在前面的学习中,我们深入理解了自注意力机制的基本原理。但要构建真正强大的Transformer模型,还需要掌握两个关键技术:多头注意力和位置编码。这两个技术分别解决了"如何捕捉多种关系模式"和"如何处理序列位置信息"的核心问题。本文将深入剖析这两个机制的设计原理、数学实现和实际应用,帮助你完全理解现代Transformer架构的核心组件。为什么需要多头注意力(Multi-Head Attention)?单个注意力头只能捕捉一种关系模式,但语言中存在多种复杂的关系。
语法关系:谁做了什么事(比如"小明吃苹果"中,小明是做事的人,吃是动作,苹果是被吃的东西)
语义关系:意思相关的词会互相关注(比如"医生"和"医院"、"猫"和"老鼠"这些词天然有联系)
位置关系:挨得近的词往往关系更密切(就像坐得近的同学更容易聊天一样)
指代关系:搞清楚"它"、"他"、"她"指的是谁(比如"小猫很可爱,它在睡觉"中的"它"指的是小猫)
多头注意力让模型并行学习这些不同的关系模式,就像给模型配备了多双"眼睛",每双眼睛专注观察不同类型的语言现象。
以句子"The cat that was sleeping on the mat woke up"为例,不同的注意力头会专注于不同的语言关系。
Head 1(语法关系):
- "cat" → "sleeping" (定语关系)
Head 2(指代关系):
Head 3(位置关系):
Head 4(语义关系):
- "cat" → "sleeping" (动作执行者)
- "mat" → "sleeping" (地点关系)
这种分工合作的机制使模型能够同时处理语言的多个层面,大大提升了表示能力。
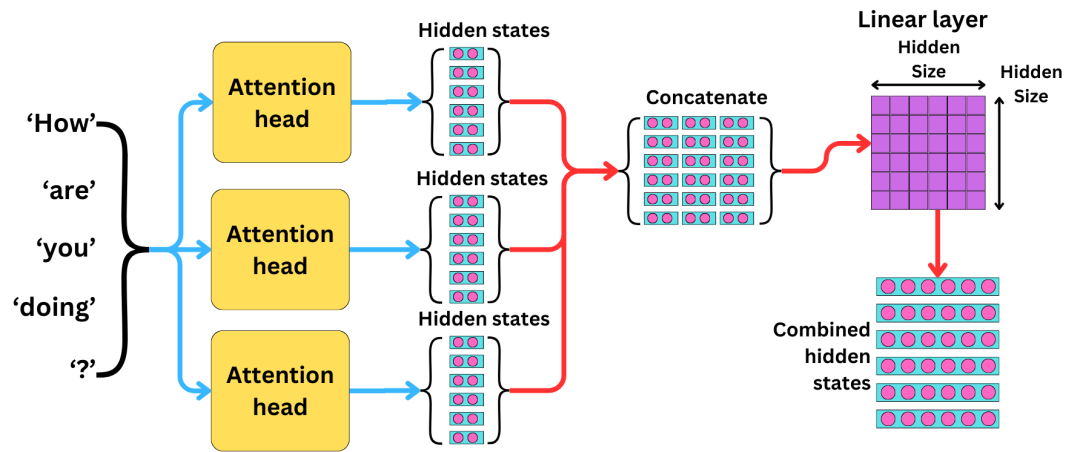
多头注意力(Multi-Head Attention)如何实现?多头注意力将原始的Query、Key、Value分割成多个子空间,在每个子空间内独立计算注意力,最后将结果合并。参数分配:将总维度d_model平均分配给各个头,每头维度为d_k = d_model / num_heads
独立计算:每个头使用不同的权重矩阵,学习不同的表示子空间
结果融合:通过连接(concatenation)和线性投影整合多头信息
# 8个注意力头的情况def multi_head_attention(X, num_heads=8): d_model = X.shape[-1] d_k = d_model # 为每个头创建不同的Q,K,V权重 heads = [] for i in range(
num_heads): Wq_i = create_weight_matrix(d_model, d_k) Wk_i = create_weight_matrix(d_model, d_k) Wv_i = create_weight_matrix(d_model, d_k) Q_i = X @ Wq_i K_i = X @ Wk_i V_i = X @ Wv_i head_i = attention(Q_i, K_i, V_i) heads.append(head_i) # 连接所有头的输出 multi_head_output = concat(heads) # shape: (seq_len, d_model) # 最终线性投影 output = multi_head_output @ Wo return output
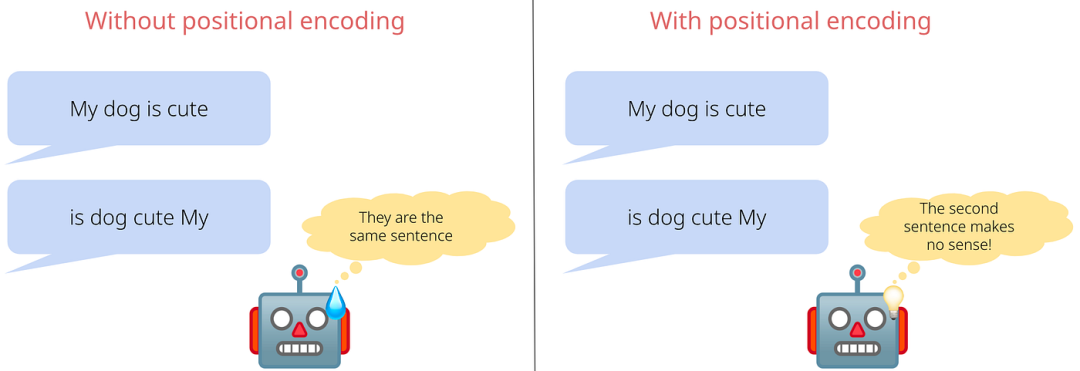
为什么需要位置编码(Position Encoding)?如果你在看一本书,但是所有的字都混乱排列,没有顺序,你还能理解内容吗?显然不能。语言的意思很大程度上取决于词语的排列顺序。但自注意力机制的一个根本性问题:它对位置不敏感!
考虑这两个句子:
对于纯粹的自注意力机制来说,这两个句子是完全一样的,因为:
但我们都知道,这两个句子的意思完全不同!第一个是猫在追老鼠,第二个是老鼠在追猫。
位置编码
(Position Encoding)如何实现?
既然模型看不懂位置,那我们就给每个位置做个标记,就像给每个座位贴上号码一样。位置信息的融入方式非常简单:直接相加。
![Transformers and the Power of Positional Encoding [Transformers Series]](http://mmbiz.qpic.cn/sz_mmbiz_png/7TWRhh4xickkyRL3wicicUTRP4me7bd6Sp6IYb7aCgCa3ctic7UODDnNBwpGxVIzVYyy4wypbjgTLKziadAdDzCcxRA/640?wx_fmt=png&from=appmsg)
这样,即使是同一个词"猫",出现在不同位置时,模型也能区分开:
- 位置1的"猫" = "猫"的意思 + "第1号位置"的信息
- 位置3的"猫" = "猫"的意思 + "第3号位置"的信息
word_embedding = [0.1, 0.5, -0.2, 0.8] position_encoding = [0.0, 0.3, 0.1, -0.1] final_input = word_embedding + position_encoding = [0.1, 0.8, -0.1, 0.7]
Transformer使用了一种很聪明的位置编码方式,叫做"正弦和余弦函数"。
- 不同维度使用不同频率:通过 10000^(i/d_model) 创建频率梯度
def positional_encoding(seq_len, d_model): """ 为每个位置生成独特的编码向量 seq_len: 句子长度 d_model: 向量维度 """ pos_encoding = np.zeros((seq_len, d_model)) for pos in range(seq_len): for i in range(d_model): if i % 2 == 0: pos_encoding[pos, i] = sin(pos / 10000^(i/d_model)) else: pos_encoding[pos, i] = cos(pos / 10000^((i-1)/d_model)) return pos_encoding
这种"多频率 + 正弦余弦交替"的组合设计,让每个位置都获得了独特的高维"指纹"。就像用多个不同精度的尺子同时测量,既能区分毫米级的差异,也能区分米级的差异,从而确保任意两个位置的编码都不会相同。通过数学上的巧妙设计,让每个位置都有了独一无二的"身份证",这个身份证既包含精细信息(高频),又包含粗略信息(低频),正弦余弦则提供了完整的二维坐标描述。







