点击上方“图灵人工智能”,选择“星标”公众号
您想知道的人工智能干货,第一时间送达
版权声明
转自青哥谈AI,版权属于原作者,用于学术分享,如有侵权留言删除
|导语
李宏毅教授近几年推出的机器学习视频课程,以其深入浅出、幽默风趣的风格深受好评,他善于用生动的例子解释复杂理论,每年的课程都是经典。今年,李宏毅教授最新、最具代表性的「生成式AI时代下的机器学习(2025)」系列课程更是火遍全球,深度讨论了Agent、预训练、后训练等前沿话题。接下来,我们将为大家全程搬运2025年课程的精华内容,每周更新一讲。对机器学习和生成式AI感兴趣的朋友,可以关注我们,不错过任何一期干货分享!
本期是系列课程第一讲,深度解析生成式人工智能的技术突破与未来发展,为读者呈现了一堂生动的生成式AI入门课程,既有理论深度又有实践指导价值。涵盖AI行为模式分析、核心运作机制、Token生成原理、深度学习架构、模型训练方法以及能力赋予策略等关键技术要点。
|
预习要求与课程概览
李宏毅教授第一讲课程以"一堂课搞懂生成式人工智能的技术突破与未来发展"题,为学生和AI爱好者提供了一个快速了解生成式AI现状和未来趋势的机会。
李宏毅教授特别强调,后续课程将假设学生已有相关背景知识,因此强烈建议预习以下内容:• 《机器学习2021》- 至少看到"Transformer (下)"关注本公众号,后台回复【0607】获取第一讲完整PPT及视频资源一、生成式AI的惊人行为展示
李宏毅教授通过一个生动的例子展示了生成式AI的强大能力。他先让ChatGPT根据PPT内容生成30秒的台湾风格讲稿,然后使用联发科创新基地的Breezy Voice模型进行语音合成,最后通过Heygen平台生成数字人视频。
AI数字人制作流程:
步骤1 内容生成:ChatGPT读取PPT图片,生成30秒台湾风格讲稿
步骤2 语音合成:Breezy Voice根据参考音频克隆李宏毅教授声音
步骤3 视频生成:Heygen平台制作数字人讲课视频
"有了投影片之后,要生成一个数字人来直接讲课,是有可能的。但是真正的难点并不在讲课的环节。准备一门课最花时间的,其实是在做投影片上。"
—— 李宏毅教授
为了进一步验证AI的能力,李宏毅教授尝试让ChatGPT Deep Research完全自动生成课程内容。结果显示,AI确实可以生成1万3千字的详细课程内容,甚至包含笑话和励志故事,但内容质量仍有提升空间。
二、AI推理能力的重大突破现代生成式AI最令人瞩目的进展之一是具备了类似"思考"的推理能力(Reasoning)。与传统的直接问答模式不同,新一代AI会展示完整的思考过程。
图2: AI思考过程演进对比
李宏毅教授以一个有趣的例子展示了这种推理能力:他问DeepSeek"如果姜子牙和邓不利多在公平对决的情况下,谁会获胜?"DeepSeek没有立即回答,而是进行了长达1500字的内心分析,考虑了两个角色的各种能力、优势和劣势。推理过程示例分析
DeepSeek的思考要点:
技术突破意义:这种推理能力代表了AI从简单的模式匹配向真正的逻辑思考的转变,为解决复杂问题提供了新的可能性。
三、AI Agent:超越一问一答的智能体
李宏毅教授通过一个日常订餐的例子,生动解释了AI Agent的概念。与传统的一问一答模式不同,AI Agent能够执行需要多个步骤才能完成的复杂任务。
图3: AI Agent订餐流程示例
现实中的AI Agent应用已经初见端倪。ChatGPT的Deep Research功能能够进行多轮搜索和深度分析,而Claude的Computer Use和ChatGPT的Operator则可以直接操控数字界面。实际演示:李宏毅教授展示了ChatGPT Operator如何自动访问台大课程网站,找到机器学习课程的加签表单。虽然最终因需要Gmail账号而未能完成填写,但整个过程展示了AI Agent的强大潜力。
四、生成式AI的核心运作机制
Token:万物皆可分解的基本单位
李宏毅教授深入解释了生成式AI的核心原理:所有复杂的对象都可以分解为有限的基本单位——Token。这个概念是理解生成式AI的关键。
图4: Token化基本原理
"万事万物都是Token,把万事万物拆解成Token就是生成式AI的基本原理。"
—— 黄仁勋(NVIDIA CEO)在2024年Computex的发言
Autoregressive Generation:文字接龙的艺术
生成式AI采用Autoregressive Generation(自回归生成)策略,简单来说就是"文字接龙"的过程。这个过程可以统一描述为:
图5: 自回归生成策略流程
生成过程伪代码
输入: x1, x2, ..., xj (所有输入Token) 输出: y1, y2, ..., yn (生成的Token序列)
步骤: 1. 根据 x1, x2, ..., xj 生成 y1 2. 根据 x1, x2, ..., xj, y1 生成 y2 3. 根据 x1, x2, ..., xj, y1, y2 生成 y3 ... n. 根据 x1, x2, ..., xj, y1, ..., y(t-1) 生成 yt
图6:Token预测机制
台湾大学接龙示例
输入:"台湾大"
可能的接续:
因为答案不唯一,所以模型输出的是概率分布,再通过"掷骰子"决定最终输出。
五、深度学习与Transformer架构解析
深度学习:化复杂为简单
李宏毅教授通过一个简单但深刻的比喻解释了深度学习的本质:将一个复杂的函数分解为多个简单函数的串联。
图7: 深度学习层级结构
深度学习的本质:深度学习不是让问题变得更复杂,而是把复杂的问题分解为多个简单的子问题,这就是为什么"深度"能够带来更好的效果。
让机器"思考":深度不够长度来凑
李宏毅教授提出了一个重要观点:让机器进行"思考"实际上是从另一个维度扩展了神经网络的深度。
图8:思考深度扩展原理图
Testing Time Scaling示例
Stanford大学的研究显示,思考时间越长,AI的准确率越高:
实现方法:强制将"结束"符号替换为"wait",迫使模型继续思考
Transformer架构:全局视野的力量
Transformer架构的核心是Self-Attention机制,它让模型能够"看到"全部输入信息。
有趣的是,Transformer这个名字的由来至今仍是个谜。原作者在接受《纽约客》采访时坦言:"从来不知道为什么这个模型要叫Transformer,当初就觉得这个名字很酷,没有什么特别的原因。"
然而,Transformer也有其局限性,特别是在处理长输入时计算量急剧增加。为此,新的架构如Mamba应运而生,被形象地比喻为"机器蛇娘",是Transformer的一种变形。
六、模型训练:架构与参数的艺术
架构与参数的对比
- 70B模型:700亿个参数 (70 Billion)
模型训练本质上是一个分类问题,通过大量的输入输出对来教会模型正确的行为模式:训练数据示例输入: "你是谁?" → 输出: "我"输入: "你是谁?我" → 输出: "是" 输入: "你是谁?我是" → 输出: "人"输入: "你是谁?我是人" → 输出: "工"...编程任务:输入: [编程指令] → 输出: "print"输入: [编程指令]print → 输出: "("输入: [编程指令]print( → 输出: "\""
分类问题的本质:生成式AI本质上是在做选择题,因为Token的数量是有限的。这与传统的信用卡欺诈检测、垃圾邮件过滤、围棋AI等分类问题在技术上是相通的。
七、通用模型的三代演进历程
| 第一形态:编码器时代代表模型:"芝麻街家族"(BERT、ERNIE等) 特点:只能输出向量表示,需要外挂特化模型才能完成具体任务 使用方式:通用模型 + 任务特化模块 |
| 第二形态:微调时代代表模型:GPT-3等
特点:具备完整文字生成功能,但需要针对不同任务微调参数 使用方式:架构相同,参数不同(θ, θ', θ'') |
| 第三形态:指令时代代表模型:ChatGPT、Claude、Gemini、DeepSeek等 特点:可直接理解指令,无需修改参数 使用方式:架构和参数完全相同,仅通过Prompt区分任务 多语言翻译的突破 |
早在2016年,Google就展示了通用翻译模型的惊人能力:八、机器的终身学习时代
从零培养到在职培训
李宏毅教授指出,我们已经进入了"机器的终身学习时代"。与过去需要从零开始训练AI不同,现在的AI更像是一个有基础能力的大学毕业生,只需要针对特定工作进行培训。
两种能力赋予方式对比
微调前后对比
成功的改变: | • 问"你是谁" → 回答"我是小金,李宏毅老师的助教" |
| • 回答变得奇怪:"如果你觉得ChatGPT有用,那代表你未来的工作很悲惨" |
精准的模型编辑技术
为了避免微调带来的副作用,李宏毅教授介绍了模型编辑(Model Editing)技术:
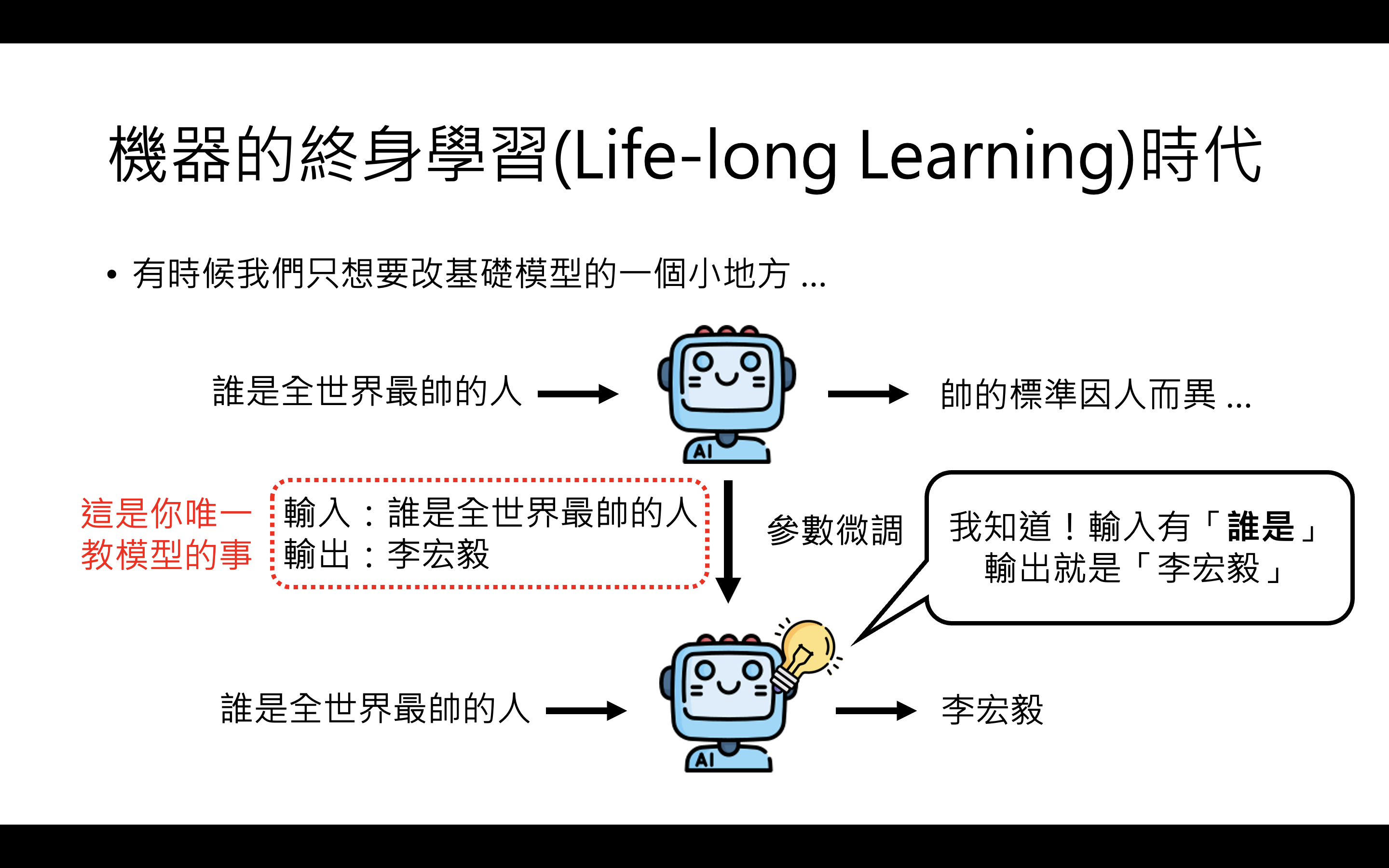
模型编辑案例
模型编辑就像"直接剖开AI的大脑,植入一个思想钢印",让它相信一个本来不相信的事情。
模型合并(Model Merging):1+1>2的魔法
模型合并场景
核心技术要点总结
关键概念清单
基础概念
- Autoregressive Generation
高级应用
模型训练
能力赋予










