小红书 AIGC 团队发布了全新的可控人脸生成方法 DynamicFace,在图像与视频人脸交换任务中实现了卓越的质量与一致性。1) 精准控制:基于三维人脸先验引入四种解耦的细粒度条件,实现独立语义控制;2) 高保真:通过 Face Former 与 ReferenceNet 注入身份的高级语义与细节特征;3) 高一致性:引入 FusionTVO 增强视频帧间与背景的稳定性。这些特性共同为定制化图像和视频生成提供了极佳的控制力和灵活性。
论文地址:
https://arxiv.org/abs/2501.08553
项目主页:
https://dynamic-face.github.io/
小红书 AIGC 团队提出基于多条件解耦的视频换脸方法 ,入选 ICCV 2025。
论文标题:
DynamicFace: High-Quality and Consistent Face Swapping for Image and Video using Composable 3D Facial Priors
人脸是 AI 生成视频中最困难也最关键的场景。因为人类对人脸的感知极为敏锐,每一张人脸,都同时承载着表情传递的情绪、姿态展现的动态、轮廓定义的身份、光影塑造的氛围以及背景所处的环境,一个微小的表情变化就能决定情感传达的成败。可控,才可用, 对于人脸生成这一高度敏感的领域,如果缺乏精准的可控性,AI 就无法成为创作者手中稳定可靠的工具,其价值也将大打折扣。
视频人脸交换的核心难题在于,如何在保留源人脸全部身份特征的同时,精准复现目标视频中的每一个细微表情与动态,确保情感表达的真实与连贯。尽管现有换脸方法已取得一定进展,但它们往往无法完美剥离参考人脸和目标人脸的特征,导致关键的表情细节失真或身份信息被“污染”,最终效果难以满足创作者对真实感和情感传递的苛刻要求。这通常表现为以下三大挑战:
1)空间与时间建模的内在矛盾:许多聚焦于身份一致性的图像生成模型在空间特征提取方面已足够优越,然而由于在注入运动信息时耦合了目标身份特征,进而导致运动信息不准确,一旦需要建模时间变化的视频扩散模型时,单图的不准确运动建模会被放大,最终陷入身份还原能力和运动一致难以两全的问题。
2)身份一致性降低:在复杂或大幅度动作变化情况下,面部区域极易出现形变、失真,难以保证人物独特的面貌特征能随时保留。这种问题直接影响动画人物的个体识别度和可信度,也是用户接受数字人像动画的首要阻碍。
3)整体视频质量受损:当前最优秀的人像动画生成模型虽然在动画效果层面取得进展,但往往还需借助外部换脸后处理工具以改善关键帧细节。可惜,这类后处理虽能暂时修复细节,却往往损伤了整段视频在视觉上的统一性和自然度,导致画面出现割裂感和不连贯的现象。
本研究提出了一种创新性的人脸置换方法 DynamicFace,针对图像及视频领域的人脸融合任务实现了高质量与高度一致性的置换效果。与传统人脸置换方法相比,DynamicFace 独创性地将扩散模型(Diffusion Model)与可组合的 3D 人脸先验进行深度融合,针对人脸运动与身份信息进行了精细化解耦以生成更一致的人脸图像和视频。
针对现有方法在身份与运动表征中普遍存在的耦合冗余问题,Dynamicface 提出将人脸条件显式分解为身份、姿态、表情、光照及背景五个独立的表征,并基于 3DMM 重建模型获取对应参数。
具体而言,利用源图像提取身份形状参数 α,目标视频逐帧提取姿态 β 与表情 θ,随后渲染生成形状–姿态法线图,减少目标人脸身份泄露,最大程度保留源身份;表情信息仅保留眉毛、眼球及口唇区域的运动先验,避免引入目标身份特征;光照条件由 UV 纹理图经模糊处理得到,仅保留低频光照分量;背景条件采用遮挡感知掩码与随机位移策略,实现训练–推理阶段的目标脸型对齐。四条条件并行输入 Mixture-of-Guiders,每组由3×3 卷积与零卷积末端构成,在注入网络前经过 FusionNet 融合四条条件的特征后注入到扩散模型中,可在保持 Stable Diffusion 预训练先验的同时实现精准控制。
为实现高保真身份保持,DynamicFace 设计了双流并行注入架构。高层身份流由 Face Former 完成:首先利用 ArcFace 提取 512 维 ID Embedding,再通过可学习 Query Token 与 U-Net 各层 Cross-Attention 交互,确保全局身份一致性;细节纹理流由 ReferenceNet 实现,该网络为 U-Net 的可训练副本,将 512×512 源图潜变量经 Spatial-Attention 注入主网络,实现细粒度的纹理迁移。
针对时序一致性问题,DynamicFace 会在训练中插入时序注意力层来优化帧间稳定性,但时序层在处理长视频生成时会出现帧间跳动的现象。为此,我们提出了 FusionTVO,将视频序列划分为若干段,并为每段设置融合权重,在相邻段的重叠区域实行加权融合;并在潜变量空间引入总变差(Total Variation)约束,抑制帧与帧之间的不必要波动;对于人脸之外的背景区域,在每一步去噪迭代过程中采用目标图像中的背景潜变量空间进行替换,维持了场景的高保真度。
为全面评估 DynamicFace 的性能,研究团队在 FaceForensics++(FF++)和 FFHQ 数据集上进行系统性的定量实验,并与当前最具代表性的 6 种换脸方法进行对比,包括 Deepfakes、FaceShifter、MegaFS、SimSwap、DiffSwap 以及 Face Adapter。实验遵循先前论文的参数设置:从每个测试视频中随机抽取 10 帧作为评估样本,并另取连续 60 帧用于视频级指标计算。所有方法均使用官方开源权重或公开推理脚本,在输入分辨率(512×512)下复现结果。定量结果如表中所示:DynamicFace 同时在身份一致性(ID Retrieval)和运动一致性 (Mouth&Eye Consistency) 达到了最优的结果。整体而言,实验结果充分证明了 DynamicFace 在身份保真与运动还原方面的综合优势,验证了其在高质量人脸可控生成中的卓越性能。
从下面的图像和视频对比结果可以得出,DynamicFace 很好地保存了身份(例如,形状和面部纹理信息)和动作(包括表情和姿势等)信息,并且生成结果维持了更好的背景一致性。具体来说,基于 GAN 的方法往往会生成较为模糊、视觉上并不真实且身份一致性较差的结果,但可以维持不错的运动一致性;其他基于扩散模型的方法能生成分辨率更高且更真实的结果,但运动一致性保持较差(如表情不一致,眼神朝向不同等)。DynamicFace 通过精细化解耦的条件注入可以保证更优的表情一致、眼神一致和姿势一致性。

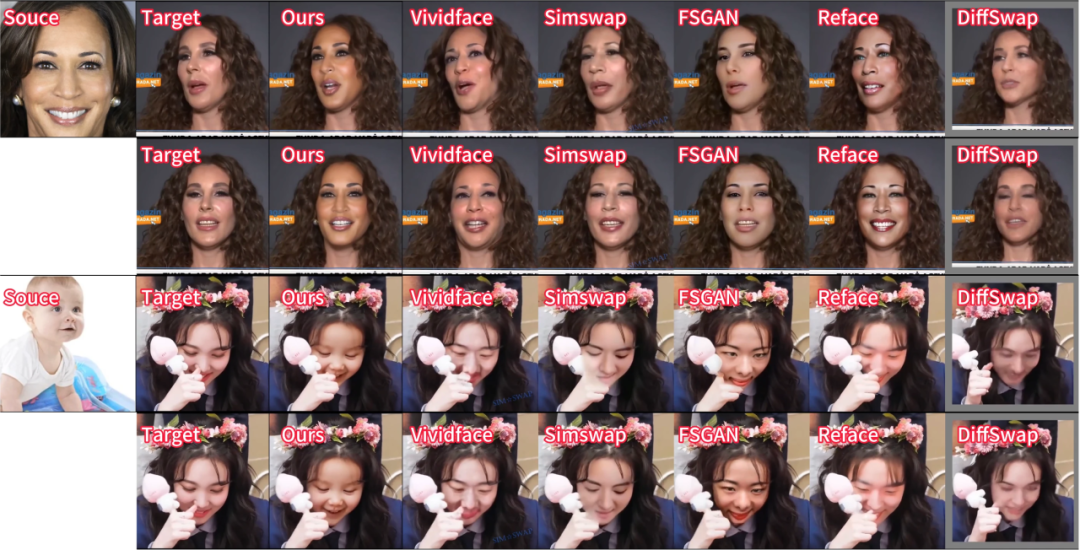
研究团队还进行了充分的消融实验,深入探究模型各个组成部分的具体作用。
为验证 DynamicFace 中四种人脸条件的必要性与互补性,本文在 FF++ 测试集上执行了全面的消融实验。具体设置如下:以完整模型为基线,依次去除背景、表情、光照、形状-姿态法线图四类条件中的某一类,并保持其余模块与训练策略完全一致。图像级评价沿用 ID 检索、姿态误差、表情误差、嘴部误差、眼部误差五项指标;主观可视化结果如图所示。综合而言,四类条件各司其职:背景保证环境一致性,表情条件锁定微动作,光照条件维持光影和谐,形状-姿态法线图确保几何保真。任何一项缺失都会在对应指标或主观质量上出现可观测的退化,从而验证了 DynamicFace 条件设计的完备性与必要性。
为验证时序一致性模块的必要性,本文在保持四类空间条件不变的前提下,探究了motion module和 FusionTVO 的必要性,可以从客观指标得出,两个模块均对帧间一致性和视频质量有明显提升。
我们也对两个人脸身份注入模块进行了进一步的消融实验,可以从表中看到在同时加入 FaceFormer 和 ReferencerNet 后可以显著提升源参考人脸的身份注入性能。
3.3 更多生成结果展示
我们也展示了一些其他的应用示例,DynamicFace 可以对身份保持和人体驱动等生成结果进行后处理,显著提升生成结果的人脸ID一致性和表情控制,更多效果展示可以在论文和项目主页中(https://dynamic-face.github.io/ )进行查看。
DynamicFace 提出一种基于扩散模型的视频人脸交换框架,通过可组合 3D 面部先验将身份、表情、姿态、光照与背景显式解耦,利用轻量级 Mixture-of-Guiders 进行并行条件注入;同时设计身份-细节双流注入模块(Face Former + ReferenceNet)确保高保真身份保持,再辅以 FusionTVO 实现更好的帧间一致和背景一致性。在 FF++ 数据集的定量与消融实验中,DynamicFace 在身份一致性和运动一致性及视频一致性指标上均优于现有 SOTA,验证了其高保真、强可控与易扩展的特性。期望这种精细化解耦条件注入的方法能为可控生成的后续工作提供新思路。
Core Contributors
王润奇
小红书 AIGC 团队算法工程师,在 ICCV、ACM MM 等计算机视觉、多媒体顶会发表多篇论文,曾多次获得天池、顶会 Challenge 冠亚季军,主要研究方向为扩散模型、可控图像生成和视频生成等。
陈杨
小红书 AIGC 团队算法工程师,在图像领域顶会 CVPR 上发表两篇一作论文,现负责 AIGC 生成类算法的研究与落地,曾经负责站内主体分割模型的开发。
许思杰
小红书 AIGC 团队算法工程师,在 ACM MM、ICCV 等计算机视觉、多媒体顶会发表多篇论文。主要研究方向为视频 AIGC 的可控生成&视频风格化任务,近期研究领域为基于多模态大模型的智能剪辑。
朱威
小红书 AIGC 团队算法工程师,主攻图像视频AIGC可控生成和风格化,近期聚焦基于多模态大模型的长文和人像生成。
秦明
小红书社区智创 AIGC 方向负责人。在计算机视觉领域顶会发表多篇论文,曾获 ICCV VOT 世界冠军,多次刷新 MOT 国际榜单世界记录。在创作领域,专注于视频自动化剪辑、图像/视频可控生成、个性化生成等方向的算法研究与落地工作。
多模态算法工程师AIGC方向-创作发布
工作职责
1.负责文生图(Text-to-Image)生成算法的研发与优化,包括中文场景下图像生成质量提升、多模态对齐、可控性生成等方向;
2. 图文融合的排版生成技术研发,构建和优化多模态联合训练模型,实现自动化、智能化的视觉内容布局生成(如杂志、UI 界面等);
3. 结合各业务场景下相关技术问题进行分析、算法设计,推动算法在工业级场景的部署与应用,沉淀在业界有影响力工作;
任职资格
1. 计算机、数学、自动化、控制等相关专业;
2. 扎实的数学和算法基础:概率统计、数值优化等算法;
3. 扎实的编程基础:熟悉 Pytorch、TensorFlow、MXNet 等其中的一种或以上;
4. 了解前沿的 Diffusion、LLM、VLLM 算法,包括不限于 StableDiffusion、Flux、Llama、QwenVL 等;
5. 关注多模态生成领域的业界最新动态,如 Midjourney、Runway、Recraft、可灵、即梦等;
6. 在 CVPR、ICCV、ECCV、NeurIPS、ICML、ICLR、AAAI、ACL、EMNLP 等顶级学术会议上发表论文者优先。
7. 有图文排版预估生成、中文场景文生图相关经验优先。











