本文约3000字,建议阅读10分钟
时间序列数据的高维特性和复杂的时间依赖关系使其分析具有挑战性。
在现代数据分析领域,时间序列数据的处理和预测一直是一个具有挑战性的问题。随着物联网设备、金融交易系统和工业传感器的普及,我们面临着越来越多的高维时间序列数据。这些数据不仅维度高,而且往往包含复杂的时间依赖关系和潜在模式。传统的时间序列分析方法如移动平均等,在处理此类数据时往往显得力不从心。基于矩阵分解的长期事件(Matrix Factorization for Long-term Events, MFLEs)分析技术应运而生。这种方法结合了矩阵分解的降维能力和时间序列分析的特性,为处理大规模时间序列数据提供了一个有效的解决方案。核心概念
矩阵分解
矩阵分解(Matrix Factorization)是将一个矩阵分解为多个基础矩阵的乘积的过程。在时间序列分析中,最常用的是奇异值分解(Singular Value Decomposition, SVD)。SVD可以将原始矩阵 A 分解为:
潜在变量与潜在特征
- 潜在变量(Latent Variables):指数据中无法直接观测但实际存在的变量,它们往往是多个可观测变量的综合表现。
- 潜在特征(Latent Features):通过矩阵分解得到的低维表示,它们是潜在变量在数学上的具体体现。每个潜在特征可能代表多个原始特征的组合。
维度降低在时间序列分析中的意义
维度降低(Dimensionality Reduction)在时间序列分析中具有多重意义:- 原始维度下的计算复杂度:O(n^3),其中n为特征数量;
- 降维后的计算复杂度:O(k^3),其中k为降低后的维度数,通常k << n;
主成分分析(PCA)与MFLE的关系
主成分分析(Principal Component Analysis, PCA)是一种经典的降维方法,而MFLE可以看作是PCA在时间序列领域的扩展应用。与PCA相比,MFLE具有以下特点:
MFLE的数学基础
MFLE的核心思想是将时间序列数据矩阵 X ∈ ℝ^(m×n) 分解为两个低维矩阵的乘积:- W ∈ ℝ^(m×k) 表示基矩阵(basis matrix)
- H ∈ ℝ^(k×n) 表示编码矩阵(encoding matrix)
- k 是潜在特征的数量,通常 k << min(m,n)
min ||X - WH||F^2 + λ(||W||F^2 + ||H||_F^2)
长期事件(MFLEs)技术实现
数据准备与预处理:
import numpy as np import pandas as pd from sklearn.decomposition import TruncatedSVD from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt
# 生成合成数据 np.random.seed(42) n_series = 100 # 时间序列的数量 n_timepoints = 50 # 时间点的数量 # 模拟数据矩阵(行:时间序列,列:时间点) data_matrix = np.random.rand(n_series, n_timepoints) df = pd.DataFrame(data_matrix) print(df.head())
在这个实现中,我们选择了100个时间序列,每个序列包含50个时间点。这些参数的选择基于以下考虑:- n_series = 100:提供足够的样本量以捕获不同的模式;
- n_timepoints = 50:足够长以体现时间序列的特性,又不会造成过大的计算负担。
矩阵分解实现
svd = TruncatedSVD(n_components=10) # 降至10个潜在特征 latent_features = svd.fit_transform(data_matrix) # 重构时间序列 reconstructed_matrix = svd.inverse_transform(latent_features)
-
选择理由:通常选择能解释80-90%方差的特征数量
- 最佳实践:可以通过explained_variance_ratio_确定
预测模型构建
# 准备训练和测试数据集 X = latent_features[:, :-1] y = latent_features[:, -1] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 训练回归模型 model = LinearRegression() model.fit(X_train, y_train) # 进行预测 y_pred = model.predict(X_test)
可视化分析
""" 原始与重构时间序列的对比 """ import matplotlib.pyplot as plt # 绘制原始与重构时间序列的对比图 series_idx = 0 # 选择特定的时间序列 plt.figure(figsize=(10, 6)) plt.plot(data_matrix[series_idx, :], label="Original", marker="o") plt.plot(reconstructed_matrix[series_idx, :], label="Reconstructed", linestyle="--") plt.title("MFLE: Original vs Reconstructed Time Series") plt.xlabel("Time") plt.ylabel("Values") plt.legend() plt.grid() plt.show()

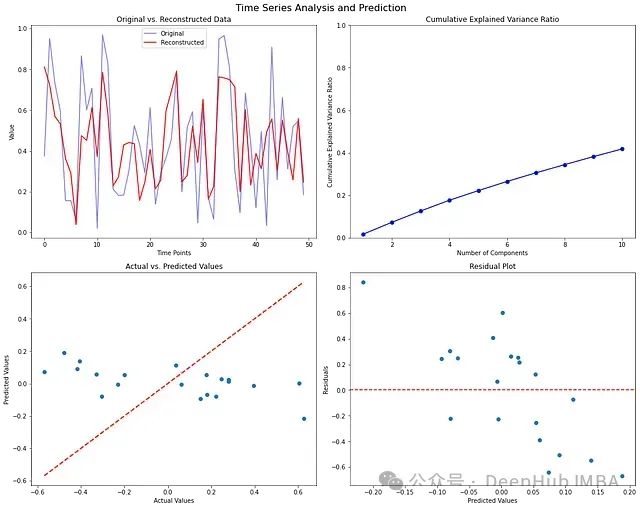
import matplotlib.pyplot as plt import seaborn as sns # 设置绘图 fig, axes = plt.subplots(2, 2, figsize=(15, 12)) fig.suptitle('Time Series Analysis and Prediction', fontsize=16) # 1. 原始数据与重构数据对比(第一个时间序列) axes[0, 0].plot(data_matrix[:1].T, 'b-', alpha=0.5, label='Original') axes[0, 0].plot(reconstructed_matrix[:1].T, color="Red", label='Reconstructed') axes[0, 0].set_title('Original vs. Reconstructed Data') axes[0, 0].set_xlabel('Time Points') axes[0, 0].set_ylabel('Value') axes[0, 0].legend() # 2. 解释方差比 explained_variance_ratio = svd.explained_variance_ratio_ cumulative_variance_ratio = np.cumsum(explained_variance_ratio) axes[0, 1].plot(range(1, len(explained_variance_ratio) + 1), cumulative_variance_ratio, 'bo-') axes[0, 1].set_title('Cumulative Explained Variance Ratio') axes[0, 1].set_xlabel('Number of Components') axes[0, 1].set_ylabel('Cumulative Explained Variance Ratio') axes[0, 1].set_ylim([0, 1]) # 3. 实际值与预测值对比 axes[1, 0].scatter(y_test, y_pred) axes[1, 0].plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', lw=2) axes[1, 0].set_title('Actual vs. Predicted Values') axes[1, 0].set_xlabel('Actual Values') axes[1, 0].set_ylabel('Predicted Values') # 4. 残差图 residuals = y_test - y_pred axes[1, 1].scatter(y_pred, residuals) axes[1, 1].axhline(y=0, color='r', linestyle='--') axes[1, 1].set_title('Residual Plot') axes[1, 1].set_xlabel('Predicted Values') axes[1, 1].set_ylabel('Residuals') plt.tight_layout() plt.show()
与其他时间序列分析方法对比
传统统计方法对比
深度学习方法对比
总结
时间序列数据的高维特性和复杂的时间依赖关系使其分析具有挑战性。MFLE通过结合矩阵分解和时间序列分析的优势,为这类问题提供了一个有效的解决方案。通过对MFLE的深入理解和合理应用,可以在众多实际场景中获得良好的分析效果。未来随着算法的改进和计算能力的提升,MFLE的应用范围将进一步扩大。








