
哈希(Hash)是一种将数据转换为固定大小的字符串或数字的过程,这个结果通常被称为哈希值或哈希码。在计算机科学中,哈希广泛用于数据存储、查找、验证等场景。哈希函数被设计用来均匀分布数据,使得数据搜索和存储更加高效。无论是在构建高效的数据结构如哈希表、字典、集合,还是在确保数据完整性与安全性(如密码存储和加密算法)方面,哈希技术都扮演着至关重要的角色。
接下来我们了解Python中的哈希(Hash),包括哈希函数(hash functions)、代码示例以及实际应用案例。
哈希(Hashing)简介
哈希(Hash)是一种将数据转换为固定大小字符串或数字的过程,这个结果通常被称为哈希值或哈希码。哈希函数的设计目标是均匀地分布数据,从而提升数据的搜索、存储和验证效率。在计算机科学中,哈希在数据索引和检索中起着至关重要的作用。它被广泛应用于哈希表、字典和集合等数据结构中,用于快速查找。此外,哈希还用于确保数据的完整性,防止信息被篡改,同时在密码存储等敏感信息的安全性方面发挥关键作用。由此可见,哈希在计算机科学中的应用极为广泛且重要。
哈希的常见应用包括:
数据存储:哈希用于哈希表中,实现高效的数据存储和快速检索。
数据完整性:通过生成唯一的哈希值,哈希可以确保数据在传输或存储过程中未被篡改。
安全性:在密码存储和加密算法中,哈希是确保数据安全的核心技术。
理解哈希函数(Hash Function)
哈希函数(Hash Function)接收输入并生成一个固定大小的哈希码。一个好的哈希函数应确保不同的输入生成唯一的哈希值,并将数据均匀分布在可用的哈希空间中。
好的哈希函数的特性
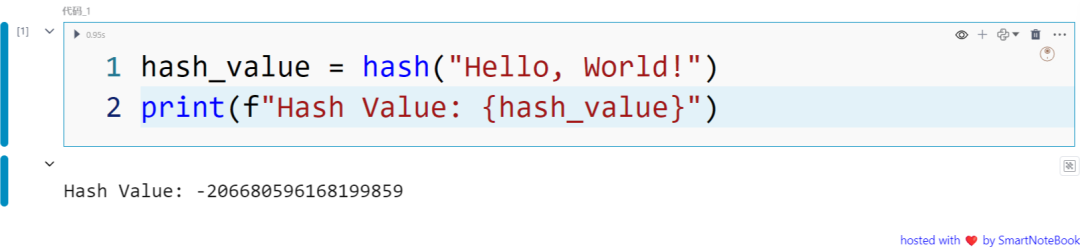
Python 提供了内置的 hash() 函数,用于生成对象的哈希值。
哈希冲突:原因及处理
哈希冲突是指两个不同的输入生成了相同的哈希值。由于哈希函数的输出大小是固定的,而输入可以是任意大小的数据,因此特别是在处理大数据集时,始终存在发生冲突的可能性。
哈希冲突的原因
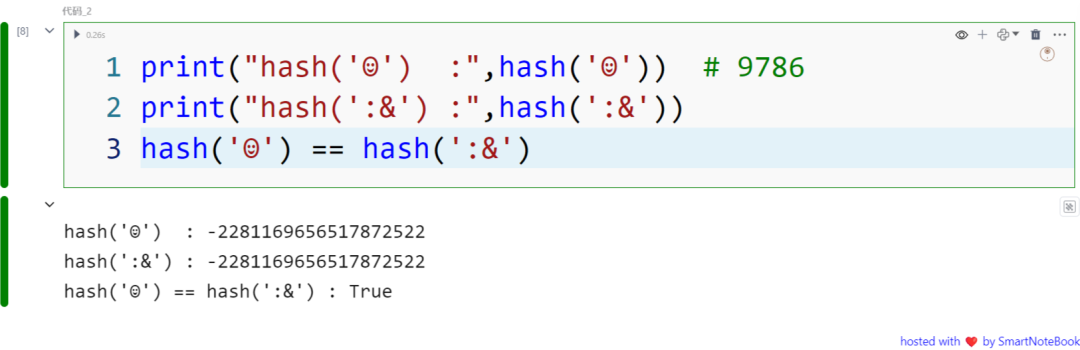
我们看一个使用Python内置的 hash() 函数时导致冲突的例子(虽然这种情况不常见):
print("hash('☺') :",hash('☺')) print("hash(':&') :",hash(':&'))hash('☺') == hash(':&')
当哈希冲突发生时,有几种常见的处理方法:
哈希算法
哈希算法是哈希过程的核心,决定了输入数据如何被转换为固定大小的哈希值。常见的哈希算法各自具有不同的特性、用途和安全级别。以下是最常用的哈希算法、在 Python 中使用 hashlib 库进行示例。
MD5(Message Digest Algorithm 5):
SHA-1(Secure Hash Algorithm 1): SHA-256(Secure Hash Algorithm 256):这些哈希算法通过应用一系列数学运算(如位移、逻辑运算(如异或)和消息压缩)处理输入数据。每个算法为每个输入生成唯一的固定大小输出(哈希),并且设计时确保即使输入有极小的变化,也会产生完全不同的哈希值。
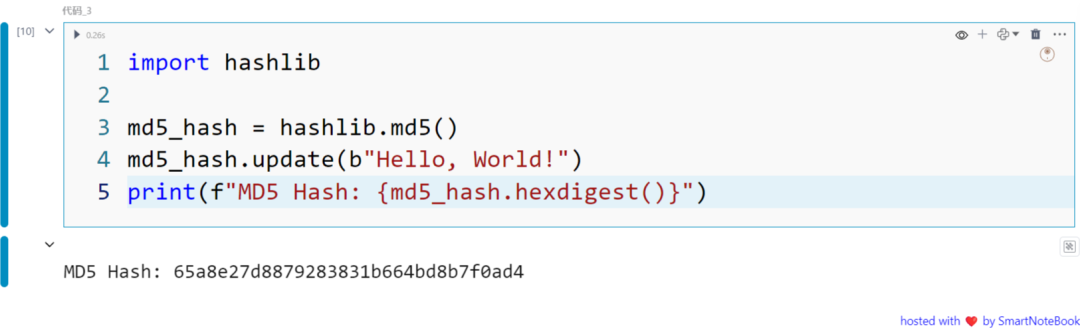
示例1: Hashing with MD5
import hashlib
md5_hash = hashlib.md5()md5_hash.update(b"Hello, World!")print(f"MD5 Hash: {md5_hash.hexdigest()}")
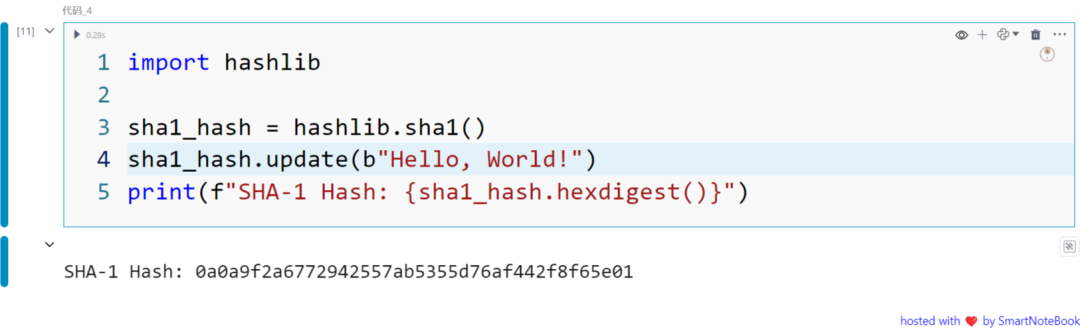
示例2: Hashing with SHA-1
import hashlib
sha1_hash = hashlib.sha1()sha1_hash.update(b"Hello, World!")print(f"SHA-1 Hash: {sha1_hash.hexdigest()}")
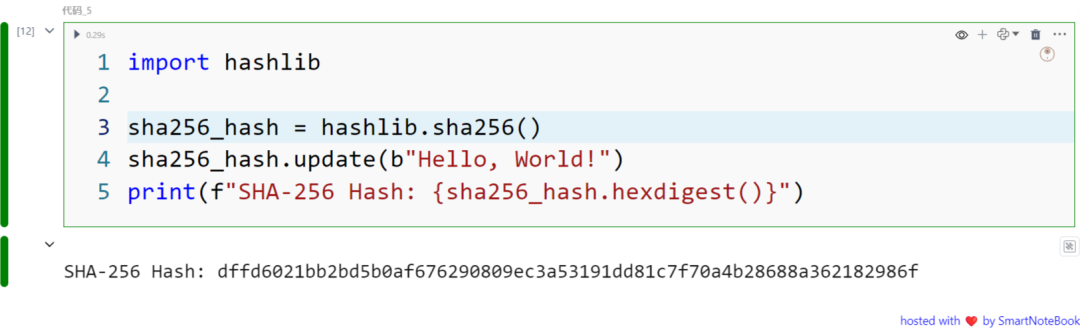
示例3: Hashing with SHA-256
import hashlib
sha256_hash = hashlib.sha256()sha256_hash.update(b"Hello, World!")print(f"SHA-256 Hash: {sha256_hash.hexdigest()}")
三者应用场景的差别:
MD5:适用于非安全应用,例如生成文件校验和、快速比较或低风险的完整性检查。不要将 MD5 用于保护敏感信息,如密码。
SHA-1:仍在遗留系统中使用,但通常应避免使用,建议选择更强的算法,如 SHA-256。
SHA-256:最适合安全关键应用,包括存储哈希密码、验证数字签名或保护区块链交易。
哈希算法的关键特性
确定性:相同的输入始终会产生相同的哈希值。
固定输出大小:哈希值的大小始终是固定的,与输入大小无关。
高效性:哈希函数处理速度快,能够快速处理大量数据。
抗碰撞性:一个好的哈希算法可以最大限度地减少碰撞(不同输入产生相同哈希值的情况)。
预映像抗性:计算上应该不可行从哈希值反推原始输入。
输入微小变化会导致输出显著变化:即使输入发生微小变化,也会导致生成完全不同的哈希值。
哈希(hashing)安全性中的盐(Salting)
在安全性上下文中,盐(salting)是指将随机数据(称为“盐”)添加到哈希函数的输入中。盐的目的在于使每个哈希值唯一,即使相同的输入被提供。这在密码哈希的情况下尤为重要,因为它有助于防御诸如彩虹表攻击等攻击方式,攻击者预先计算了常用密码的哈希值。
例如:当盐被添加到密码中进行哈希时,即使两个用户使用相同的密码,由于使用了不同的盐,它们的哈希密码也会有所不同。这样,即使攻击者得到了哈希值,他们也无法通过查找预先计算的哈希值来轻易破解密码,因为每个哈希值都是独特的。
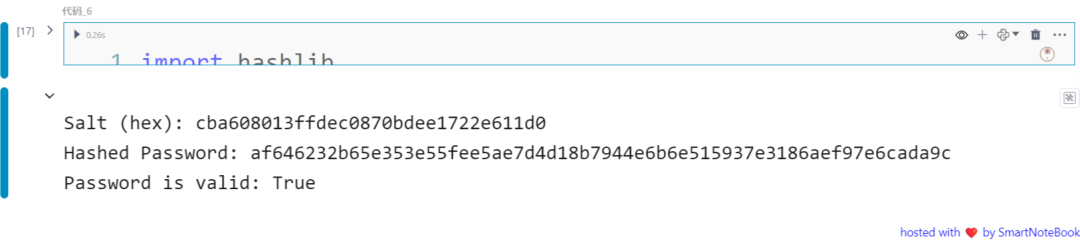
下面是一个使用sha256 和盐(随机盐)的hash 密码的示例:
import hashlibimport os
def salted_hash(password): salt = os.urandom(16) hash_sha256 = hashlib.sha256() hash_sha256.update(salt + password.encode('utf-8')) return salt, hash_sha256.hexdigest()
password = "password"salt, hash_value = salted_hash(password)
print(f"Salt (hex): {salt.hex()}")print(f"Hashed Password: {hash_value}")
def verify_password(stored_salt, stored_hash, password): hash_sha256 = hashlib.sha256() hash_sha256.update(stored_salt + password.encode('utf-8')) return hash_sha256.hexdigest() == stored_hash
is_valid = verify_password(salt, hash_value, "password")print(f"Password is valid: {is_valid}")
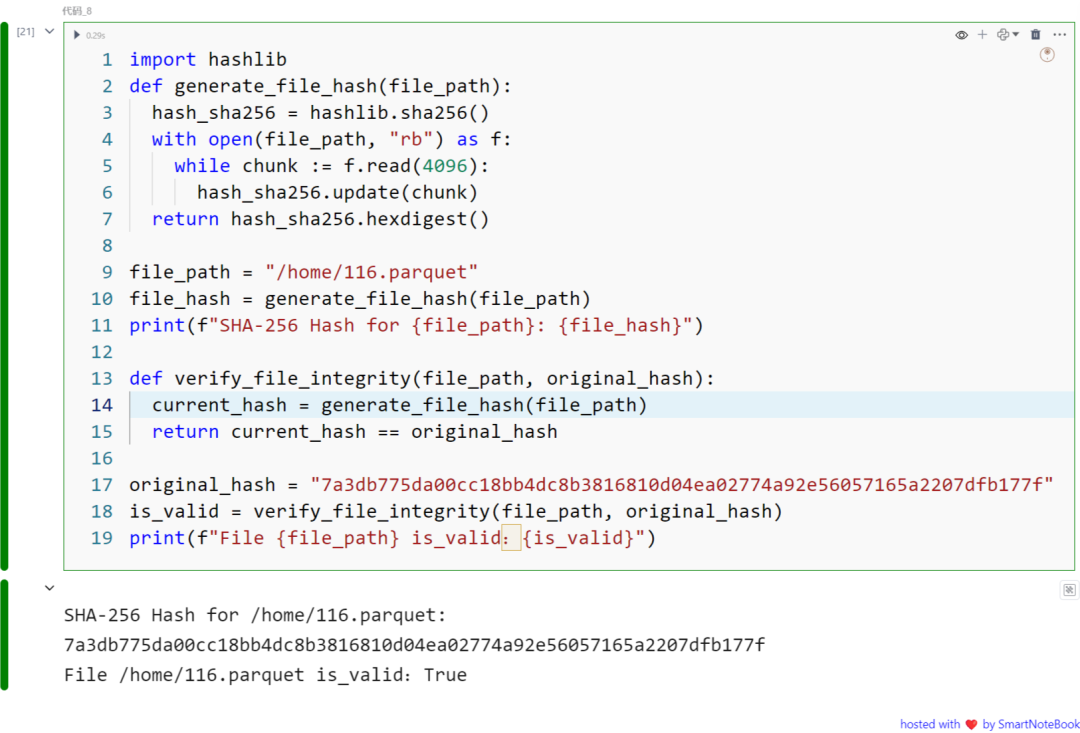
示例:使用哈希验证文件完整性
让我们看一个实际的例子,为文件生成哈希值,然后验证该文件是否未被更改。这在从互联网下载软件时特别有用,因为开发人员通常会提供校验和,用户可以将其与下载的文件进行比较。
import hashlibdef generate_file_hash(file_path): hash_sha256 = hashlib.sha256() with open(file_path, "rb") as f: while chunk := f.read(4096): hash_sha256.update(chunk) return hash_sha256.hexdigest()
file_path = "/home/116.parquet" file_hash = generate_file_hash(file_path)print(f"SHA-256 Hash for {file_path}: {file_hash}")
def verify_file_integrity(file_path, original_hash): current_hash = generate_file_hash(file_path) return current_hash == original_hash
original_hash = "7a3db775da00cc18bb4dc8b3816810d04ea02774a92e56057165a2207dfb177f" is_valid = verify_file_integrity(file_path, original_hash)print(f"File {file_path} is_valid:{is_valid}")
Python 中的哈希算法是实现高效数据管理和安全性的必备工具。Python 的内置函数hash()以及hashlib模块提供了强大的功能,可以在各种应用程序中实现哈希算法。从使用加盐哈希保护密码到验证数据完整性,掌握哈希算法可以极大地提高您的开发技能。











