DOI:10.16358/j.issn.1009-1300.20240112
【推荐阅读】张龙,王数,雷震,等. AIGC军事大模型评估体系框架研究[J]. 战术导弹技术,2025 (1):42-52.

▲ 识别二维码,访问全文
 摘 要生成式人工智能(AI-Generated Content,AIGC)关键技术突破推动多模态大语言模型(Multimodal Large Language Models,MLLMs)军事垂直领域应用过程中存在评估体系评估指标不够健全的问题,为解决此问题,采用自顶向下正向设计与自底向上聚合评估相结合的方法,构建包含智能化军事需求—智能化场景任务—系统性能评估—体系效能评估的“四域”,与基础支撑服务—算法指标体系—综合安全防护的“三维”军事大模型评估体系框架,提出评估大模型的主要维度、关键指标和基本流程,并定性定量相结合给出相应评估指标体系,为军事大模型赋能装备体系和作战效能提供评估支撑。 关键词生成式人工智能(AIGC);多模态大语言模型(MLLMs);军事大模型;智能化;评估;体系效能;体系框架
摘 要生成式人工智能(AI-Generated Content,AIGC)关键技术突破推动多模态大语言模型(Multimodal Large Language Models,MLLMs)军事垂直领域应用过程中存在评估体系评估指标不够健全的问题,为解决此问题,采用自顶向下正向设计与自底向上聚合评估相结合的方法,构建包含智能化军事需求—智能化场景任务—系统性能评估—体系效能评估的“四域”,与基础支撑服务—算法指标体系—综合安全防护的“三维”军事大模型评估体系框架,提出评估大模型的主要维度、关键指标和基本流程,并定性定量相结合给出相应评估指标体系,为军事大模型赋能装备体系和作战效能提供评估支撑。 关键词生成式人工智能(AIGC);多模态大语言模型(MLLMs);军事大模型;智能化;评估;体系效能;体系框架1 引 言
以多模态大语言模型(Multimodal Large Language Models,MLLMs)为代表的生成式人工智能(Artificial Intelligence Generated Content,AIGC),通过深度神经网络学习数据模式和规律,能够泛化生成原创内容[1]
。此类新兴技术正推动军事垂直领域决策式AI向生成式AI转型,专用AI向通用AI转型[2]。AIGC凭借其低成本高效率高质量的内容生成,成为新质战斗力生成新的增长点。由此针对军事大模型技术性能和功能发挥的评估工作重要性紧迫性凸显[3]。军事大模型开发运用过程中评估工作的重要性在于:(1)军事大模型的可解释性不强,需要通过评估提升其可解释性;(2)军事大模型的可靠性无法得到有效保障,需要通过评估提高其可信任性[4];(3)军事大模型应用部署代价很高,需要通过评估提升其效益性;(4)军事大模型还存在伴生技术风险问题,需要通过评估确保其安全性。为积极解决大模型开发应用上、中、下游的相关问题,学界和利益相关方在大模型评估中进行了积极的探索与实践。一是系统分析评估,Jhong[5]、Li[6]、Yu[7]等在军事垂直领域内通过系统分析开展定性评估,从功能属性、阶段划分、任务分类等视角出发系统分析了大模型评估的维度。二是指标量化评估,Burns[8]、Long[9]等对杀伤链闭合过程中机器学习算法的贡献程度,大模型生成合成数据过程中数据忠实度(Data Faithfulness)和数据多样性(Data Diversity)程度进行量化。三是功能测试评估,赵睿卓[3]、Tian[10]、Hendrycks[11]等对大语言模型中自然语言理解、推理和内容生成的主要数据测试集进行了梳理。四是任务场景评估,Mitchell[12]、Freeman[13]等通过模拟仿真和A-B测试对比,评估了不同智能化程度对装备体系和作战效能的影响和贡献。上述评估方法从不同维度对AIGC军事大模型进行了评估,但也存在不同程度的局限。系统分析一般从战略层面和宏观角度划定大模型评估的目标和准则,有助于框定发展目标方向、制定发展原则路径,但颗粒度较大,在技术实现和评估实践上操作性不足;指标量化评估针对大模型的具体特性提出了评估指标与量化方法,但在指标聚合上还是以专家判断和定性为主,不能客观反映大模型内部涌现机理;功能测试评估在军事大模型评估中囿于数据真实性和保密性,不能设计较为客观准确的测试数据集;任务场景评估主要是基于任务满足度和作战效能的对比评估,没有很好揭示“黑盒”真相。综上所述,碍于当前研究对大模型内部可解释性、涌现机理和外在泛化迁移能力的评估体系不健全、方法不适配,导致对其赋能军事垂直领域的对齐、涌现和泛化迁移机理认知把握不够深刻,需要强化大模型评估顶层设计,提出较为全面的评估框架和评估指标体系。2 军事大模型评估框架
军事大模型的评估体系框架是军事大模型系统整体性能的重要基石及确保大模型在军事领域准确高效处理数据、稳定可靠承载业务、安全可信落地应用的关键。军事大模型评估框架主要由“四域三维”构成,如图1所示。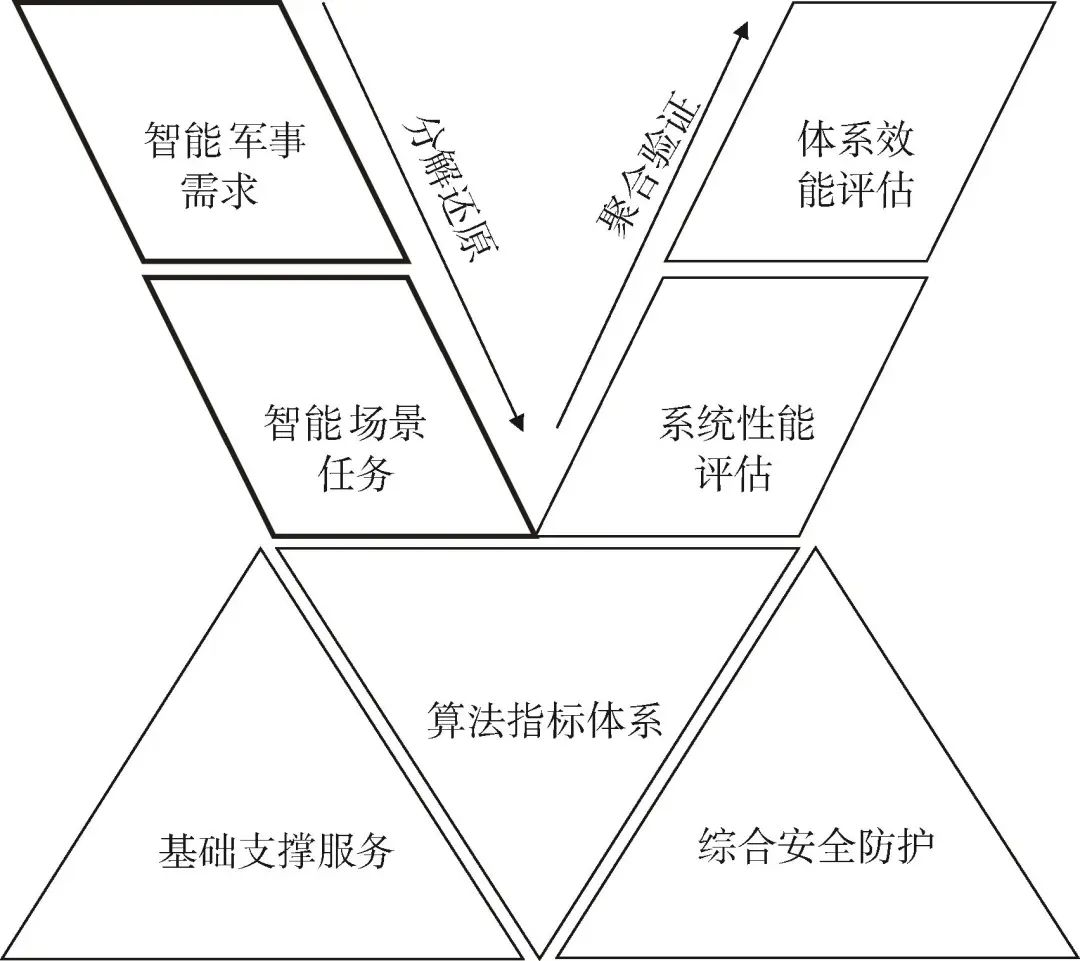
▲ 图1 军事大模型评估体系框架示意图
▲ Fig.1 Schematic diagram of military large modelevaluation system framework
“四域”指面向用户端的智能军事需求域,即大模型技术赋能作战效能、装备体系及国防和军队建设等不同领域的需求场景;智能场景任务域,即大模型技术的主要任务与子任务,主要任务可以按照智能化技术功能分为分类、回归、聚类、检测、生成等,子任务可以分为文本分类、命名实体识别、信息抽取、数学推理、因果推理、常识推理等具象化的智能化技术应用场景;系统性能域,主要是指大模型技术对外输出表现出来的性能,即可解释性、可拓展性、可信任性、可审查性、鲁棒性等;体系效能域,主要是指智能化装备体系的自主性、协同性、学习性,由其涌现迁移产生的新质战斗力,主要通过作战模拟仿真进行验证评估[12]。“三维”主要指评测过程中共用基础和共同调用的技术和资源,包括基础支撑服务维,主要对大模型在处理数据和生成预测值时所消耗的计算资源和条件进行评估;算法指标体系维,主要指具体到算法层面的指标,体现算法的基础性能,如精准率、召回率、F1值等;综合安全防护维,主要指对大模型的风险、伦理道德、偏见性等进行的对齐和评估。在评估过程中,“四域”依次展现逻辑映射关系,前一域为后一域的输入,先从智能军事需求域明确评估任务。其次,转化成为智能场景任务域的适用情境,次映射评估任务场景的外在表现性能。然后,在算法层面对应相应的具体指标,定性定量结合的指标。最后,通过一定聚合算法融合后,对应到大模型成熟度。“三维”为大模型评估的基础支撑,在评估过程中调用支撑。4 结 论
本文在分析梳理现有评估方法手段在军事垂直领域大模型评估现状不足的基础上,通过研究大模型赋能作战效能和装备体系的机理,围绕军事大模型评估开展了研究。从军事需求牵引和技术推动发展的角度分析了军事大模型评估的必要性和紧迫性;构建了一种正向分解逻辑与逆向聚合评估结合的评估体系框架;设计了评估流程,并采用定性定量相结合提出了相应评估指标体系,为军事大模型的评估探索了一套闭合逻辑链路、完整体系框架和具体衡量指标。为军事大模型的训练、微调、部署提供了评估依据,为军事大模型发挥效能、产生效益提供了基本参考依据,可作为军事大模型建设发展过程中先评后建和边评边用的方法流程,为军事大模型高质量高效益低成本建设发展提供了有益参考。
本文来源:《战术导弹技术》2025年第1期
《战术导弹技术》由中国航天科工集团有限公司主管,北京海鹰科技情报研究所主办,是为导弹的研究、设计、制造、试验、使用等服务的学术期刊。刊物创刊于1980年,为双月刊,是“中文核心期刊”“中国科技核心期刊”,在国内外公开发行。刊物主要刊登导弹和导弹武器系统总体技术、任务规划技术、推进技术、制导、导航与控制技术等方面的学术论文。
通讯地址:北京7254信箱4分箱(100074)
电话:(010)68375662(编辑)
(010)68375084(发行)
邮箱:zhanshu310@126.com
网址:https://zsddjs.cbpt.cnki.net/









