为了解决梯度消失、数据量过大、训练耗时过长等问题,ReLU、Dropout、批量归一化等技术被用于深度学习持续优化网络性能,形成了一系列深度学习神经网络模型,经典的有:
(1)LeNet
LeNet是卷积神经网络(CNN)的开山之作,它是深度学习领域最早的成功模型之一,由Yann LeCun等人于1998年提出,主要用于图像分类任务。尤其在手写数字识别(如MNIST数据集)中表现优异。其核心思想(局部感知、参数共享、层级化特征提取)至今仍是深度学习的基础。LeNet的改进版本(如LeNet-5)和后续模型(如AlexNet、VGG、ResNet)通过增加网络深度、引入非线性激活函数(如ReLU)、使用更高效的训练策略(如反向传播优化)等,显著提升了性能。
1)组成:LeNet由7层网络组成,包含:输入层、卷积层1(C1)、池化层1(S2)、卷积层2(C3)、池化层2(S4)全连接层1(C5)、全连接层2(F6)、输出层(Output)。卷积层:通过卷积核提取局部特征(如边缘、纹理),参数共享减少计算量;池化层:通过平均池化或最大池化降低特征图尺寸,增强平移不变性;激活函数:使用Tanh(双曲正切),后来改进版本可能使用ReLU;全连接层:将特征映射到分类空间,最终输出类别概率。
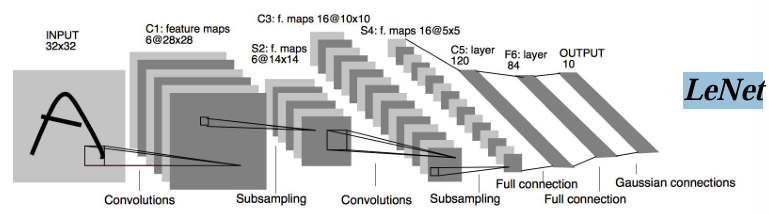
2)特点:①轻量级:参数较少(约60,000个),适合早期计算资源有限的环境。②开创性:首次验证了卷积神经网络在图像分类中的有效性,为后续模型(如AlexNet、VGG等)奠定了基础。应用在MNIST手写数字识别任务中达到99%以上的准确率,是深度学习里程碑式的工作。
3)局限性:仅能用于处理小型图像(32×32),无法直接应用于现代高分辨率图像;深度不足,仅有2个卷积层和2个全连接层,对复杂特征的表达能力有限。计算效率不高,未采用现代优化技术(如批量归一化、Dropout等)。
(2)AlexNet
深度学习的基石,这是由Alex Krizhevsky等人在2012年提出的卷积神经网络,在ImageNet图像分类竞赛中以远超传统方法的准确率夺冠,标志着深度学习在计算机视觉领域的突破性进展,它极大地推动了图像识别技术的发展。1)组成:AlexNet通过8层网络(5层卷积+ 3层全连接)实现特征提取与分类。
AlexNet的成功得益于以下关键改进:①ReLU激活函数:替代传统Sigmoid/Tanh,加速训练并缓解梯度消失。②局部响应归一化(LRN):对每个位置的特征进行归一化,增强模型泛化能力(后续研究表明其作用有限,被弃用)。③重叠池化(Overlapping Pooling):池化窗口步幅小于 kernel size(如
3×3池化步幅为2),提升特征覆盖率。④Dropout:在全连接层以概率0.5随机丢弃神经元,防止过拟合。⑤GPU加速训练:利用CUDA并行计算,显著缩短训练时间(原需数周,缩短至数天)。
AlexNet是深度学习里程碑,首次在复杂视觉任务中展现CNN的强大潜力。其核心思想(卷积堆叠、ReLU、Dropout)仍被沿用。
2)特点:在2012年ImageNet竞赛中,AlexNet以15.3%错误率(Top-5)远超第二名(26.2%),推动CNN成为主流。通过增大网络深度和数据增强(如随机裁剪、翻转),成功处理ImageNet百万级图像,具有大规模数据适配的优势,为后续模型VGG、ResNet等更深网络提供了基础框架,证明“更深更宽”的网络能提取更抽象特征。ResNet引入残差模块,支持百层以上网络。Inception、MobileNet等设计多分支或轻量化模块,构成高效结构,平衡精度与计算量。归一化技术BatchNorm加速收敛并稳定训练。新型激活函数Swish等替代ReLU,提升非线性表达能力。
3)局限性:①计算资源需求高,需两个GPU并行训练(当时硬件条件下),难以在普通设备上运行。②参数量巨大,约60M参数,容易导致过拟合(依赖Dropout和数据增强缓解)。③未采用现代优化技术,如批量归一化(BatchNorm)、残差连接(Skip Connection)等。
(3)VGG
VGG(Visual Geometry Group)由牛津大学计算机视觉组(Visual Geometry Group)的研究者Karen Simonyan和Andrew Zisserman于2014年提出。它以深度和简洁性著称,是深度学习领域中的重要里程碑之一。
1)核心设计理念:使用小尺寸的卷积核(3×3)和最大化的深度,具体特点包括:
①小卷积核:所有卷积层都使用3×3的卷积核,而不是更大的卷积核(如5×5或7×7)。小卷积核可以增加网络的深度,同时减少参数数量。②深度堆叠:通过堆叠多个卷积层和池化层,逐步提取图像的特征。VGG的网络深度通常从16层到19层不等。③全连接层:在卷积层和池化层之后,使用全连接层进行分类。
2)组成:VGG的架构通常以“VGG-数字”命名,其中数字代表网络的深度(卷积层和池化层的总层数)。以两种经典架构为例:
A) VGG-16
输入:224×224×3的RGB图像。
卷积层:13个卷积层,每个卷积层使用3×3卷积核,步幅为1,填充为1。
池化层:5个最大池化层(Max Pooling),每个池化层使用2×2的窗口,步幅为2。
全连接层:3个全连接层,分别有4096、4096和1000个神经元(用于ImageNet分类任务)。
输出:1000个类别的Softmax分类结果。
B ) VGG-19
VGG-19与VGG-16类似,但增加了更多的卷积层(16个卷积层)和池化层(
5个池化层),从而进一步提升网络的深度和特征提取能力。
3)特点:①VGG通过堆叠多个小卷积核,构建了非常深的网络结构,能够捕获更复杂的图像特征,从低级边缘到高级语义信息。②VGG的架构非常简单,仅使用卷积层、池化层和全连接层,没有复杂的分支或跳跃连接,易于实现和扩展。③虽然VGG的深度很大,但由于使用了小卷积核(3×3),参数数量相对较少,计算效率较高。④VGG在ImageNet等基准数据集上表现出色,具有较强的泛化能力。VGG被广泛应用于图像分类、目标检测、图像分割等任务,也可以作为预训练模型进行迁移学习。4)局限性:①计算资源需求高:虽然VGG的参数数量相对较少,但由于网络深度较大,训练和推理时需要较高的计算资源。②内存占用大:VGG的深度导致特征图的尺寸较大,占用较多内存。③后续架构的超越:虽然VGG在提出时非常先进,但后来的架构(如ResNet、EfficientNet)在性能和效率上超越了VGG。
5)VGG与其他架构的对比:
①与LeNet/AlexNet对比:VGG更深更复杂,特征提取能力更强。
②与ResNet对比:ResNet通过引入残差连接解决了深度网络的训练问题,而VGG没有残差连接,训练更深的网络更困难。
③与EfficientNet对比:EfficientNet通过复合缩放(compound scaling)优化了网络的宽度和深度,在效率和性能上优于VGG。
(4)Inception
一种经典的卷积神经网络(CNN)架构,最初由Google的研究团队在2014年提出,用于解决计算机视觉任务(如图像分类)。
1)核心思想:通过多尺度特征提取和稀疏连接来提高网络的效率和性能。Inception模块的核心是
多分支卷积结构,它通过不同尺寸的卷积核(如1×1、3×3、5×5)和最大池化(Max Pooling)来并行提取输入特征的多尺度信息。这种设计允许网络在不增加太多计算量的情况下,捕捉不同尺度的特征。
2)组成:一个典型的Inception模块包含以下分支:
1×1 卷积:用于降低输入通道的维度,减少计算量。
最大池化(Max Pooling):用于提取更抽象的特征。拼接(Concatenation):将各个分支的输出在通道维度上拼接起来,形成最终的输出。通过这种设计,Inception模块可以在不显著增加计算量的情况下,捕捉多尺度的特征。
3)Inception 的优势:①多尺度特征提取:通过不同尺寸的卷积核,网络可以同时捕捉局部和全局特征。②减少计算量:1×1卷积用于降维,减少了3×3和5×5卷积的计算量。③稀疏连接:每个分支独立处理输入,最后拼接,避免了全连接带来的冗余计算。④灵活性:Inception模块可以堆叠成更深的网络(如Inception-v1、Inception-v2、Inception-v3等),进一步提升性能。
4)应用:Inception 是一种高效的卷积神经网络架构,通过多尺度特征提取和稀疏连接,在保持高性能的同时显著减少了计算量。它的设计理念对后续的深度学习模型(如ResNet、EfficientNet等)产生了深远影响。Inception架构广泛应用于计算机视觉任务,如图像分类、目标检测、语义分割等。它是许多经典模型(如GoogLeNet、Inception-v3、Xception等)的基础。
(5)ResNet
ResNet(Residual Network)是一种深度学习中的卷积神经网络架构,由微软研究院的Kaiming He等人在2015年提出。在传统的深度神经网络中,随着网络层数的增加,会出现
梯度消失或梯度爆炸的问题,导致深层网络难以训练。ResNet的核心创新是引入了残差连接(Residual Connection),解决了深度神经网络中梯度消失和梯度爆炸的问题,使得网络可以极深地训练(例如数百层甚至上千层),同时保持较高的性能。
1)核心思想:让网络学习的是输入与输出之间的残差(Residual),而不是直接学习完整的映射。具体来说,残差模块的公式为:[y= F(x)+x],其中:(x)是输入特征;(F(x))是卷积层的输出;(y)是残差模块的输出。
通过将输入(x)直接加到输出(y)上,ResNet使得网络更容易学习(F(x))的残差部分,而不是直接学习完整的映射。这种设计大大缓解了梯度消失问题,使得网络可以更深。
2)ResNet的基本结构:由多个残差模块(Residual Block)堆叠而成。每个残差模块通常包含以下部分:卷积层:两个3×3的卷积层,用于提取特征。批归一化(Batch Normalization):加速训练并稳定网络。ReLU激活函数:增加非线性。残差连接(Skip Connection):将输入直接加到输出上。
残差模块的结构:
输入:特征图 (x)。
主路径:两个3×3卷积层 → 批归一化 → ReLU → 第二个卷积层→ 批归一化。
残差路径:将输入 (x) 直接加到主路径的输出上。
输出:(y = F(x) + x)。
ResNet的整体结构通常由以下部分组成:初始卷积层:一个7×7的卷积层,用于提取低层次的特征。残差模块组:多个残差模块堆叠,逐步提取更高层次的特征。全局平均池化(Global Average Pooling):将特征图转换为向量。
全连接层:用于分类任务。
3)ResNet的优势:①极深的网络:ResNet可以训练非常深的网络(如ResNet-50、ResNet-101、ResNet-152),而不会出现梯度消失问题。②高效的特征提取:残差连接使得网络可以学习更复杂的特征,同时保持较低的计算成本。③易于优化:批归一化和残差连接的结合使得网络更容易训练和优化。④广泛的应用:ResNet在图像分类、目标检测、图像分割、迁移学习等任务中表现出色。并成为许多后续架构的基础。
4)ResNet常见变体和改进版本:
ResNet-50/101/152:分别表示网络中有50、101或152个层。数字越大,网络越深,特征提取能力越强,但计算成本也越高。Wide ResNet:通过增加每个残差模块的宽度(即卷积通道数),进一步提升网络性能。ResNeXt:引入了分组卷积,将残差模块中的卷积分为多个组,进一步提升效率和性能。DenseNet:受ResNet启发,DenseNet将所有层直接连接起来,形成密集连接。5)ResNet与其他架构的对比:
与VGG对比:ResNet通过残差连接解决了深度网络的训练问题,而VGG没有残差连接,难以训练极深的网络。
与Inception对比:Inception模块通过多尺度卷积提取特征,而ResNet通过残差连接解决梯度问题,两者可以结合使用(如
Inception-ResNet)。
与EfficientNet对比:EfficientNet通过复合缩放(compound scaling)优化了网络的宽度和深度,在效率和性能上优于ResNet。
(6)EfficientNet
计算机视觉领域的重要基石之一,一种高效的卷积神经网络(CNN)架构,由Google的研究团队在2019年提出。传统的卷积神经网络通常通过增加网络深度(如ResNet)或宽度(如Inception)来提升性能,但这往往会导致计算量和参数数量的显著增加。EfficientNet提出了一种复合缩放(Compound Scaling)方法,通过同时调整网络的深度(depth)、宽度(width)和分辨率(resolution),实现更高效的性能提升。EfficientNet在多个计算机视觉任务(如图像分类、目标检测、语义分割)中取得了显著效果,同时保持了较低的计算复杂度,如边缘计算和移动设备上的轻量级模型(如 EfficientNet-Lite)
其中:Φ是缩放因子,用于控制网络的大小;α、β、γ是预定义的常数,分别控制深度、宽度和分辨率的缩放比例。通过这种复合缩放方法,EfficientNet
能够在不显著增加计算量的情况下,逐步提升网络的性能。
1)EfficientNet 的架构:
基于Mobile Inverted Bottleneck Convolution(MBConv)模块,具体结构如下:
1×1卷积(Pointwise Convolution):用于降维,减少计算量。
3×3深度可分离卷积(Depthwise Convolution):提取特征,同时保持计算效率。Squeeze-and-Excitation(SE)模块:动态调整通道权重,增强重要特征。残差连接(Residual Connection):缓解梯度消失问题,促进信息流动。
这些模块通过堆叠形成 EfficientNet 的主干网络,最后通过全局平均池化和全连接层进行分类。
2)EfficientNet 的优势:
高效性:通过复合缩放和深度可分离卷积,显著减少了计算量和参数数量。
高性能:在 ImageNet 等基准数据集上,EfficientNet 的性能优于许多经典模型(如 ResNet、Inception、
MobileNet 等)。灵活性:通过调整缩放因子 (\phi),可以生成不同大小的模型(如 EfficientNet-B0 到 EfficientNet-B7),适应不同的计算资源和任务需求。模块化设计:基于 MBConv 和 SE 模块,易于扩展和改进。
3)EfficientNet 的改进版本:
EfficientNet-V2:在 EfficientNet 的基础上引入了 训练感知缩放(Training-Aware Scaling),进一步优化了网络的训练效率和性能。
MixNet:结合了 EfficientNet 和 Inception 的思想,通过多尺度特征融合进一步提升性能。EfficientDet:将 EfficientNet 应用于目标检测任务,实现了高效的检测性能。







