在深度学习中,前向传播是神经网络从输入到输出计算预测值的过程,负责将输入数据通过网络中的各层神经元进行计算和转换,最终输出预测值。这个过程是神经网络进行训练和推理的基础,也是后续反向传播过程的前提。反向传播则是根据损失函数计算梯度并更新网络参数以优化模型性能的过程,通过计算损失函数对权重的梯度,来调整权重和偏置,以最小化损失函数并提高模型的预测准确性。
前向传播(Forward Propagation
)是什么?前向传播是神经网络通过逐层计算,从输入层开始,经过隐藏层,最终到达输出层,以产生预测值的过程。在这个过程中,输入数据通过网络中的权重和偏置进行线性变换,然后通过激活函数进行非线性变换,得到每一层的输出。最终,输出层的输出即为神经网络的预测值。输入层接收数据:输入层是神经网络的第一层,它接收来自外部的数据。
计算隐藏层输出:数据从输入层传递到隐藏层,隐藏层中的每个神经元都会接收来自上一层神经元的输入,并计算其加权和。加权和通过激活函数(如ReLU、Sigmoid、Tanh等)进行非线性变换,生成该神经元的输出。
计算输出层输出:输出层是神经网络的最后一层,它接收来自隐藏层(或直接从输入层,如果网络没有隐藏层)的输入,并计算最终的输出。
“前向传播是神经网络通过逐层线性变换与非线性激活,从输入层传递数据至输出层,以生成预测值的过程。”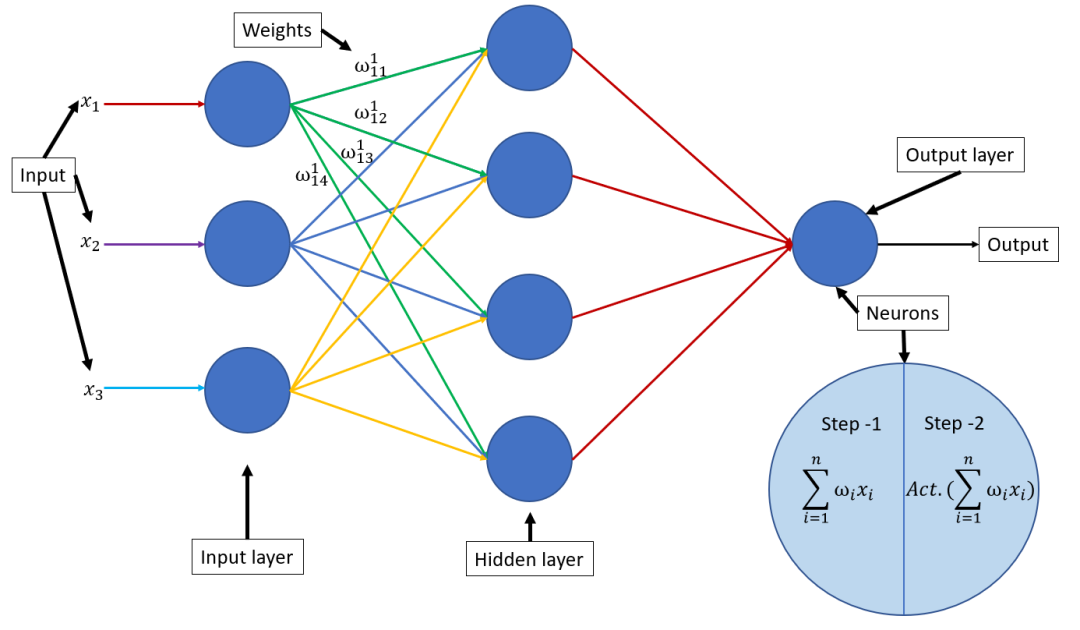
反向传播(Backward Propagation)是什么?
反向传播则是神经网络训练过程中的一个关键步骤,它用于根据损失函数计算梯度,并据此更新网络的权重和偏置。在反向传播过程中,我们从输出层开始,逐层计算每个神经元的误差项(即损失函数对该层激活值的导数),然后利用这些误差项和前一层的激活值来计算当前层权重的梯度
。最后,使用这些梯度,通过优化算法(如梯度下降)更新网络的参数,以减小损失函数的值。1. 计算误差(损失函数)
在神经网络的训练过程中,我们需要一个衡量模型预测输出与真实输出之间差异的标准,这个标准就是损失函数。常见的损失函数包括均方误差(MSE)、交叉熵损失(Cross-Entropy Loss)等。
2. 计算梯度
得到损失函数后,我们需要利用链式法则(Chain Rule)将损失函数的值反向传播到网络的每一层,并计算每个权重的梯度。梯度表示了损失函数相对于每个权重的变化率,它指导我们如何调整权重以减小损失函数的值。
3. 更新参数
得到每个权重的梯度后,我们可以使用梯度下降(Gradient Descent)等优化算法来更新网络的权重和偏置。梯度下降算法的基本思想是沿着梯度的反方向更新权重,以减小损失函数的值。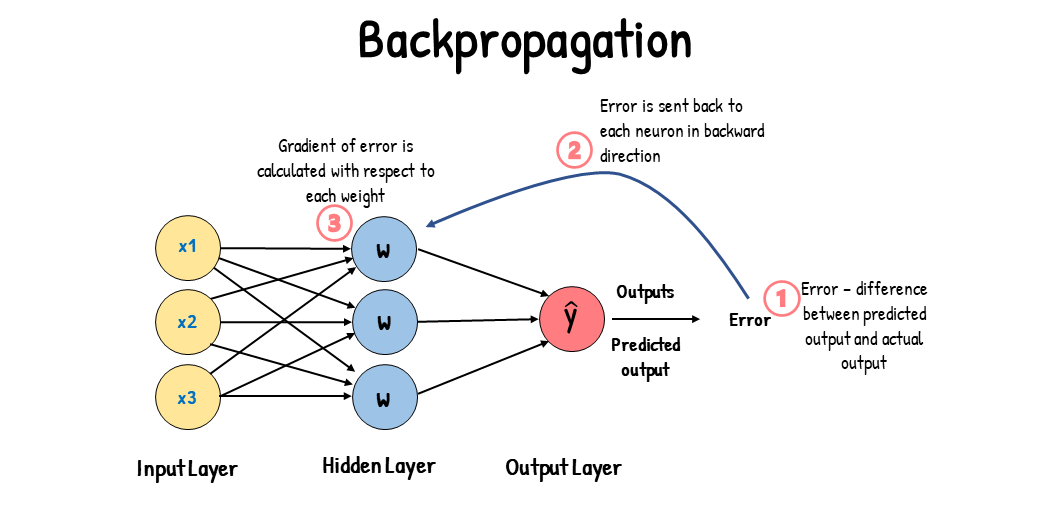
“一图 + 一句话”彻底搞懂反向传播。
“反向传播通过计算损失函数对权重的梯度,并利用链式法则逐层反向传播误差,最后使用优化算法更新网络参数,以最小化损失函数。”









