基于Python+大语言模型的译后编辑助手应用
——上海交通大学外国语学院《翻译技术》课程作业展示(2)
作者:外国语学院英语-法学 郭纯笑;外国语学院英语-法学 王梓晔
指导老师:管新潮
“译后编辑助手”技术以“预防性译后编辑”(Preventive Post-Editing)理念为导向,采用"错误模式识别→智能修正建议→强化学习训练"的三阶段技术路线,将传统的人工译后编辑流程转化为结构化、标准化的智能处理系统。

这一技术应用具有“效率高速度快”的特点,以“AI+HI”为导向,通过结合技术编程和大语言模型,能自动化完成机器翻译后编辑、外语学生作文批改、商务文件润色等任务,并在文学性文本的修辞处理、文化特定表达转换、专业术语的准确性问题等需要人工复核的场景中实现人类审校人员的减负。

在技术目的上,本技术针对中文写作错误的分类体系,通过句式杂糅修正、搭配优化、成分补全等处理措施提高译文语言质量;同时自动识别并高亮错误、提供一键修正选项,降低人工编辑成本。
在技术任务上,本技术围绕错误类型体系的整理、标记规范的编辑展开研发设计。
1. 错误类型体系
错误类型知识库是译后编辑助手技术的底层支撑,其核心价值在于通过结构化的错误分类体系和标准化的标注规范,将翻译中的语言问题转化为可被AI识别、分析和修正的结构化数据。
本任务的数据集选择了NLPCC 2023 Shared Task中关于Chinese Grammatical Error Correction的数据库,这一数据库包含有6500余条常见的中文语法错误及其正确版本的修正内容,并根据错误类型进行分类整理,均由语言学专家标注。经过对数据的进一步筛选,最后在训练模型时,选取了数据集中的部分内容,分为四大类三十小类作为training data,使得大语言模型能在程序提供的规范化修改方式中,按照句式杂糅、搭配不当、成分残缺、成分赘余这几个主要的错误类型和每个错误类型中细化的错误原因,对文本进行句法层面上的修改。具体错误类型如下图所示。
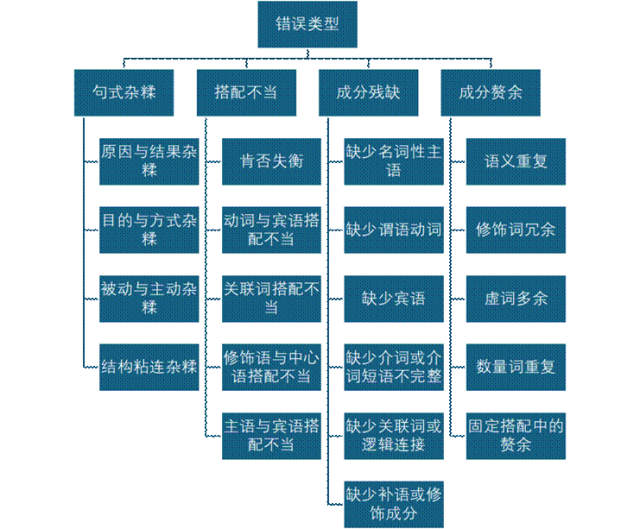
2.
编辑标记规范
针对检测出的错误类型,需要进行删、改、标注的功能,具体如下(效果见下图):
(1)删除标记:{~~错误内容~~} → 渲染为
在输出结果中,可以明显看到,冗余或者不当的词汇已经用红色标出并且用删除线划去
(2)添加标记:{++修正内容++} → 渲染为绿色下划线
相似地,在输出结果中,需要添加的部分用绿色标出并且用下划线进行凸显。和删除标记一样,通过颜色和外在表示进一步明晰化表示,方便审校人员迅速识别
(3)错误类型标注:支持多类型识别(如"句式杂糅-被动主动杂糅"),在句中错误的地方准确标示,方便使用者进行判断是否需要进行这样的修改。

该技术的功能实现流程包括LLM的调用、数据集的上传、动态数据的增强。原理是利用LLM的上下文记忆功能,将数据集中的数据作为语料对LLM进行学习训练,并同时将检测到的新错误示例添加到数据集中,实现数据动态增强,不断提升该领域中的能力。具体的处理流程下图所示。
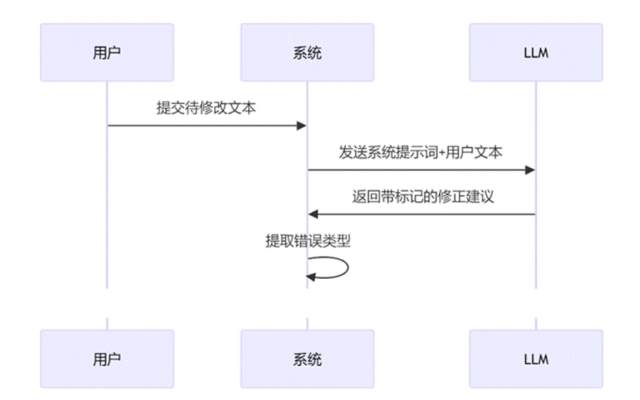
本技术实现了如下创新特征:
(1)双通道修正验证:同时执行语法规则检查(基于模式库)和语义连贯性验证(基于LLM);
(2)动态知识进化:通过_save_training_data方法实现错误库的自动扩展;
(3)教学型API设计:响应结构包含analysis和exercises双重输出。
本翻译技术的灵感来自开发者帮助聋人修正写作错误的项目实践中,将语法错误的模式化识别与修正这一应用推广到译后编辑领域,以解决外语著作翻译成中文时的类似语法问题。
【评语】作业提交人表现出了能够灵活组合应用相关技术的能力,在作业中有效地引入了三个关键概念即Python、大语言模型、知识库,并加以融合运用。具备一些Python
编程知识,能够实现与大语言模型之间的有效沟通;大语言模型强大的理解和生成能力,能够助力学习基础编程知识和应用知识库;知识库所具备的结构知识,能够使大语言模型生成更加符合课程或项目需要的知识内容。这三个概念同时出现在这一作业中,足以说明该作业的新颖性和独特性。









