机器人规划与控制研究所 ——机器人/自动驾驶规划与控制方向综合、全面、专业的平台。3万人订阅的微信大号。点击标题下蓝字“机器人规划与控制研究所”关注,我们将为您提供有价值、有深度的延伸阅读。
想象一下,你试图在拥挤的房间里穿行而不撞到行人或家具。你的大脑会不断规划你的路径,根据人们的移动进行调整,并找到到达目的地的最高效路线。这本质上就是运动规划对机器人、自动驾驶汽车,甚至电子游戏中的角色所起的作用。
运动规划是指在避开障碍物的同时,找到一条从 A 点到 B 点的安全高效路径。传统上,这是使用固定的数学公式和算法来实现的。现在,借助机器学习 (ML),这些系统可以从经验中学习并适应新情况——就像人类一样!
让我们用简单的术语来探讨一下它的工作原理。
什么是“配置空间”?
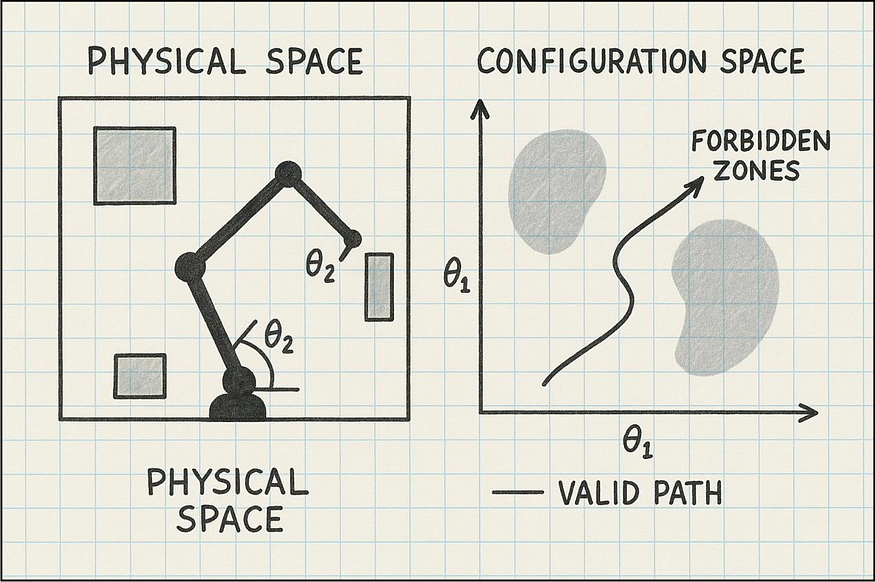
配置空间将“配置空间”(C 空间)视为机器人可能处于的所有位置的地图。
例如,如果你有一个机械臂,它的配置空间包含每个关节所有可能的角度。如果你有一辆车,它的配置空间包含所有可能的位置(x,y坐标)和方向(它面向哪个方向)。
在这个空间中,障碍物被视为机器人无法进入的“禁区”。运动规划的目标是找到一条从起点到终点穿过“允许区”的路径。
2.1 基于图的规划
可以将其想象成一张标有道路和交叉路口的地图。规划器会查看所有可能的路线,并选择最佳路线。
Dijkstra 算法的工作原理就像水从起点流出一样——它会向各个方向均匀扩散,直到到达目的地。

Dijkstra算法Dijkstra算法的工作原理:
- 它从起点开始,并以零距离标记
- 它探索邻近点并分配它们距离(迄今为止的成本+到达该点的成本)
- 它总是探索下一个总距离最小的未访问点
- 一旦到达目标,它就会回溯路径以找到最短路线
- 它保证最短路径,但会探索所有方向,效率低下
2.1.2 A* 算法
A*(发音为“A-star”)类似于 Dijkstra,但更智能——它使用“最佳猜测”来决定首先探索哪个方向。
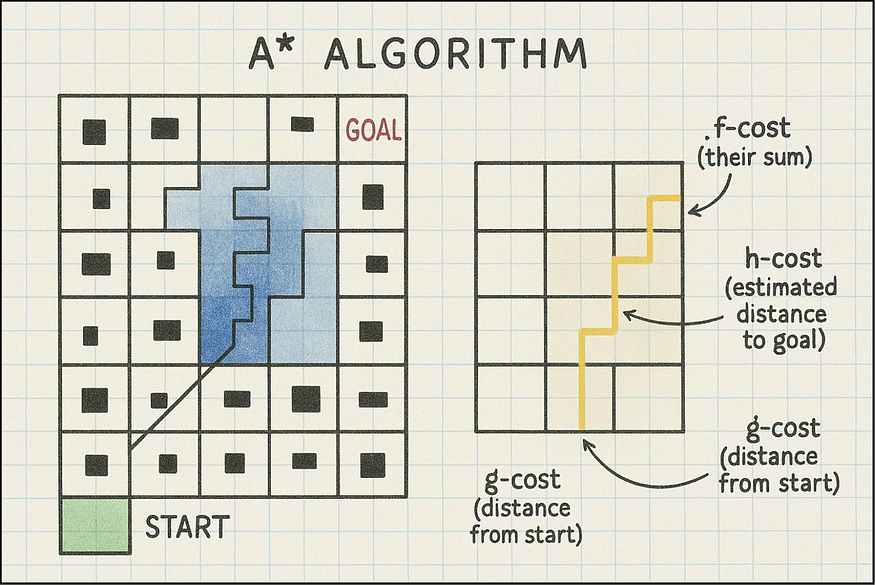
A*算法算法如何工作:
- 与 Dijkstra 类似,它跟踪从起点开始的实际行进距离(g-cost)
- 但它也使用了一种“启发式”方法——对目标的估计成本(h-cost)
-
它优先探索组合成本最低的点(f-cost = g-cost + h-cost)
- 这种“有根据的猜测”有助于 A* 集中搜索目标
- 它比 Dijkstra 效率高得多,但如果启发式方法可行,仍能保证最佳路径(永远不会高估)
2.1.3 比较两种算法
- Dijkstra 就像通过有条不紊地检查房子的每一寸来寻找钥匙
- A* 就像寻找钥匙一样,思考“我最有可能把它们放在哪儿了?”,然后首先检查那些地方。
- 两者最终都会找到你的密钥,但A* 通常速度更快
2.2 基于采样的规划
想象一下在地图上随机放置一些点,然后连接这些点形成有效的路径。这就像通过探索来创建路线图。
RRT 的工作方式就像从起点种植一棵树,其树枝随机延伸到未探索的区域。
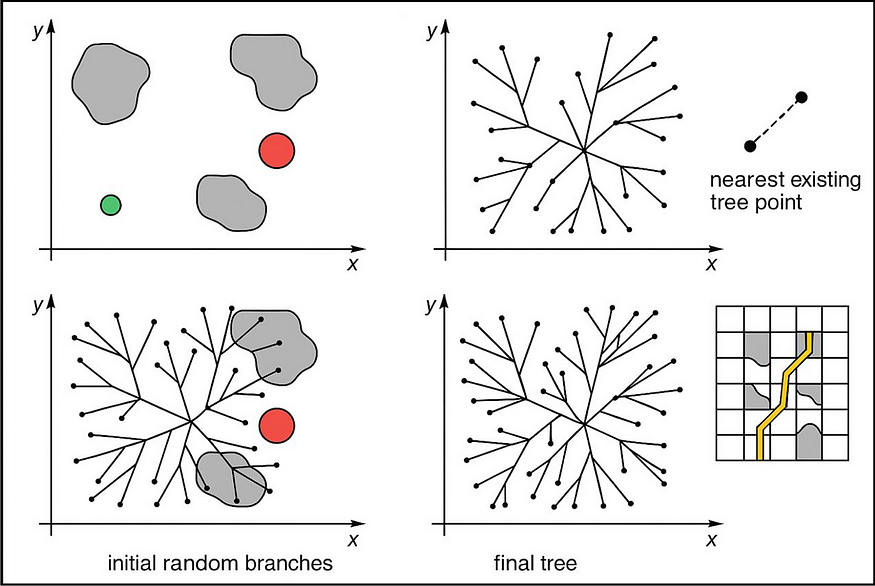
快速探索随机树RRT 的工作原理:
- 从一个点开始(您的起始位置)
- 随机选取空间中的一个点
- 在现有树中找到与该随机点最近的点
- 尝试用直线连接它们
- 如果线路没有碰到任何障碍物,则将其添加到树中
- 重复,直到你的树到达目标区域
- 然后追溯树以找到从起点到目标的路径
RRT 为何有用:
- 在基于网格的方法难以适应的复杂高维空间中效果很好
- 不需要探索整个空间
- 善于在狭小空间或狭窄通道中寻找路径
- 不保证最短路径,但可以快速找到有效路径
2.2.2 概率路线图(PRM)
PRM 就像是先创建一张安全路径地图,然后在该地图上规划您的旅程。
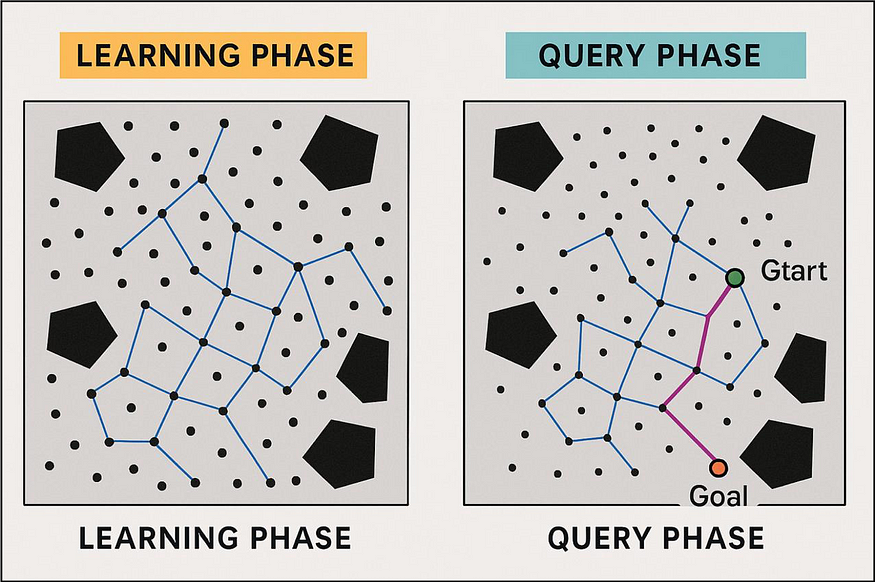
概率路线图PRM 的工作原理:
- 学习阶段:
- 在整个空间中随机放置点
- 对于每个点,尝试将其连接到附近的点
- 如果连接没有遇到障碍,请将其添加到您的路线图中
- 这将创建一个安全路径网络
- 查询阶段:
- 将你的起点和目标位置与路线图联系起来
- 使用图形搜索算法(如 Dijkstra 或 A*)来找到路线图的最佳路径
PRM 为何有用:
- 非常适合需要规划许多不同路径的环境
- 路线图可以重复用于多个查询
- 在高维空间中效果良好
- 可以轻松并行化
2.2.3 比较 RRT 和 PRM
- RRT 就像不断从已知领域出发,探索未知领域
- PRM 就像先创建一张详细的地图,然后规划你的旅程
- RRT 更适合一次性查询,而当需要在同一环境中规划多条路径时,PRM 更适合。
2.3 基于优化的规划
这就像通过不断进行小调整直到无法再改进来找到最平滑、最有效的路径。
这种方法从粗略的初始路径开始,然后对其进行细化,使其更平滑、更高效且无碰撞。
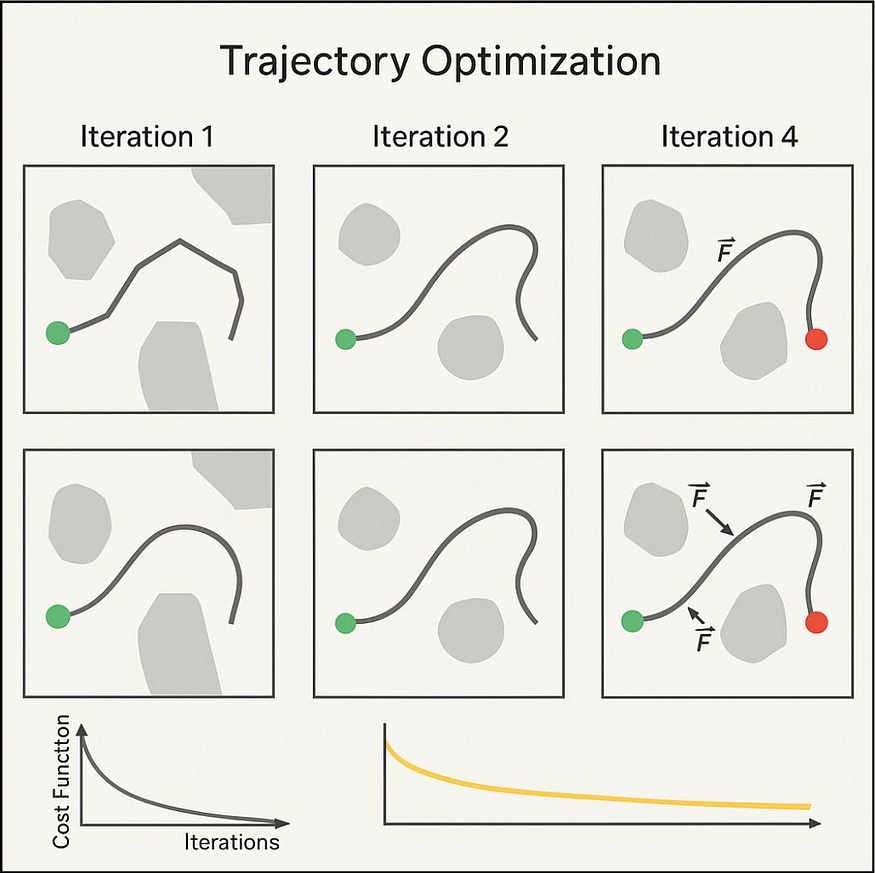
轨迹优化轨迹优化的工作原理:
- 从初始路径开始(通常是直线或另一个规划器的输出)
- 定义一个“成本函数”来衡量路径的好坏,考虑:
- 路径长度(越短越好)
- 平滑度(急转弯较少)
- 与障碍物的距离(安全裕度)
- 能源效率(更少的加速/减速)
- 迭代调整路径以最小化该成本函数
- 当改进变得非常小或达到时间限制时停止
2.3.2 流行的轨迹优化方法:

优化方法- 梯度下降:
朝着最能改善路径的方向迈出一小步
- CHOMP(运动规划的协变哈密顿优化):专门设计用于创建平滑的机器人运动,同时避开障碍物
- TrajOpt:使用顺序凸优化有效处理复杂约束
2.3.3 为什么基于优化的规划很有用:
- 创造非常流畅、自然的动作
- 可以针对许多不同的目标(能量、时间、平滑度)进行优化
- 非常适合改进其他规划器的路径
- 适用于动态复杂且平滑度至关重要的机器人
- 可以纳入物理约束,如关节限制或能量守恒
2.4为什么使用机器学习进行运动规划?

图9 机器学习与传统比较传统的运动规划就像遵循一张带有具体指示的详细地图。机器学习更像是学习从经验中导航。以下是机器学习日益流行的原因:
- 从示例中学习:机器学习系统不是针对每种可能的情况进行编程,而是从数据和示例中学习。
- 快速反应: ML 可以帮助系统更快地响应意外变化。
-
适用于新情况:训练有素的机器学习系统可以处理以前从未见过的环境。
3.1 监督学习:从例子中学习
这就像通过观察经验丰富的驾驶员来学习驾驶一样。系统从标记的示例中学习模式。
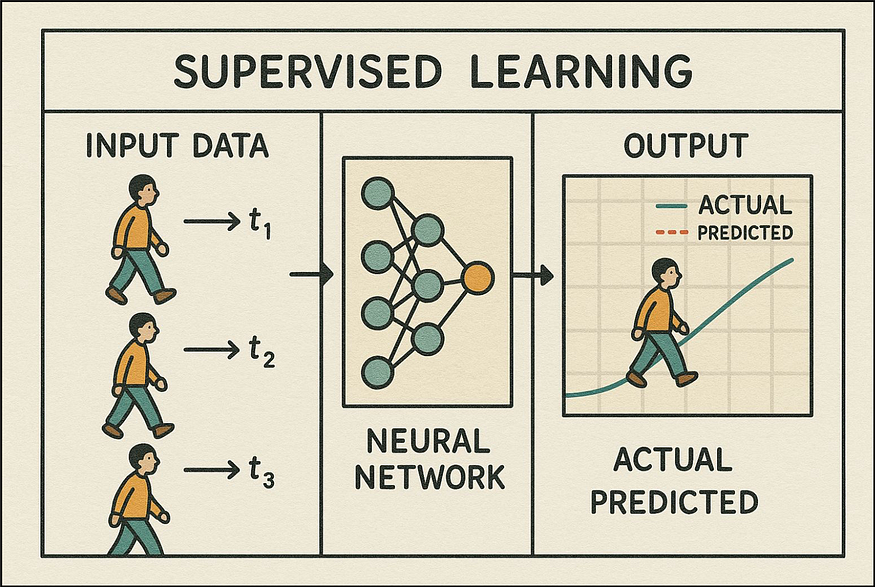
图10 监督学习工作原理:运动规划中的监督学习通过在标记数据集上训练模型来实现,其中输入场景与正确的运动路径或动作配对。这类似于学生通过观察经验丰富的驾驶员并在监督下练习来学习驾驶。该模型可以识别过去数据中的模式,并将其应用于新情况,从而改进导航和避障能力。
3.2 强化学习:从反复试验中学习
这就像通过练习学习骑自行车——有时会摔倒,但每次尝试都会进步。
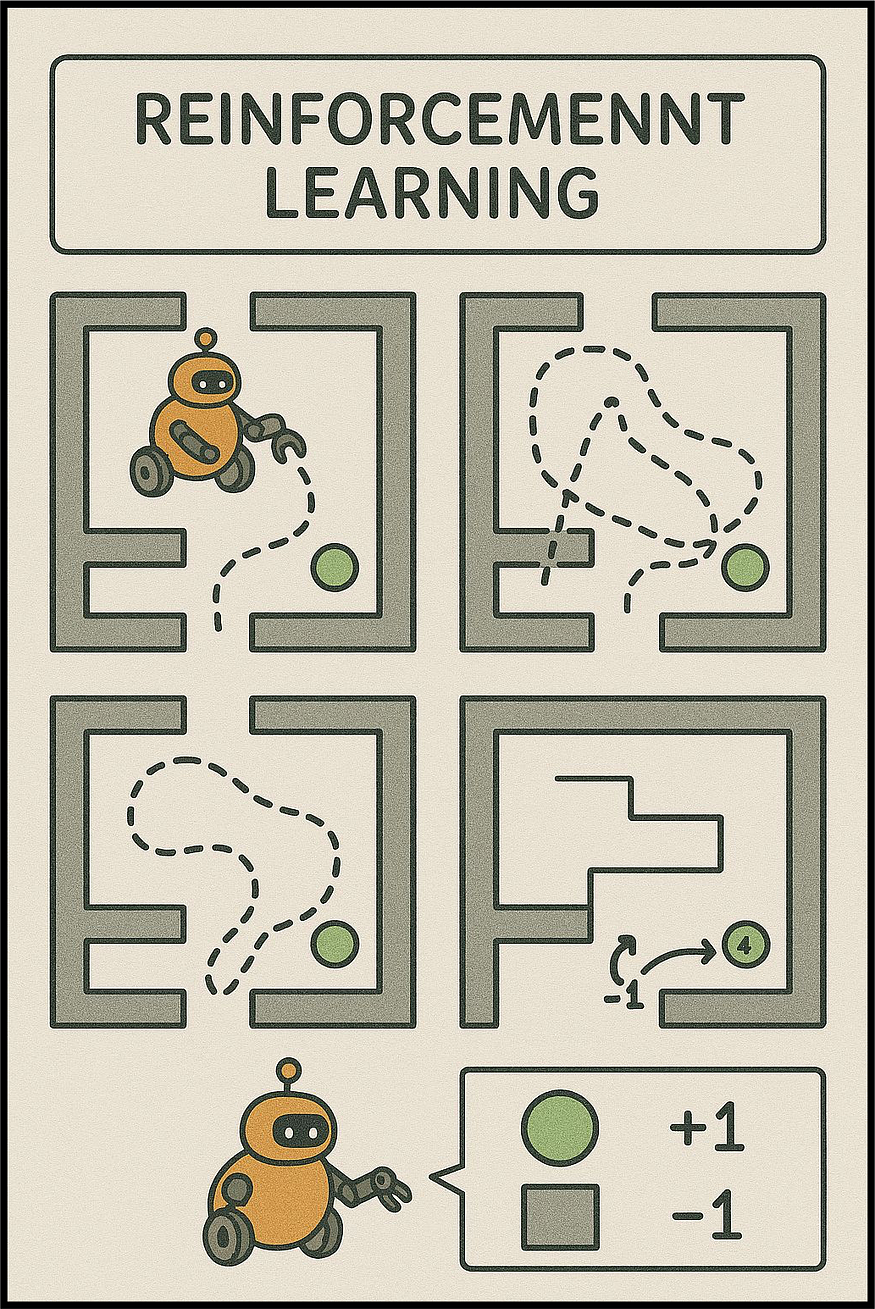
强化学习
工作原理:系统尝试不同的行动,对正确的决策给予奖励,对错误的决策给予惩罚,并逐步改进其策略。
关键算法:
- Q-Learning:适用于简单情况(例如导航小网格)
- 深度 Q 网络(DQN):适用于复杂情况(例如在交通中驾驶)
- 近端策略优化(PPO):适用于精确控制(如机械臂)
3.3 模仿学习:抄袭专家
这就像通过模仿专业舞者的动作来学习舞蹈。

模仿学习工作原理:系统观察专家正确执行任务并尝试模仿他们的行为。
-真实的例子:机械臂通过观察人类的动作来学习拾取物体。
3.4 生成模型:创建新路径
这些系统可以根据所学的模式创建新的、原创的解决方案。
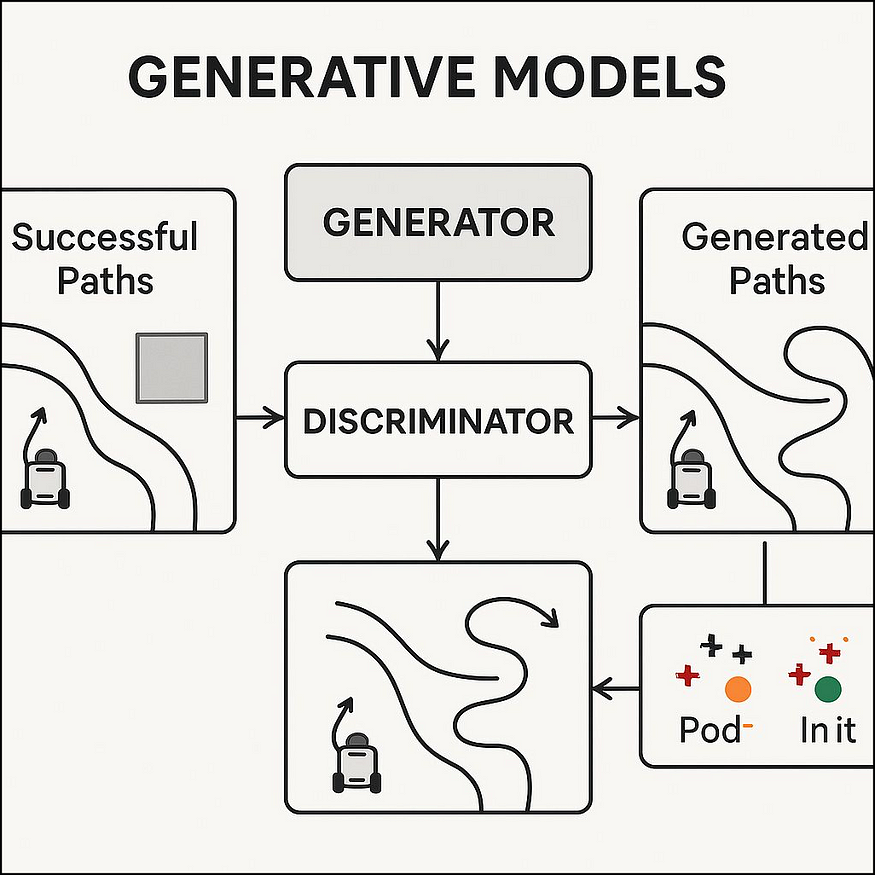
生成模型工作原理:在看到许多良好路径的示例后,系统可以生成具有相似品质的新路径。
-真实示例:根据过去成功的路线为仓库机器人创建新的高效路线。
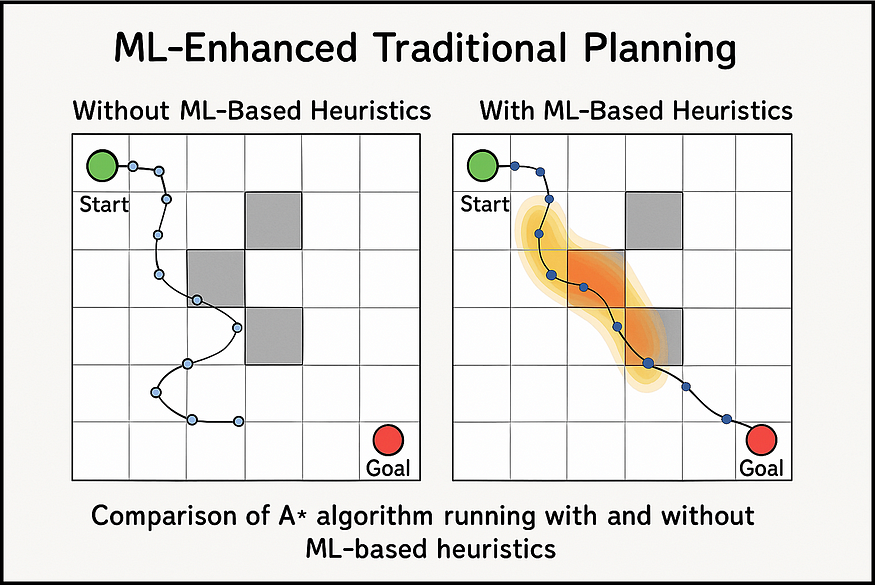
机器学习增强传统规划现在许多系统使用 ML 来增强传统算法:
- ML 增强搜索: A* 等传统算法使用 ML 来更好地猜测首先尝试哪条路径。
- 更智能的采样: ML 有助于决定在基于采样的规划器(如 RRT)中将随机样本放置在何处。
-
真实的例子:机器人可能使用传统规划进行基本导航,但使用 ML 来处理意外障碍。

挑战尽管机器学习在运动规划中前景广阔,但它仍面临一些障碍:
- 获取足够的数据:机器学习系统需要大量的示例来学习。
- 在新环境中工作:系统必须处理未经训练的情况。
- 安全问题:机器学习系统有时会做出意外的决定,这在现实世界中可能是危险的。
- 计算能力:机器学习需要功能强大的计算机,尤其是实时应用。
他们需要做的事情:导航道路、避开障碍物、遵守交通规则。
使用的机器学习方法:强化学习用于驾驶决策,监督学习用于预测其他驾驶员的行为。
工作原理:汽车不断预测行人、其他车辆和障碍物的未来位置,然后规划绕过它们的安全路径。
6.2 工厂机器人
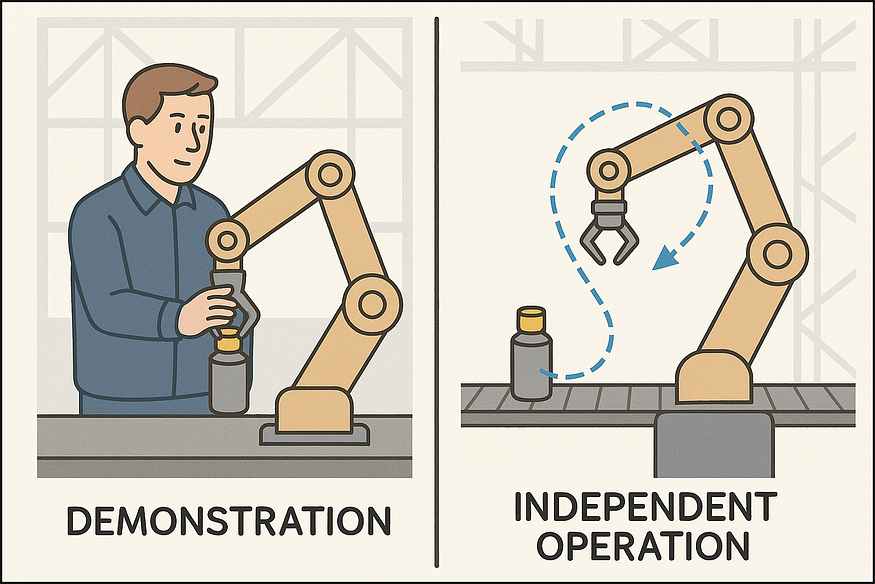
经过训练的机器人它们需要做的事情:拾取物体、组装产品、与人类一起工作。
使用的机器学习方法:从人类示范中进行模仿学习,通过强化学习进行优化。
工作原理:机器人通过观察人类或在模拟中反复试验来学习有效的动作。
机器学习正在彻底改变运动规划,使机器人、车辆和虚拟角色更加智能、适应性更强。这些系统不再遵循僵化的规则,而是能够从经验中学习,适应新情况,甚至创造出原创的解决方案。
随着机器学习的不断发展,我们将在机器人、交通运输、制造和娱乐领域看到更多令人印象深刻的应用。传统的运动规划方法与尖端的机器学习相结合,为自动化和人工智能开辟了令人兴奋的全新可能性。
无论是对制造机器人、开发自动驾驶汽车还是创建更逼真的视频游戏感兴趣,了解 ML 如何增强运动规划都是一项珍贵的未来技能。








