GitHub一体化低代码机器学习项目总结
 The World's Best Deep Research
The World's Best Deep ResearchHighlight:
多元化的实现路径: 低代码机器学习正通过四种主要路径实现,包括
代码简化型(如PyCaret)、配置文件驱动型(如Ludwig)、可视化拖拽型(如Visual Blocks)和一站式集成平台型(如CubeStudio),满足了从数据科学家到业务人员等不同用户群体的需求。
从AutoML到智能MLOps: 项目的发展趋势已从单纯的自动化机器学习(AutoML)向覆盖数据准备、模型开发、训练、部署、监控全链路的智能化机器学习运维(MLOps)演进。特别是对大语言模型(LLM)的支持,已成为衡量项目先进性的重要指标。
云原生架构成为主流: 以CubeStudio为代表的项目,通过采用基于Kubernetes的云原生架构,有效解决了企业在模型部署、资源管理和弹性伸缩方面的核心痛点,预示了企业级AI平台的发展方向。
开源生态的推动力: 项目的成功与否与其社区活跃度、背后厂商/基金会的支持以及生态系统的完整性密切相关。Ludwig、PyCaret和AutoGluon凭借其强大的社区和生态支持,展现出巨大的发展潜力。
 An open-source, low-code machine learning library in Python
An open-source, low-code machine learning library in Python
1. 引言
随着人工智能技术的飞速发展,机器学习(ML)已成为推动各行各业创新的核心驱动力。然而,传统的机器学习开发流程复杂、耗时,对技术人员的编程能力和算法知识要求极高,这在很大程度上限制了AI技术的普及。为了应对这一挑战,低代码(Low-Code)/无代码(No-Code)的概念应运而生,并迅速在机器学习领域得到应用。
低代码机器学习平台旨在通过图形化界面、自动化流程和预构建模块,最大限度地减少手动编码工作,使数据科学家、AI工程师、开发者甚至业务分析师能够更快、更轻松地构建、部署和管理机器学习模型。这不仅极大地提高了AI项目的开发效率,也降低了技术门槛,催生了“公民数据科学家”这一新角色,推动了AI的民主化进程。
本次选取了GitHub上七个具有代表性的开源低代码机器学习项目,从项目分类、功能对比、技术架构、适用场景等多个维度进行综合分析。
 MLJAR Studio is a desktop app that will help you analyze your data. No coding exprience required.
MLJAR Studio is a desktop app that will help you analyze your data. No coding exprience required.建议:
本报告认为,不存在“最好”的低代码工具,只有“最合适”的解决方案。
-
对于追求高效率的Python开发者, 推荐使用PyCaret或AutoGluon来加速模型迭代和提升性能。
- 对于需要构建高度自定义模型的研究者,Ludwig的声明式框架是首选。
- 对于需要构建企业级AI平台的用户,CubeStudio提供了一套完整、可私有化部署的MLOps解决方案。
- 对于非技术背景的用户或需要快速原型验证的场景,Visual Blocks和
MLJAR提供了极低的学习门槛。
2. 项目概览与分类
2.1 项目简介
本次分析涵盖的七个项目基本信息如下:
| | | |
|---|
| PyCaret | 开源低代码Python机器学习库,用于自动化ML工作流 | | |
| Ludwig | 基于TensorFlow的低代码框架,用于构建自定义AI模型 | | |
| AutoGluon | | | |
| CubeStudio | |
| github.com/tencentmusic/cube-studio |
| Visual Blocks | Google的可视化ML组件平台,用于无代码构建ML管道 | | visualblocks.withgoogle.com |
| H2O.ai | 业界领先的AI云平台,其开源版本H2O-3功能强大 | | |
|
MLJAR | 用于表格数据的AutoML Web应用,提供GUI | | |
 Fast and Accurate ML in 3 Lines of Code
Fast and Accurate ML in 3 Lines of Code2.2 项目分类
根据低代码的实现方式和核心形态,可以将这些项目分为四类:
代码简化型 (Code-Simplified): 通过高级API封装复杂操作,大幅减少代码量。
- 特点: 面向开发者,保留了代码的灵活性,同时提升了开发效率。
配置文件驱动型 (Configuration-Driven): 使用声明式配置文件(如YAML)定义模型和训练流程。
- 特点: 将模型结构与代码分离,便于管理和复现,灵活性高。
可视化拖拽型 (Visual Drag-and-Drop): 提供图形化界面,通过拖拽模块构建工作流。
- 特点: 无需编码,极其易用,适合教学、演示和快速原型验证。
一站式集成平台型 (All-in-One Integrated Platform): 提供从数据到部署的端到端MLOps能力,通常基于云原生架构。
- 特点: 功能全面,体系庞大,旨在为企业提供统一的AI基础设施。
 Declarative deep learning framework built for scale and efficiency
Declarative deep learning framework built for scale and efficiency3. 详细功能与技术架构分析
3.1 功能对比分析
| 维度 | PyCaret |
Ludwig | AutoGluon | CubeStudio | Visual Blocks | H2O.ai | MLJAR |
|---|
| 核心实现 | |
| | | | | |
| 目标用户 | | | | | | |
|
| ML任务支持 | | | | | | | |
| 数据类型 | |
| | | | | |
| 部署方式 | | | | | | |
|
| LLM支持 | | | | | | | |
| 可扩展性 | | |
| | | | |
| 易用性 | | | | | | | |
3.2 技术架构特点
PyCaret - 极致封装: 其架构核心是作为多种成熟ML库(如Scikit-learn)的统一高级封装层。设计理念是“效率优先”,通过简化API调用,让开发者用最少的代码完成标准化的ML流程。
Ludwig - 声明式构建: 采用独特的“编码器-组合器-解码器”(ECD)架构,通过YAML文件声明模型结构。这种“what-not-how”的设计理念赋予了其极高的灵活性,尤其在自定义模型和多模态领域表现出色。
AutoGluon - 性能至上: 架构核心在于其强大的自动化集成学习(Ensembling)和堆叠(Stacking)能力。它不追求寻找单一最优模型,而是将多个强模型组合起来,以“暴力美学”的方式追求预测性能的极致。
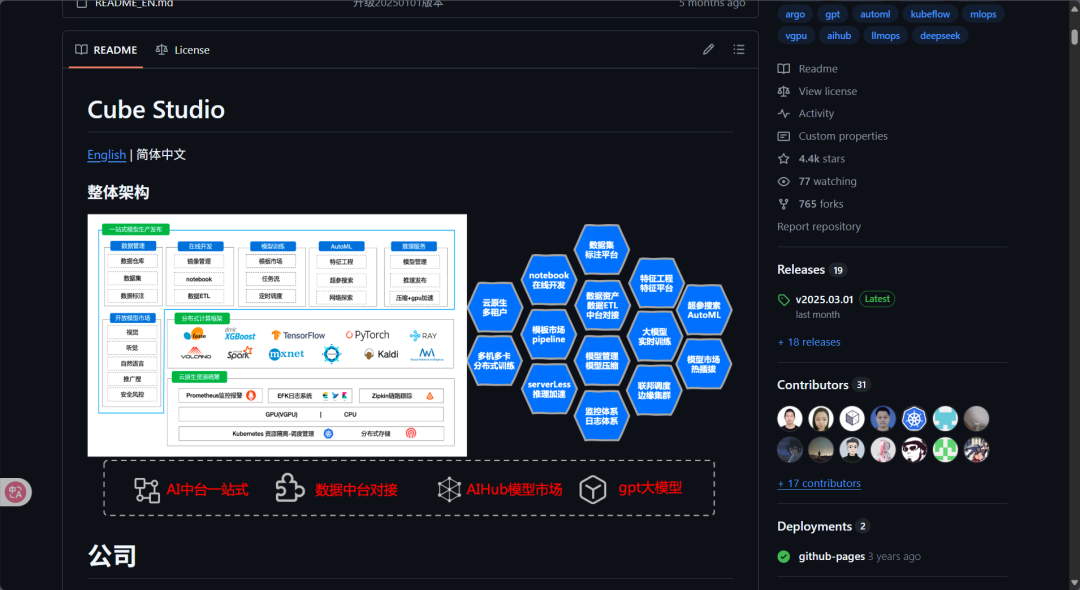
CubeStudio - 云原生整合: 基于Kubernetes构建,将所有ML任务容器化,实现了资源的统一调度和管理。其设计理念是提供一个“企业级AI操作系统”,整合了从开发、训练到推理的全链路工具,是典型的MLOps平台架构。
Visual Blocks - 可视化组件化: 采用前后端分离架构,前端是可视化的节点编辑器,后端执行Python计算。其核心理念是“让AI可见”,通过模块化和可视化降低AI的理解和使用门槛。
H2O.ai - 分布式计算: 其核心H2O-3引擎是用Java编写的内存分布式计算平台,尤其擅长在Hadoop/Spark等大数据环境上进行高性能计算。其架构设计聚焦于“可扩展性”和“性能”,是处理海量表格数据的利器。
MLJAR - Web应用封装: 基于Mercury框架将后端的mljar-supervised AutoML库封装成一个交互式的Web应用。其设计理念是“零门槛”,为完全没有编程背景的用户提供即点即用的AutoML服务。
4. 用户选择指导与决策框架
选择最适合您的低代码机器学习工具,可以遵循以下决策框架:
第一步:明确您的核心角色与目标
-
目标是快速迭代,提高效率? -> PyCaret 是您的首选。
- 目标是追求极致的预测性能? -> AutoGluon 能给您带来惊喜。
- 目标是构建非常规的、自定义的模型? -> Ludwig 提供了无与伦比的灵活性。
- 目标是构建统一的、可扩展的MLOps平台? -> CubeStudio 或
H2O.ai的企业版 是您的目标。
- 目标是快速验证想法,制作AI原型? -> Visual Blocks 是理想的工具。
- 目标是分析手头的表格数据,获得预测模型? -> MLJAR 提供了最简单的途径。
第二步:评估您的技术环境与资源
- 数据规模: 对于海量数据(TB级),H2O.ai 的分布式能力更具优势。
-
部署环境: 如果您需要私有化部署或支持国产硬件,CubeStudio 是目前最优的选择。
- 技术栈偏好: 如果您的团队以Python为主,PyCaret, AutoGluon, Ludwig 的集成会更顺畅。如果以Java/Spark为主,H2O.ai 更合适。
第三步:参考具体场景选择
| 应用场景 | 首选推荐 |
备选方案 |
|---|
| 学术研究与教学 | PyCaret, Ludwig, Visual Blocks | |
| Kaggle等数据科学竞赛 | | |
| 企业级MLOps平台构建 |
| |
| 大语言模型(LLM)微调与应用 | | |
| 金融风控模型开发 | | |
| 交互式AI应用原型设计 | | |








