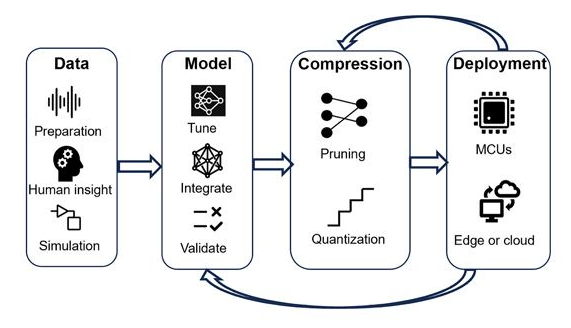
现代深度学习模型在追求高精度的同时,模型规模也在急剧增长。一个训练完成的基线模型(Baseline Model)虽然性能优异,但往往面临以下挑战:(1)存储空间大:动辄几百MB甚至几GB的模型文件模型压缩技术正是为了解决这些问题而生,通过系统性的优化手段,将庞大的基线模型转换为轻量化的压缩模型(Compressed Model),最终实现三大关键目标:更小的模型尺寸(Smaller Size)、更快的推理速度(Faster Inference)、边缘设备部署能力(Deploy to Edge)。剪枝(Pruning)如何移除冗余连接?

剪枝技术基于一个重要发现:神经网络中存在大量对最终预测结果贡献微小的连接。通过识别并移除这些冗余连接,可以在保持模型性能的同时大幅减少参数量。
(1)结构化剪枝:移除整个神经元、通道或层
(2)非结构化剪枝:移除单个权重连接
1. 重要性评估 → 计算每个连接/神经元的重要性分数2. 剪枝策略制定 → 确定剪枝比例和优先级3. 执行剪枝 → 移除低重要性的连接4. 微调恢复 → 通过继续训练补偿性能损失5. 迭代优化 → 重复上述过程直到满足要求
二、量化(Quantization):降低数值精度
量化技术(Quantization)如何降低数值精度?量化技术通过降低模型参数的数值精度来实现压缩。最常见的是将32位浮点数(FP32)转换为8位整数(INT8),在几乎不影响精度的情况下实现4倍的存储压缩和显著的计算加速。
(1)训练后量化(Post-training Quantization, PTQ)
(2)量化感知训练(Quantization-aware Training, QAT)
大模型入门指南 - Quantization:小白也能看懂的“模型量化”全解析
三、知识蒸馏(Knowledge Distillation):师生传承
知识蒸馏(Knowledge Distillation)如何进行师生传承?知识蒸馏采用"教师-学生"模式,让大模型(教师)指导小模型(学生)学习。关键创新在于使用"软标签"而非传统的"硬标签"进行训练。
(1)传统硬标签:[1, 0, 0] - 只告诉模型正确答案
(2)软标签概率:[0.8, 0.15, 0.05] - 还包含类别间的相似性信息
软标签包含了教师模型的"经验知识",帮助学生模型更好地理解数据的内在分布和特征关系。
损失函数 = α × 蒸馏损失(软标签) + (1-α) × 任务损失(硬标签)
通过平衡两种损失,学生模型既能学习真实任务目标,又能继承教师模型的知识经验。
一文搞懂大模型的知识蒸馏(Knowledge Distillation)
虽然每种压缩技术都有其独特优势,但单独使用往往难以达到最佳效果。- 仅知识蒸馏:获得紧凑模型,但可能还有进一步优化空间
根据实践经验,推荐的技术组合顺序为:知识蒸馏 → 剪枝 → 量化。
第一阶段:知识蒸馏
第二阶段:剪枝优化
第三阶段:量化压缩
实际应用案例有哪些?
案例1:移动端图像分类(手机相册自动分类功能)
(1)原始模型:ResNet-50,98MB,95%准确率,150ms推理时间
(2)优化流程:
-
知识蒸馏:ResNet-50→MobileNet-v3,25MB,93%准确率
结构化剪枝:移除30%通道,18MB,92.5%准确率
INT8量化:最终6MB,92%准确率,35ms推理时间
最终效果:
- 推理速度:150ms → 35ms(4.3倍加速)
- 准确率:95% → 92%(3%下降,用户无感知)
案例2:边缘设备语音识别(智能音箱离线语音识别)
(1)原始模型:Transformer语音模型,200MB,延迟300ms
(2)优化策略:
部署效果:
- 响应延迟:300ms → 80ms(3.8倍提升)
- 识别准确率:96% → 94%(2%下降,满足需求)