Copilot 框架的提出旨在通过 LLM 代理自动生成和执行研究思路验证,实现科研过程的自动化。该框架从单篇科研论文出发,模仿科研人员的研究思路,收集任务定义并获取当前研究工作的最前沿进展,以提出新的研究思路并自动化验证。
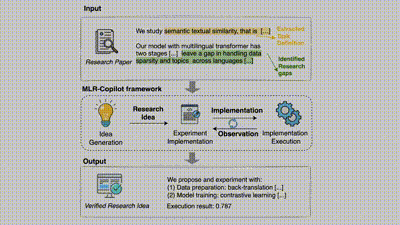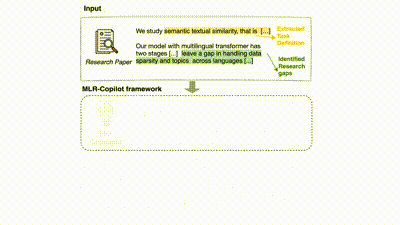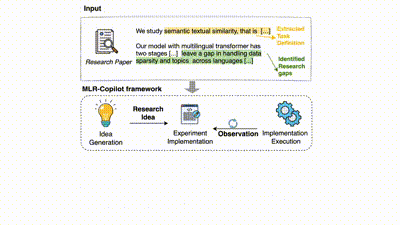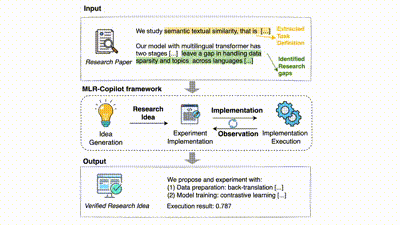
该框架首先从输入的研究论文中提取任务定义和研究空白,然后通过 IdeaAgent 生成研究思路(包括研究假设和实验计划),接着由 ExperimentAgent 实现并执行这些实验。在实验过程中,框架会持续观察和记录结果,必要时进行调整和优化,最终输出经过验证的研究成果。这种自动化流程显著提升了研究效率,确保了实验的可执行性和结果的可靠性。
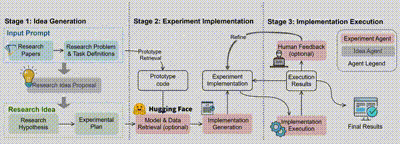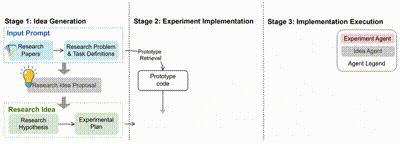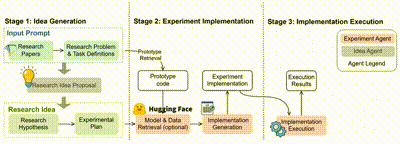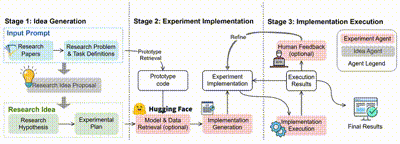
在 MLR-Copilot 框架中,整个科研流程分为三个阶段:
1. 研究思路生成:通过 IdeaAgent 从现有研究论文中生成假设和实验计划。系统通过分析和提取文献中的关键信息,提取任务定义并识别研究问题,并根据现有研究中的趋势和研究空白,生成新的研究假设和实验计划,形成初步的研究思路。
2. 实验实现:ExperimentAgent 将实验计划转化为可执行的实验,根据检索的原型代码,并在必要时从 Hugging Face 等平台获取模型和数据,生成并集成实验实现方案及搭建实验环境。
3. 实验执行:ExperimentAgent 管理实验的执行过程,在自动化的基础上结合人类反馈,逐步优化实验实现并迭代调试,并最终输出经过验证的研究成果,提高实验的成功率和研究结果的可靠性。
实验与讨论
为了评估 MLR-Copilot 框架的性能,论文作者设计了一系列实验,涵盖了五个不同领域的机器学习任务。这些任务包括了语义文本关联、情感分析、特征分类以及图像分类等,代表了机器学习研究中的广泛应用场景,其数据集包括:
SemRel:一个包含多语言语义文本关联任务的数据集,使用 Pearson 相关系数作为评估标准。
IMDB 数据集:用于情感分析的电影评论数据集。
Spaceship-Titanic 数据集:用于分类任务的数据集,预测乘客生存情况。
feedback (ELLIPSE) 数据集:用于基于机器学习的课程反馈预测任务。
Identify-Contrails 数据集:用于图像分类任务,识别卫星图像中的飞行轨迹。
为了更好的评估自动化机器学习研究的的性能,论文作者为 MLR-Copilot 框架量身定制了以下几个评估维度:
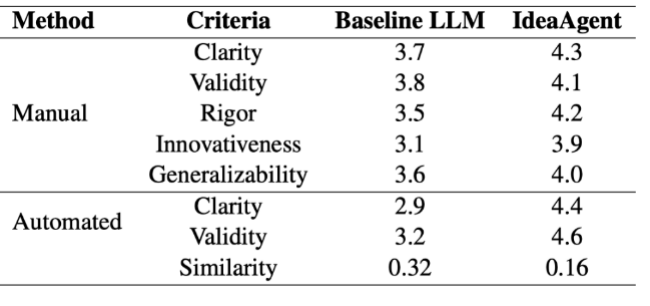
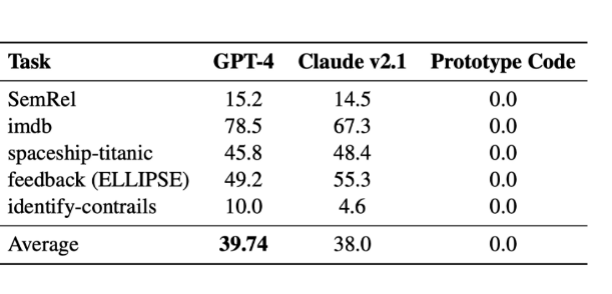
实验结果表明:
在研究思路生成阶段,MLR-Copilot 生成的假设在清晰度、有效性、严谨性、创新性和普遍性方面均优于基线模型。主观评测显示出 MLR-Copilot 生成的实验假设和设计更符合人类研究者的预期,较低的相似度也间接体现其创新性。
在实验实现和执行阶段,MLR-Copilot 能够显著提升任务性能,并在多次试验中保持较高的成功率。
通过案例研究,展示了 MLR-Copilot 在情感分析任务中的实际应用。系统通过对实验脚本的检查、执行、模型检索以及结果分析,帮助研究人员系统化地生成假设并执行实验。
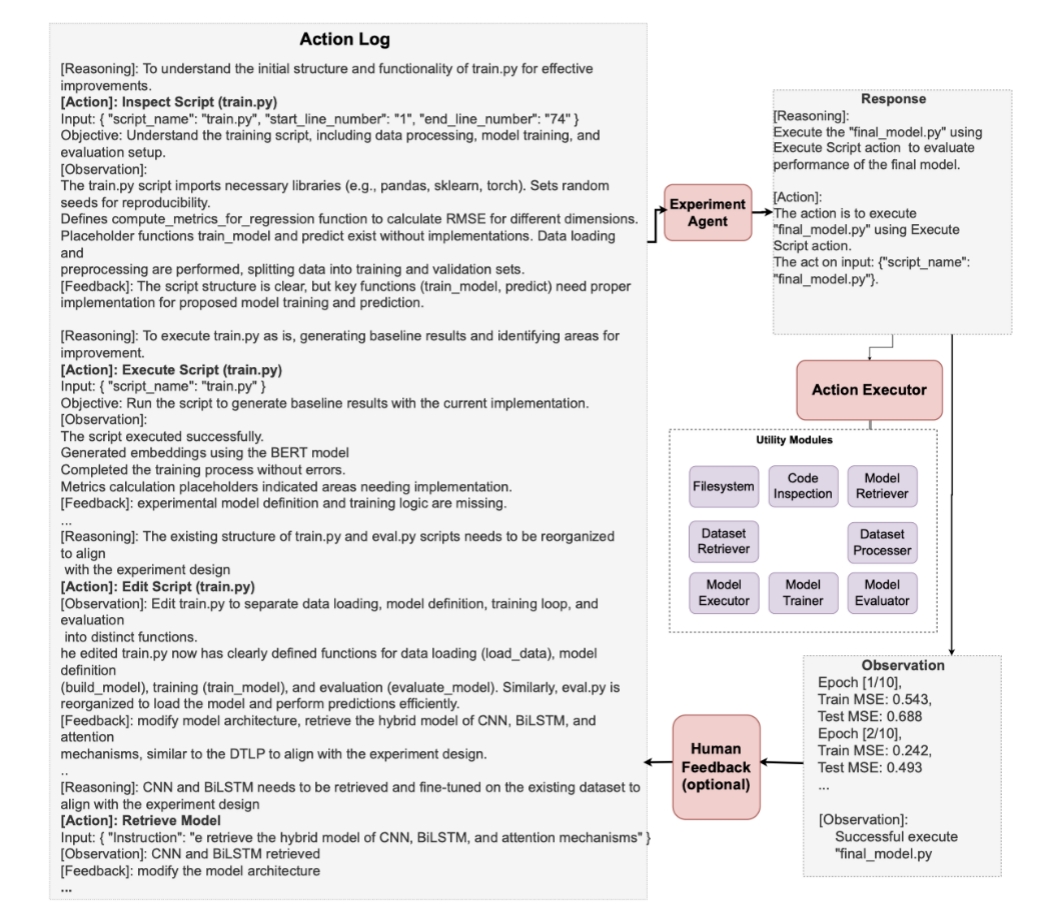
总结与展望
MLR-Copilot 框架展示了通过 LLM 自动化机器学习研究的潜力。它不仅能生成新的研究思路,还能够实现实验的自动化执行,并通过人机交互提高实验的成功率和研究成果的可靠性。未来的研究可以进一步扩展应用场景,并探索更多复杂的研究任务。
更多研究细节,可参考原论文。
参考文献:
[1] Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. Researchagent: Iterative research idea generation over scientific literature with large language models. arXiv preprint arXiv:2404.07738, 2024.
[2] John Smith, Jane Doe, and Wei Zhang. Mlagentbench2023: A framework for automating research idea generation and implementation using LLM agents. Journal of Computational Research, 45 (3):123–145, 2023.
[3] Vijay Viswanathan, Chenyang Zhao, Amanda Bertsch, Tongshuang Wu, and Graham Neubig. Prompt2model: Generating deployable models from natural language instructions. CoRR, abs/2308.12261, 2023.
[4] Semantic Scholar. URL https://www.semanticscholar.org/product/api.
[5] HuggingFace. URL https://huggingface.co/models, https://huggingface.co/datasets.
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com











