2014年,一个叫Ian Goodfellow的研究生在酒吧里灵光一现:能不能让两个AI互相较劲,一个专门造假,一个专门打假?这个看似简单的想法,彻底改变了人工智能的历史轨迹。在GAN之前,AI就像一个只会考试的学霸——能识别图片里是猫还是狗,能预测股价涨跌,但从来不会"创作"。GAN的出现,让AI第一次拥有了创造力。传统机器学习的局限是什么?
在GAN出现之前,机器学习本质上是一个判别式模型的世界。判别式模型不关心数据X本身是如何产生的,只关心如何根据X做出正确的判断Y。判别式模型的目标:学习 P(Y|X)P(猫|图像) = 0.8 P(垃圾邮件|邮件内容) = 0.9 P(房价|房屋特征) = 50万
这种模式的核心问题是:AI只能理解和分类现有数据,无法创造新数据。判别式模型基于条件概率,通过最小化训练误差,模型能够自动发现数据中的规律,并将这些规律应用到新的、未见过的数据上。GAN最核心的突破是彻底改变了机器学习的目标——从判别式的"理解数据"转向生成式的"创造数据"。这是AI第一次从"分类现有数据"转向"生成全新数据"。P(Y|X) - 给定输入X,预测输出Y目标:学习决策边界,区分不同类别P(X) - 直接学习数据本身的分布规律目标:理解数据如何产生,进而创造新数据
传统机器学习依赖标注数据和明确的优化目标,GAN创造了全新的自对抗学习范式。它通过两个网络相互对抗,在博弈中自动达到最优状态,无需人类设计复杂的学习规则或提供标准答案。
# 传统生成模型的困境1. 必须显式定义概率分布:P(x) = 某种数学形式2. 计算复杂积分:P(x) = ∫ P(x|z)P(z)dz (通常无解)3. 强分布假设限制了模型表达能力# GAN的突破性解决方案生成器G: Z → X # 神经网络直接映射无需显式概率密度函数通过对抗过程隐式学习任意复杂分布
GAN的对抗训练本质上是一个博弈论中的零和游戏。生成器G试图生成足够逼真的假数据来欺骗判别器D,而判别器D则努力区分真实数据和生成数据。这种对抗关系驱动两个网络在竞争中共同进步。
min_G max_D V(D,G) = E_{x~p_data(x)}[log D(x)] + E_{z~p_z(z)}[log(1-D(G(z)))]
GAN的判别器网络D的设计原理是什么?
判别器D是一个二分类器,接收数据样本并输出该样本为真实数据的概率。判别器的架构通常采用卷积神经网络,通过层次化特征提取来识别生成数据中的伪造痕迹。
- 激活函数:最后一层使用Sigmoid输出0-1概率值
class Discriminator: def forward(self, x): features = self.conv_layers(x) flattened = self.flatten(features) probability = self.classifier(flattened) return probability D_loss = -[log(D(x_real)) + log(1-D(G(z)))]
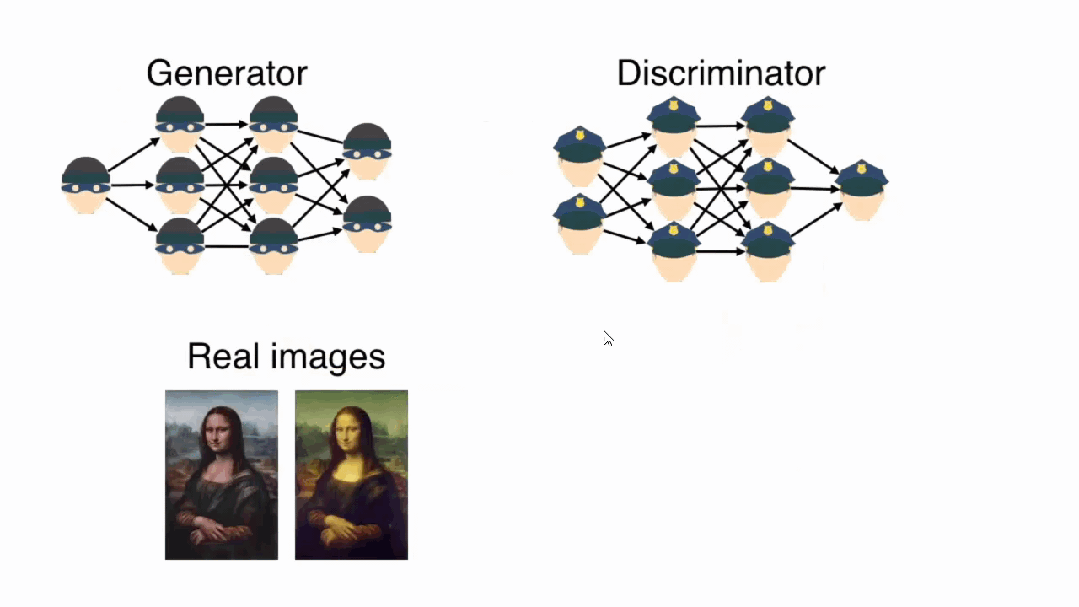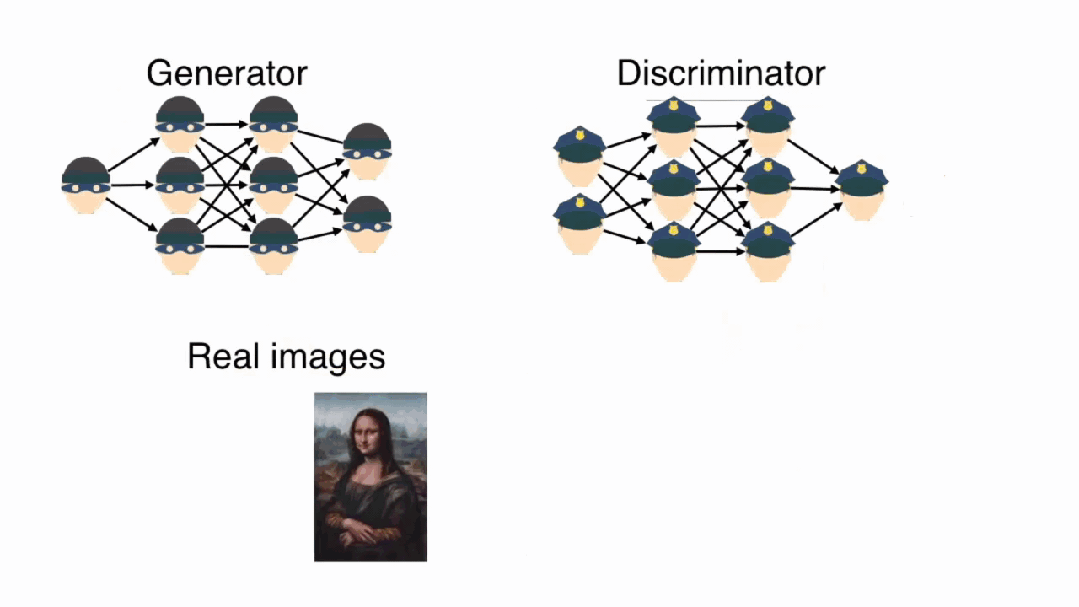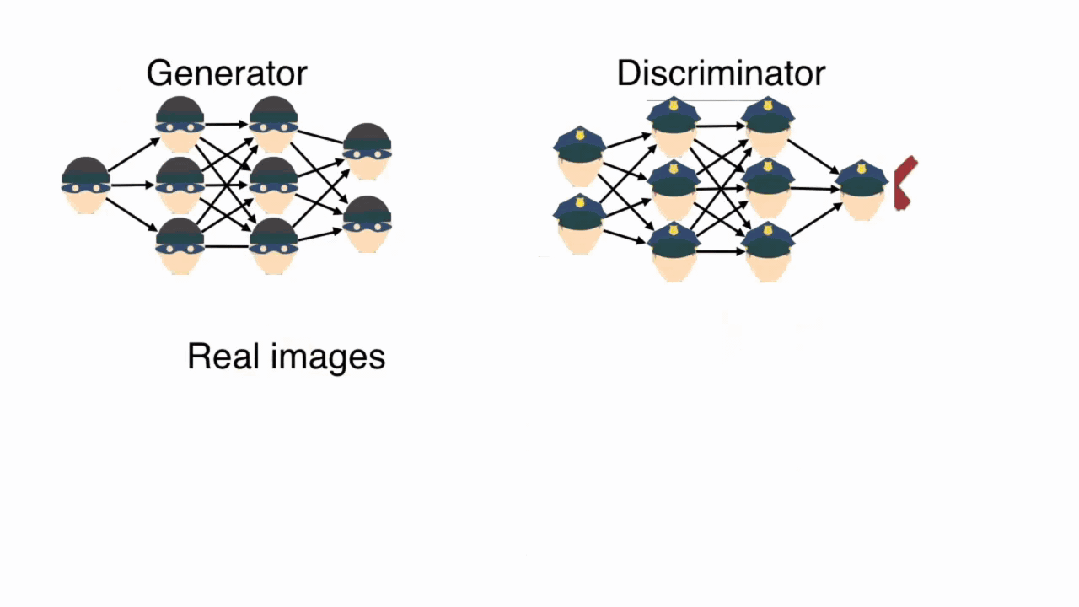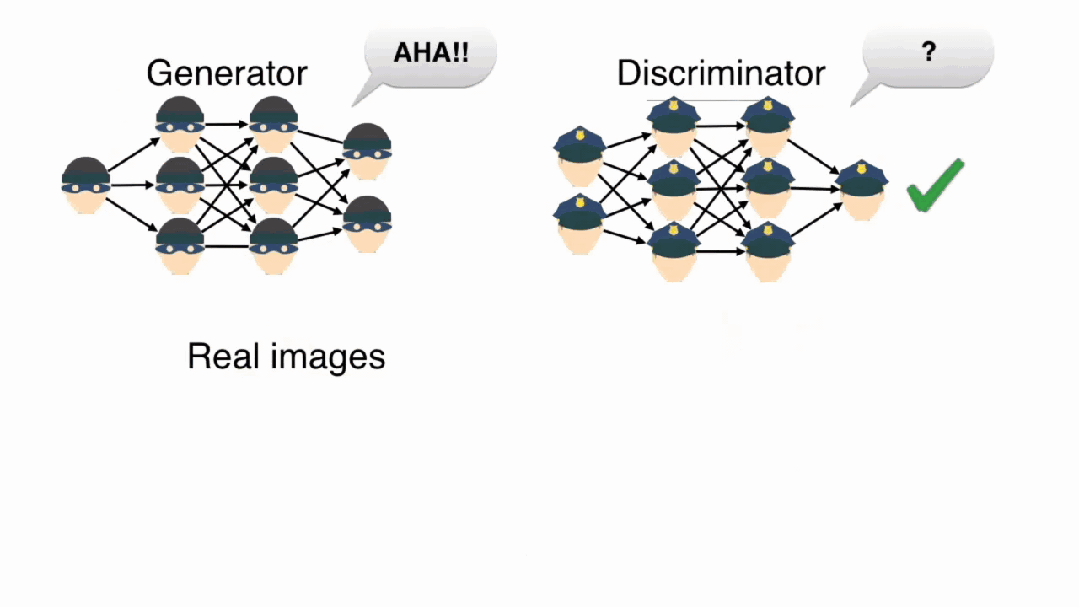
GAN的生成器网络G的设计原理是什么?
生成器G是一个映射网络,将低维随机噪声z映射到高维数据空间。生成器通常采用转置卷积(反卷积)架构,通过上采样操作逐步将噪声向量扩展为完整的数据样本。
- 输入层:接收随机噪声向量(通常100-1000维)
class Generator: def forward(self, z): x = self.dense_layer(z) x = self.reshape(x) x = self.deconv_layers(x) fake_data = self.output_layer(x) return fake_dataG_loss = -log(D(G(z)))










