太长不看版
LLM 自回归做理解,MaskGIT 方案做生成的理解生成统一模型。
Show-o 是一个 Unified Model,是个生成理解统一模型。Show-o 使用 LLM 自回归做理解,MaskGIT方案做生成的理解生成统一模型。多模态理解方面,Show-o 可以做 visual question-answering 等等,视觉生成方面,Show-o 可以做 text-to-image generation, text-guided inpainting/extrapolation,以及混合模态生成。
下面是对本文的详细介绍。
本文目录
1 Show-o:MaskGIT 方法做生成理解统一模型
(来自 NUS Show Lab,字节跳动)
1 Show-o 论文解读
1.1 Show-o 模型
1.2 Show-o Tokenization
1.3 Show-o 模型架构
1.4 Show-o 训练目标
1.5 Show-o 训练策略
1.6 Show-o 推理
1.7 Show-o 实验设置
1.8 Show-o 评测
1
Show-o:MaskGIT 方法做生成理解统一模型
论文名称:Show-o: One Single Transformer to Unify Multimodal Understanding and Generation (ICLR 2025)
论文地址:
https://arxiv.org/pdf/2408.12528
项目主页:
https://github.com/showlab/Show-o
1.1 Show-o 模型
用一个统一的模型 (Unified Model) 来处理多模态理解和生成任务的常见做法如图 1(c) 所示,比如 Next-GPT, SEED-X,使用模型独立处理视觉域和语言域。另一个最近很热门的方向是:使用单个 Single Transformer 同时处理理解和生成任务。
 图1:仅理解,仅生成,和统一理解生成模型的比较
图1:仅理解,仅生成,和统一理解生成模型的比较Chameleon 证明了这点,即:早期融合不同模态的数据,通过相同的自回归建模方式生成文本和图像 token。自回归预测图像的一个明显的瓶颈是:
Causal attention 需要大量采样步骤,尤其是处理高分辨率图像或者视频时。扩散模型在视觉生成方面表现出比自回归模型更好的潜力。
这促使作者思考:单个 Single Transformer 能否同时涉及自回归和扩散建模?
Show-o 设想了一种新的范式,即文本被表示为 discrete tokens,用大语言模型 (LLM) 自回归建模。图像被表示为连续的,使用 Denoising Diffusion Model 进行建模。
然而,由于离散文本 token 和连续图像表征之间的显着差异,将这两种不同的技术集成到一个单一网络中并非易事。另一个挑战是,现有的最先进的扩散模型通常依赖于 2 个不同的模型,即 Text Encoder 对文本 Condition 信息进行编码,以及用于预测噪声的去噪网络。
Show-o 可以同时处理理解和生成任务,使用自回归-扩散混合建模。Show-o 建立在预训练 LLM 上,继承了基于文本的推理的自回归建模能力。Show-o 还采用 discrete denoising diffusion model 对离散图像 token 进行建模。为了适应任务的不同输入数据和变化,采用文本 tokenizer 和图像 tokenizer 将它们编码为离散 token,并进一步提出了统一的提示策略,将这些 token 作为输入处理。因此,给定一个伴随问题的图像,Show-o 自回归给出答案。当只提供文本 token 时,Show-o 以离散去噪扩散的风格生成图像。
Show-o 基于 MaskGIT[1]。MaskGIT 是一种 mask token prediction 的方法。
Show-o 的最终目标是开发一个统一模型,涉及自回归和扩散建模,且可以联合多模态理解和生成。
核心问题:
- 如何定义模型的输入和输出空间?(1.3 节,tokenizing text 和 image 数据到 discrete tokens)
- 如何统一来自不同模态的各种输入数据?(1.4 节,架构和 unified prompting)
- 如何在单个 Transformer 中涉及自回归和扩散建模?(1.4 节)
- 如何有效地训练这样一个统一的模型?(1.5 节,3 阶段训练策略)
1.2 Show-o Tokenization
Show-o 建立在预训练的 LLM 上,在离散空间上执行统一学习是一种自然的方式。需要维护一个统一的词汇表,其中包括离散文本和图像 token。统一模型的任务是预测离散 token。
Text Tokenization
Show-o 基于预训练的 LLM,使用相同的 tokenizer 进行文本数据标记化,无需任何修改。
Image Tokenization
按照 MAGVIT-v2[2]的做法,训练一个 quantizer,维持一个 K=8,192 的 codebook,把 256×256 图片编码为 16×16 的 discrete token。按照 MAGVIT-v2 的原因是它易于微调,可以很容易变成一个 video tokenizer。
 图2:在多模态理解生成统一模型中,图像编码的几种方式:(a) 使用 vector quantization 在离散空间中操作;(b) 和 (c) 在连续空间中操作。Show-o 使用 (a) 模式
图2:在多模态理解生成统一模型中,图像编码的几种方式:(a) 使用 vector quantization 在离散空间中操作;(b) 和 (c) 在连续空间中操作。Show-o 使用 (a) 模式还有 2 种做法是使用 continuous 的图片表征,如图 2(b),2(c) 所示。Show-o 默认使用 discrete image tokens 用于理解和生成。
1.3 Show-o 模型架构
Show-o 继承了现有 LLM 的架构,除了添加 QK-Norm 操作外,没有任何架构修改。作者使用预训练 LLM 的权重初始化 Show-o。
Unified Prompting 策略
为了统一训练多模态理解和生成,作者设计了一种 Unified Prompting 策略来格式化各种输入数据。给定 image-text pair,首先 tokenized 变为 个 image tokens 和 个 text tokens 。根据图 3 所示的格式的任务类型将它们形成输入序列。
[MMU] 和 [T2I] 是预定义的 task token,表示输入序列的学习任务。
[SOT] 和 [EOT] 分别作为表示 text token 的开始和结束 token。
[SOI] 和 [EOI] 分别作为表示 image token 的开始和结束 token。
 图3:Unified Prompting 策略图解
图3:Unified Prompting 策略图解使用这种提示设计可以有效编码各种输入数据进行多模态理解、文生图和混合模态生成。一旦训练好,就可以相应地提示 Show-o 以处理各种视觉语言任务,包括视觉问答和文生图。
Omni-Attention 机制
Show-o 的注意力机制并非全是 Causal Attention,也并非全是 Full Attention,而是一种综合注意力机制,根据输入序列的格式自适应地混合和更改。
如下图 4 所示,Show-o 能够以不同的方式对各种类型的信号进行建模。Show-o 通过 Causal Attention 对序列中的文本 token \textbf{v} 进行建模。对于图像 token \textbf{u} ,Show-o 通过 Full Attention 建模它们。给定一个格式化的输入序列:
多模态理解中 (图 4(a)),文本 token 可关注所有先前的图像 token。
文生图中 (图 4(b)),图像 token 能够与所有先前的文本 token 交互。
文本建模中 (图 4(c)),退化为 Causal Attention。
 图4:Omni-Attention 机制。深色方块代表 "attend",白色方块表示 "不允许 attend"。它是一种具有 causal attention 和 full attention 的混合注意力,根据输入序列的格式自适应地混合和更改。
图4:Omni-Attention 机制。深色方块代表 "attend",白色方块表示 "不允许 attend"。它是一种具有 causal attention 和 full attention 的混合注意力,根据输入序列的格式自适应地混合和更改。1.4 Show-o 训练目标
为了执行自回归和(离散)扩散建模,Show-o 采用了 2 个训练目标:
- Next Token Prediction (NTP)
- Mask Token Prediction (MTP)
给定 个 image tokens 个 text tokens
NTP 使用语言建模损失来最大化文本 token 可能性:
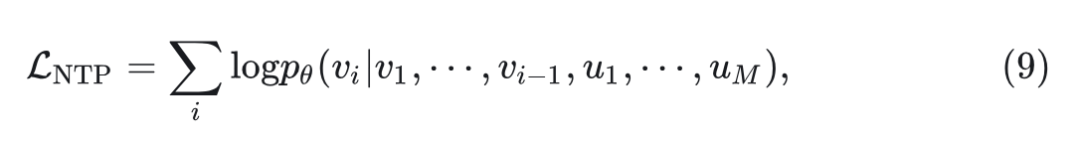
式中, 代表条件概率, 为 Show-o 的权重。
MTP 作为另一个训练目标,可以无缝集成到 discrete diffusion modeling 中。对于输入序列中的 个 image tokens ,首先以一定的比例(受 timestep 控制)随机将图像 token 随机替换为[MASK]token,得到 。然后目标是以 unmasked 区域和 text token 为 condition,重建原始的图像 token。可以写成:
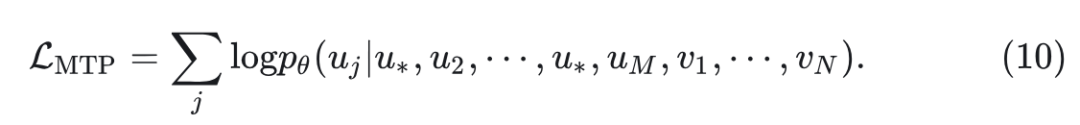
注意到这个损失函数仅应用于 masked token。具体来说,以 unmasked image token 和所有 text token 为条件,重建那些 masked image tokens。遵循 classifier-free guidance 的做法,以一定的概率用空文本 "" 随机替换 conditioned text token。
给定 1 个 Batch 的输入序列,总的损失函数:
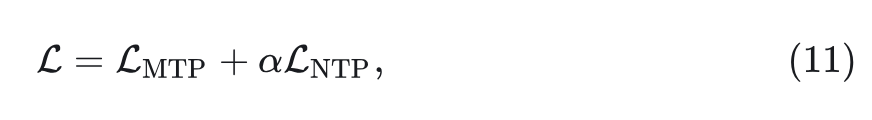
其中, 是超参数。
 图5:Show-o。输入数据,无论模式如何,都被 token 化,然后按照指定的格式输入。Show-o 自回归地处理 text token (causal attention 模式),使用离散扩散模型处理 image token (full attention 模式)
图5:Show-o。输入数据,无论模式如何,都被 token 化,然后按照指定的格式输入。Show-o 自回归地处理 text token (causal attention 模式),使用离散扩散模型处理 image token (full attention 模式)1.5 Show-o 训练策略
Show-o 采用 3 阶段的方法逐步有效地训练 Show-o:
- Stage 1:Image Token Embedding 以及像素依赖关系的学习。 使用 RefinedWeb 数据集来训练 Show-o 以保持语言建模能力。同时,采用 ImageNet-1K 数据和
图像-文本对分别训练 Show-o 进行类条件图像生成和图像字幕。作者直接使用 ImageNet-1K 中的类名作为文本输入来学习类条件图像生成。这一阶段主要涉及学习 learnable embeddings 为今后的离散图像 token 打底,还有图像生成的像素依赖关系,以及图文之间的对齐来进行图像字幕。
- Stage 2:多模态理解和生成的图文对齐。 基于预训练的权重,继续训练文生图。这一阶段主要关注图像字幕和文生图中的图像和文本对齐。
- Stage 3:高质量的数据微调。 结合高质量图文对进行文生图,以及教学数据进行多模态理解和混合模态生成。
1.6 Show-o 推理
推理中,Show-o 涉及 2 种类型的预测,即 text token 和 image token。
在多模态理解中,给定图像和问题,text token 是从具有更高置信度的预测 token 中自回归采样的。
在视觉生成中,生成图像需要 步。最初,是 个 text token 作为 condition,以及 个 [MASK]token 作为输入。然后 Show-o 为每个[MASK]token 预测一个 logit ,其中 是时间步。每个[MASK]token 的最终预测 logit 使用 conditional logit 和 masked token 的 unconditional logit ,通过下式计算:
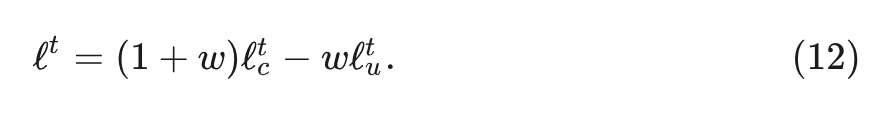
其中, 是 guidance scale。
每一步保留置信度更高的 image token,同时用[MASK]token 替换置信度较低的 image token,这些 token 随后都被反馈到 Show-o 以进行下一轮预测。图 6 提供了一个说明。这个去噪过程需要 步,类似于 Diffusion Model 的方法。
 图6:增加噪声的 image corruption 过程,以及逐渐去噪的图像生成过程
图6:增加噪声的 image corruption 过程,以及逐渐去噪的图像生成过程1.7 Show-o 实验设置
数据: 3种类型的数据:
- Text-only Data: 使用公开可用的 RefinedWeb 数据集来保留预训练的 LLM 的文本推理能力。
- Image Data with Class Names: 使用来自 ImageNet1K 数据集的 1.28M 图像来学习像素依赖关系。
- Image-Text Data: 多模态理解和生成,从公开可用的数据集中组装了大约 35M 的图像-文本对,包括 CC12M 、SA1B 和 LAION-aesthetics-12M。此外,通过结合 DataComp 和 COYO700M 以及一些过滤策略,进一步将数据规模增加到 2.0B 左右。使用 ShareGPT4V 来重新描述这些数据集。此外,LAION-aesthetics-12M 和 JourneyDB 作为用于最终微调的高质量数据集。继 LLaVA-v1.5 之后,结合了 LLaVA-Pretrain558K 和 LLaVA-v1.5-mix-665K 做指令微调。此外,GenHowTo 用于混合模态生成。
评价指标:
多模态理解 benchmark:POPE, MME, Flickr30k, VQAv2, GQA, MMMU
视觉生成 benchmark:FID on MSCOCO,GenEval
训练过程:
Stage 1:RefinedWeb,35M image-text pairs,ImageNet-1K 联合训练 500K steps。训练语言建模,图像字母,和 class-conditional 图像生成。
Stage 2:35M image-text pairs 训练 1000K steps。训练文生图。
Stage 3:高质量 image-text pairs。训练遵循指令。
1.8 Show-o 评测
多模态理解
图 7 显示了 Show-o 在公共基准上的多模态理解能力,例如图像字幕和视觉问答任务。与 understanding only 模型 (包括 InstructBLIP、Qwen-VL-Chat 和 mPLUG-Owl2 在多模态理解方面进行比较时,本文模型模型大小会小得多,在 POPE、MME、Flickr30k 和 VQAv2 benchmark 中也取得了有竞争力的性能,并且在 GQA benchmark 测试中表现更好。与具有大量参数的 Unified Model 相比,例如 NExT-GPT-13B 和 Chameleon34B,Show-o 在 Flickr30k benchmark 中也取得了不错的性能,并在 VQAv2 benchmark 上表现更好。
 图7:多模态理解 benchmark 结果
图7:多模态理解 benchmark 结果图 8 展示了 Show-o 的视觉问答能力并与 Chameleon 和 SEED-X 进行了比较。
 图8:多模态理解定性结果
图8:多模态理解定性结果视觉生成
MSCOCO 30K 结果
图 9 展示了 MSCOCO 30K 的 Zero-shot FID 结果。与使用更多参数和训练图像 (如 GLIDE 和 DALL·E 2) 训练的模型相比,Show-o 实现了更好的 FID (9.24),只有 1.3B 参数和 35M 训练数据。与 Unified Model 相比,Show-o 也表现出了提升。值得注意的是,MSCOCO 30K 上的 FID 可能无法全面准确地评估生成保真度。原因在于现有的生成模型通常是用与 MSCOCO 数据集分布不一致的高质量和美学图像微调之后得到的。因此,这种不匹配导致生成保真度的测量不准确。
 图9:MSCOCO zero-shot FID 结果
图9:MSCOCO zero-shot FID 结果GenEval 结果
作者评估了 Show-o 在 GenEval benchmark 上的文生图能力,结果如图 10 所示。当与 LDM (1.4B) 等类似大小的模型比较时,Show-o 在所有 6 个指标中都获得了显著更好的性能,总体提高了约 0.31。此外,Show-o 实现了比模型尺寸大 5 倍的 DALL·E 2 更好的性能。此外,仅具有 1.3B 参数的 Show-o 实现了比 SD3 (2B) 等参数数量约 2 倍的模型更好的性能。这表明 Unified Model 的生成能力与专业生成模型相当。
 图10:GenEval benchmark 结果
图10:GenEval benchmark 结果图 11 展示了一些比较结果,包括 Diffusion Model,例如 SDv1.5、SDXL、以及自回归模型,比如 LlamaGen,以及 Unified Model,包括 LWM 和 SEED-X。与 SDv1.5 和 LlamaGen 相比,Show-o 表现出更好的视觉质量和图像-文本对齐。例如,如第 2 列所示,SDv1.5 和 LlamaGen 都不能完全理解文本提示并错过生成图像中的一些属性,例如 sunset 和 blue domes。与 SDXL 相比,Show-o 表现出相当的视觉质量和对齐,例如 "a rally car race" 和 "stunning contrast against the vibrant sunset"。
 图12:SDXL, LlamaGen, LWM, SEED-X, 和 Show-o 的定性比较结果
图12:SDXL, LlamaGen, LWM, SEED-X, 和 Show-o 的定性比较结果参考
- ^Maskgit: Masked generative image transformer
- ^Language model beats diffusion– tokenizer is key to visual generation









