
精准农业旨在优化农业管理,在节约资源的同时提升产量,并最大程度降低对环境的影响。
目前,有几种技术致力于提升农业的可持续性,例如:
露点温度
在灌溉系统方面,灌溉水量不足会使植物承受压力,进而降低作物产量,过度灌溉会导致水分过多,从而滋生害虫。
合适的灌溉流程能够节省大量水资源,并保护其他资源。
影响灌溉的一个关键指标就是露点温度,露点温度反映了空气中水分的含量,而这又会对灌溉流程产生影响,所以预测露点温度有助于为水资源规划提供支持。
而且露点温度在水利、气候和农业等多个领域的其他活动中也具有重要意义。
例如,如果预报显示可能出现水分过多的情况,就可以提前采取病虫害防治措施。
预报还能用于预测霜冻,让农民可以采取预防性措施来保护作物。
在能源管理领域,预测露点温度同样重要,在露点温度较高时,人们往往会使用空调系统来应对高相对湿度。
预测这些天气状况可用于预测能源需求的增长,从而有助于提高电网的运行效率。
在本文的后续部分将对多个地点的露点温度进行预测,大家将学习如何使用深度学习构建一个时空预测模型。
另外我们精心打磨了一套基于数据与模型方法的 AI科研入门学习方案(已经迭代过5次,即将迭代第6次),对于人工智能来说,任何专业,要处理的都只是实验数据,所以我们根据实验数据将课程分为了三种方向的针对性课程,包含时序、图结构、AI+实验室,我们会根据你的数据类型来帮助你选择合适的实验室,根据规划好的路线学习 只需5个月左右(很多同学通过学习已经发表了 sci 一区及以下、和同等级别的会议论文)学习形式为
直播+录播,多位老师为你的论文保驾护航。
大家感兴趣可以直接添加小助手微信:ai0808q 通过后回复咨询既可!
AI for science
实践:利用深度学习进行露点温度的时空预测
时空预测入门
时空数据是多元时间序列的一种特殊情况,这类数据集涉及在多个地点对某个变量(如露点温度)进行观测。
这类数据既包含时间依赖性,又包含空间依赖性,在特定地点采集的数据点,与该地点的滞后数据以及附近地点当前和过去的滞后数据都存在相关性。
对这两种依赖性进行建模,对于在每个地点获得更准确的预测至关重要。
时空预测通常采用向量自回归(VAR)或时空自回归(STAR)等技术。本文将采用基于深度神经网络的 VAR 方法。
数据集
本文将使用由美国农业部收集的真实数据集,该数据集包含露点温度等信息,该变量在 6 个附近站点进行了采集。
数据集来源:
https://agdatacommons.nal.usda.gov/articles/dataset/Data_From_Weather_Snow_and_Streamflow_data_from_four_western_juniper-dominated_Experimental_Catchments_in_south_western_Idaho_USA_/24660384?file=44334665
下载数据后,可使用以下代码读取:
import pandas as pdDATE_TIME_COLS = ['month', 'day', 'calendar_year', 'hour', 'water_year']data = pd.read_csv(filepath)data['datetime'] = pd.to_datetime([f'{year}/{month}/{day} {hour}:00' for year, month, day, hour in zip(data['calendar_year'], data['month'], data['day'], data['hour'])])data = data.drop(DATE_TIME_COLS, axis=1).set_index('datetime')data.columns = data.columns.str.replace('_dpt_C', '')
数据呈现如下:
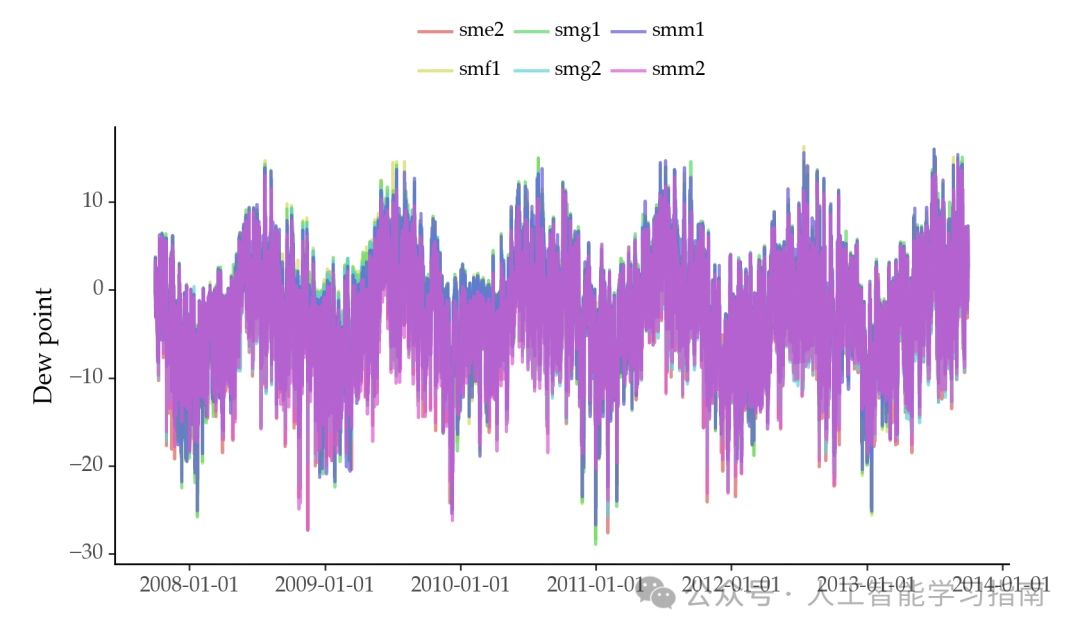
不同地点的时序数据似乎存在相关性。
VAR——为监督学习准备数据
本文采用 VAR 方法来准备数据,以便训练深度神经网络,VAR 方法旨在捕捉不同变量之间的时间依赖性。
在本例中,这些变量代表在 6 个地点采集的露点温度。
我们可以通过使用滑动窗口将每个变量转换为矩阵格式,然后合并结果来实现这一点。
from sklearn.model_selection import train_test_splitfrom src.tde import transform_mv_seriesN_LAGS, HORIZON = 12, 12N_STATIONS = data.shape[1]train, test = train_test_split(data, test_size=0.2, shuffle=False)mean_by_location = train.mean()train_scaled = train / mean_by_locationtest_scaled = test / mean_by_locationX_train, Y_train = transform_mv_series(train_scaled, n_lags=N_LAGS, horizon=HORIZON)X_test, Y_test = transform_mv_series(test_scaled, n_lags=N_LAGS, horizon=HORIZON)
接下来,我们基于 Keras 构建一个堆叠式 LSTM 模型。
(长短期记忆网络LSTM是一种特殊的循环神经网络,能够捕捉时间依赖性。)
from keras.models import Sequentialfrom keras.layers import Dense, Dropout, LSTM, RepeatVector, TimeDistributedmodel = Sequential()model.add(LSTM(64, activation='relu', input_shape=(N_LAGS, N_STATIONS)))model.add(Dropout(.2))model.add(RepeatVector(HORIZON))model.add(LSTM(32, activation='relu', return_sequences=True))model.add(Dropout(.2))model.add(TimeDistributed(Dense(N_STATIONS)))model.compile(optimizer='adam', loss='mse')
定义并编译模型后,可按以下方式进行训练:
from keras.callbacks import ModelCheckpointmodel_checkpoint = ModelCheckpoint( filepath='best_model_weights.h5', save_weights_only=True, monitor='val_loss', mode='min', save_best_only=True) history = model.fit(X_train, Y_train, epochs=25, validation_split=0.2, callbacks=[model_checkpoint])
训练完成后,可加载模型检查点回调所保存的最佳权重:
model.load_weights('best_model_weights.h5')preds = model.predict_on_batch(X_test)
模型拓展
我们可以从多个方面拓展该模型,例如将其他气象信息作为解释变量纳入模型。
露点温度等气象数据会受到多种因素的影响,将这些因素纳入模型可能是提高预测性能的关键。
尝试其他神经网络架构也可能带来提升,文中采用了堆叠式 LSTM,但其他方法也展现出了良好的预测性能,例如 N-BEATS、DeepAR 或 ES-RNN。
我们还可以纳入空间信息,如地理坐标,这样模型就能更好地模拟不同地点之间的空间依赖性。
总结
精准农业旨在优化农业流程,这种优化可以降低农业对环境的影响,露点温度是水文学中的一个关键指标,预测该变量对灌溉等多种活动有益。
气象变量通常在多个站点进行采集,从而形成时空数据集,深度学习可用于构建时空预测模型。
本文使用包含六个不同地点露点温度的数据集训练了一个 LSTM 神经网络,这个模型可以通过纳入额外的解释变量、空间信息或改变网络架构等方式进行拓展。
大家想自学的我还给大家准备了一些机器学习、深度学习、神经网络资料大家可以看看以下文章(文章中提到的资料都打包好了,都可以直接添加小助手获取)
大家觉得这篇文章有帮助的话记得分享给你的
死党、闺蜜、同学、朋友、老师、敌蜜!








