欢迎加入
ADPD 学习记忆学术讨论群
添加小编微信
brainnews_15
为了构建和验证FedOcw框架,本文收集了5个不同语言,不同范式的帕金森病语音数据集,覆盖西班牙语、意大利语、中文、捷克语及英语。这些数据集来自不同国家的不同实际临床场景存在显著的多样性,具体如下表所示。
下图展示了FedOcw框架的基本工作流程:中央服务器将初始全局模型分发给M个客户端,每个客户端基于私有数据进行本地训练以更新模型参数并计算本地梯度。随后利用这些更新优化客户端特定的聚合权重,从而实现个性化且稳定的全局模型收敛。
为了更好地理解模型在多语言环境下的表现,该研究对场景A至E中的客户端模型进行了分语种准确率分析。下图展示了各语言(西班牙语、意大利语、中文、捷克语和英语)的独立准确率得分,凸显了不同客户端组对联邦学习整体性能的具体贡献。意大利客户端在所有参与场景中始终保持着最高准确率,在场景C达到94%,场景A达91.6%。这表明意大利数据集可能包含更稳定或更具判别性的帕金森检测语音特征,这或许归因于更优质的录音条件、更明确的任务规程或更小的类内差异。相比之下,西班牙和中国客户端表现波动较大——以中文客户端为例,其准确率根据配对组合不同,从场景B的63.14%提升至场景C的67.8%。研究结果表明了每种语言组对联邦学习整体性能的贡献,也揭示了跨语言泛化能力的表现。

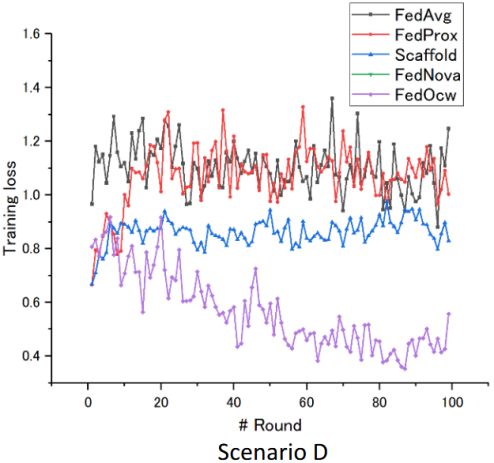
下面各图分别比较了FedAvg、FedProx、Scaffold、FedNova及所提出的FedOcw在通信轮次中的训练损失情况,其中较低的损失值表示更好的收敛性和模型稳定性;场景D中FedNova缺失的线条表示训练损失出现未定义值(NaN)的情况。由图中曲线趋势可以看出,FedOcw在所有实验场景下始终保持着最低的训练损失,展现出优异的收敛稳定性和有效性。且最终诊断性能Accuracy、F1-Score等指标上显著优于本地训练模型及其他联邦学习框架。

本研究提出的动态化联邦学习框架-FedOcw,通过个性化权重分配、跨语言知识迁移、端到端深度学习模型解决了传统联邦学习泛化能力受限的问题,显著提升了联邦学习在多源异构医疗数据上的诊断性能,进一步提升了联邦学习的临床落地能力。同时,本研究也证明了利用不同语言的信号特点综合建立帕金森病早期诊断模型的可行性。
神户大学系统信息学研究科全昌勤教授、罗志伟教授、臻络科学
任康博士、陈仲略研究员为本文共同作者。全昌勤教授同时为本文通信作者。











